The Kubernetes community is giving up on Ingress and will reinvent traffic routing to scale better with multiple teams and roles.
Kubernetes 1.19 and the Ingress Resource
In Kubernetes 1.19 the Ingress resource, which defines how HTTP traffic enters and is routed in Kubernetes, was upgraded from beta to GA. While the Ingress resource was in beta status, some activity was seen in Kubernetes 1.18 where hostname wildcards were introduced. My take on this is that future development of traffic ingress and routing in Kubernetes will happen using other resource types. The activity we saw in Kubernetes 1.18, and the upgrade of Ingress to GA/v1 in 1.19, can be viewed as implementing the most urgent issues before settling on the design of the Ingress resource.
From our partners:
A fixed revision resource will only receive bug-fixes and backward compatible modifications, so it’s unlikely that we will see major changes to the Ingress resource in the future. The extended time spent in beta status, mixed with the wide usage of the Ingress resource, also means that it had been in defacto-GA status for a long time and could not be significantly evolved without breaking backward compatibility. We could call this fix, (forget) and look forward – lock down the design, only solve bugs going forward, and create new resource types for an evolved design.
The problem with the Ingress resource is that the design is not really ‘evolvable’ without major diversion from the current design. This means that if we want to innovate and thus change the Ingress resource significantly, we will need to create a new resource type. This is also evident from the work ongoing around Kubernetes service APIs SIG and e.g. the Gateway API.
So, what are the major problems with the Ingress resource and what model should we expect from a version 2 of the Ingress resource type? Well, read on…
Kubernetes Ingress Resource
The Ingress resource in Kubernetes is the official way to expose HTTP-based services. The Ingress resource has lived an uncertain life as a beta resource for the past 18 Kubernetes versions – yes, since Kubernetes v1.1! The long time as a beta API, and the proliferation of Ingress-controller-specific annotations used to extend and modify the behaviour of the Ingress resource, serves to illustrate that the Ingress resource is not as well designed as other Kubernetes resources. In the following section we will describe the scaling problem of the Ingress resource and a way to solve it.
Separate roles
One problem with the Ingress resource is that it combines the following into one resource definition:
- Identity – the domain name
- Authentication – the TLS certificate
- Routing – which URL paths are routed to which Kubernetes services
If a person is managing a somewhat complicated site, i.e. one with components managed by multiple independent teams, we ideally want to delegate the above issues to separate roles. For example:
- Security/infrastructure admin – manages domain names and TLS certificates
- Site admin – manages routing to components/applications managed by individual teams
- Application teams – manages routing to different application versions, canaries, blue/green versions, etc.
Imagine we have a site, <em>example.com</em>, made up of two components, login and mainsite, each managed by a separate team. We can illustrate the different roles and traffic routing as shown in the following figure. Blue boxes illustrate a role and the red boxes illustrate a traffic routing definition. Routing definitions use either an URL path or a HTTP header as selector.
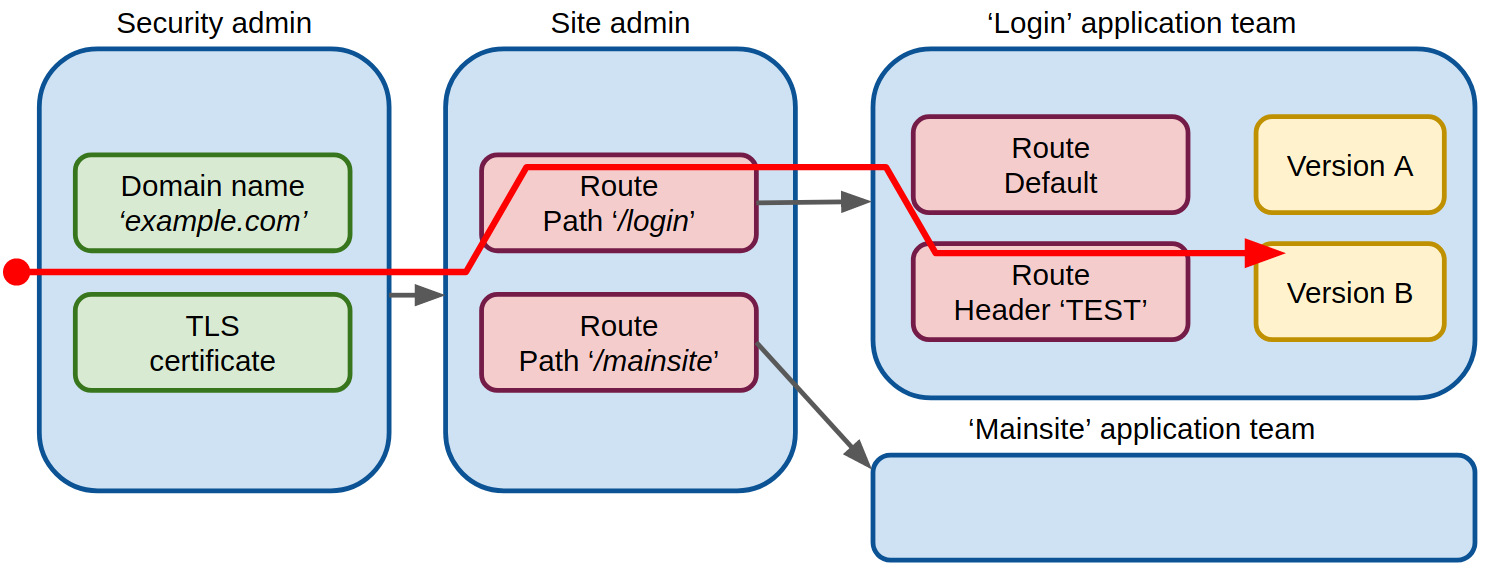
Here the ‘Security admin’ role manages the site identity through the domain name and TLS certificates (and potentially also DNS, which is outside the scope of this description). The domain name and TLS certificate change only rarely, and access to this role should be very restricted. If certificates are managed with Lets Encrypt, limited access also means that site administrators or application teams cannot trigger certificate renewals. This reduces the possibility of hitting the Lets Encrypt certificate rate-limit, i.e. there’s no risk of failing to obtain a TLS certificate due to the rate-limit.
The ‘site-admin’ role defines top-level routing, e.g. routing to the two applications managed by our two teams. This routing will only change when we add or remove applications from our site.
The ‘application teams’ manage the sub-components of each application, including test deployments. Each application team can define routing to e.g. test instances to implement canary, blue/green testing, etc.
In Kubernetes, the Ingress resource defines the domain name, TLS certificate, and routing to Kubernetes services in a single object. The consequence here is that an application team wanting to do e.g. canary testing will need access to modify the global Ingress resource for the whole site. This has both security and stability implications – the most obvious being that introducing a syntax error in the Ingress resource will render the whole site inaccessible.
The work of the Kubernetes API SIG on the Gateway API is intended to support this multi-role setup. While implementations of the gateway API do not yet exist, the API is very much inspired by the API of the Contour ingress controller. In the following sections we will show you how to implement this multi-role setup with Contour to get an idea of the potential future gateway API in Kubernetes.
Implementing a multi-role setup with Contour and Envoy
Envoy is a Cloud Native Computing Foundation (CNCF) graduated proxy and Contour is an Ingress controller built on top of Envoy. Contour extends the idea of Ingress resources with a HTTPProxy object that allows for the delegation of one HTTPProxy object to another. In other words, it allows us to define traffic routing using multiple HTTPProxy resources in multiple Kubernetes namespaces, with access to namespaces limited by different roles. This is illustrated below.
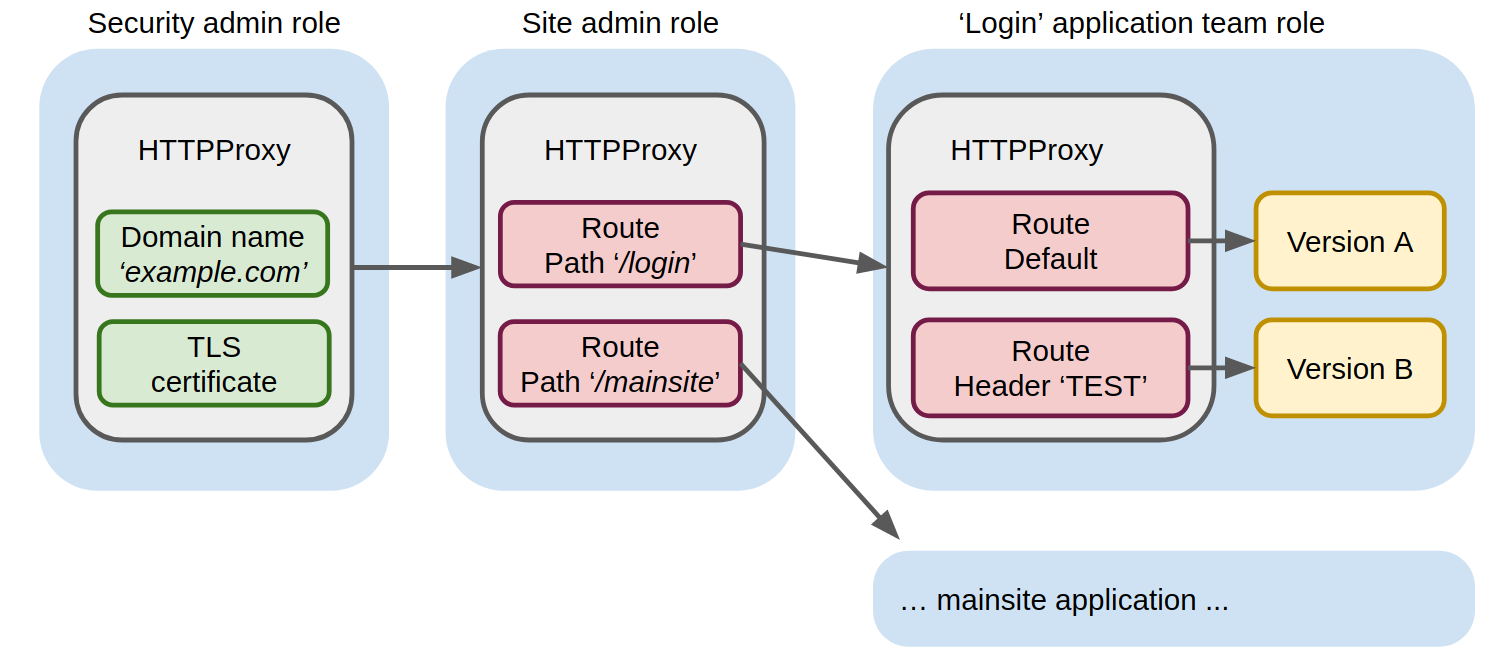
A writeup about Kubernetes is not complete without some YAML, so lets see the YAML for the above implementation. First the top-level HTTPProxy defining the site identity:
apiVersion: projectcontour.io/v1
kind: HTTPProxy
metadata:
name: example-com-root
namespace: security-admin-only
spec:
virtualhost:
fqdn: example.com
tls:
secretName: example-com-cert
includes:
- name: site-fanout
namespace: site-admin-only
The example-com-root HTTPProxy resource in the security-admin-only namespace defines the site identity through the domain name and TLS certificate and delegates further routing to the site-fanout HTTPProxy resource in the site-admin-only namespace:
apiVersion: projectcontour.io/v1
kind: HTTPProxy
metadata:
name: site-fanout
namespace: site-admin-only
spec:
includes:
- name: login
namespace: login
conditions:
- prefix: /login
- name: mainsite
namespace: mainsite
conditions:
- prefix: /mainsite
The site-fanout HTTPProxy resource defines routing of anything under the /login path to the HTTPProxy resource login in the login namespace. The team managing the login application have full access to the login namespace and can thus create the following HTTPProxy resource to route to Kubernetes services which they also control:
apiVersion: projectcontour.io/v1
kind: HTTPProxy
metadata:
name: login
namespace: login
spec:
routes:
- conditions:
- header:
name: x-test
contains: true
services:
- name: test-login-app-service
port: 80
- services:
- name: login-app-service
port: 80
The login HTTPProxy resource defines routing to the test-login-app-service Kubernetes service when the x-test HTTP header contains true (e.g. a blue/green test) and routing to the login-app-service Kubernetes service otherwise.
Rego and Conftest
Obviously, the namespaces shown above should be locked down with Kubernetes RBAC e.g. the ‘login’ team can only create HTTPProxy resources within their login namespace. However, you might wonder how to restrict creation of root HTTPProxy resources like the example-com-root above to the security-admin-only namespace.
Restricting creation of such resources is possible by using OPA GateKeeper. GateKeeper is a Kubernetes admission controller that accepts policies defined using the Rego language. I have created an example of a Rego-based test that will test for root HTTPProxy resources. The test is part of a suite of tests useful for GitOps CI, e.g. when you want to validate your Kubernetes resources prior to deploying them to Kubernetes.
When will we see a new ingress resource in Kubernetes?
Most likely – never.
The trend in Kubernetes is that extension happens with CRDs (custom resource definitions) – a dynamic approach where extensions are introduced outside of the core of Kubernetes. This means that projects like Contour or Istio will introduce their own CRDs that allow us to define traffic Ingress and routing. For these reasons a new common Ingress definition is unlikely to be introduced to the core of Kubernetes.
Book a public or on-site Kubernetes training for your team: https://hubs.ly/H0y0qgv0
Guest post originally published on eficode’s blog by Michael Vittrup Larsen, Consultant at eficode
Source https://www.cncf.io/blog/2020/10/29/kubernetes-1-19-the-future-of-traffic-ingress-and-routing/
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!