
We’re very excited to announce the general availability of the Ruby Active Record Adapter for Google Cloud Spanner. Ruby Active Record is a powerful Object-Relational Mapping(ORM) library bundled with Ruby on Rails. Active Record provides an abstraction over the underlying database, and includes capabilities such as automatically generating schema changes and managing schema version history.
Even though Active Record is commonly used with a Rails project, it can be used with other frameworks like Sinatra or as a standalone library in your Ruby application. With the GA of the adapter, Ruby applications can now take advantage of Cloud Spanner’s high availability and external consistency at scale through an ORM.
From our partners:
The adapter is released as the Ruby gem ruby-spanner-activerecord. Currently, it supports:
- ActiveRecord 6.0.x with Ruby 2.6 and 2.7.
- ActiveRecord 6.1.x with Ruby 2.6 and higher.
In this post, we will cover how to start with the adapter with a Rails application and highlight the supported features.
Installation
To use Active Record with a Cloud Spanner database, you need an active Google Cloud project with the Cloud Spanner API enabled. For more details on getting started with Cloud Spanner, see the Cloud Spanner getting started guide.
You can use your existing Cloud Spanner instance in the project. If you don’t already have one, or want to start from scratch for a new Ruby application, you can create a Cloud Spanner instance using the Google Cloud SDK, for example:
gcloud spanner instances create test-instance --config=regional-us-central1 --description="Ruby Demo Instance" --nodes=1
To install the adaptor, edit the `Gemfile` of your Rails application and add the activerecord-spanner-adapter gem:
gem 'activerecord-spanner-adapter'
Next, run bundle to install the gem:
bundle install
Adapter configuration
In a Rails app, you need to configure the database adapter by setting the Spanner project, instance, and database names. Since Cloud Spanner uses Cloud Identity and Access Management to control user and group access to its resources, you can use a Cloud Service Account with proper permissions to access the databases. The configuration changes can be made in the config/database.yml file for a Rails project.
To run your code locally during development and testing for a Cloud Spanner database, you can authenticate with Application Default Credentials, or set the GOOGLE_APPLICATION_CREDENTIALS environment variable to authenticate using a service account. This adapter delegates authentication to the Cloud Spanner Ruby client library. If you’re already using this or another client library successfully, you shouldn’t have to do anything new to authenticate from your Ruby application. For more information, see the client library’s documentation on setting up authentication.
Besides using a database in the Cloud, you can also use Google’s Cloud Spanner Emulator. The acceptance tests for the adapter run against the emulator. If needed, you can use the configuration in the Rakefile as an example.
In the example below, a service account key is used for the development environment. For the production environment, the application uses the application default credential.
default: &defaultadapter: "spanner"pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 10 } %>project: [PROJECT_ID]instance: test-instancedevelopment:<<: *defaultdatabase: blog_devcredentials: activerecord-spanner-key.jsonproduction:<<: *defaultdatabase: blog
Working with the Spanner Adapter
Once you have configured the adapter, you can use the standard Rails tooling to create and manage databases. Following the Rails tutorial in the adapter repository, you’ll see how the client interacts with the Cloud Spanner API.
Create a database with tables
First, you can create a database by running the following command:
bin/rails db:create
Next, you can generate a data model, for example:
bin/rails generate model Article title:string body:text
The command above will generate a database migration file as the following:
class CreateArticles < ActiveRecord::Migration[6.1]def changecreate_table :articles do |t|t.string :titlet.text :bodyt.timestampsendendend
Active Record provides a powerful schema version control system known as migrations. Each migration describes a change to an Active Record data model that results in a schema change. Active Record tracks migrations in an internal `schema_migrations` table, and includes tools for migrating data between schema versions and generating migrations automatically from an app’s models.
If you run migration with the file above, it will indeed create an `articles` table with two columns, `title` and `body’:
bin/rails db:migrate== 20210803025742 CreateArticles: migrating ===================================-- create_table(:articles)-> 23.5728s== 20210803025742 CreateArticles: migrated (23.5729s) =========================
After migration completes, you can see the tables Active Record created in the GCP Cloud Spanner Console:
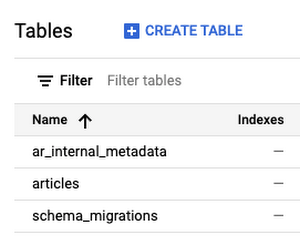
Alternatively, you can inspect `information_schema.tables` to display the tables Ruby created using the Google Cloud SDK:
gcloud spanner databases execute-sql blog_dev --instance test-instance --sql "select TABLE_NAME, TABLE_TYPE, SPANNER_STATE from information_schema.tables"TABLE_NAME: ar_internal_metadataTABLE_TYPE: BASE TABLESPANNER_STATE: COMMITTEDTABLE_NAME: articlesTABLE_TYPE: BASE TABLESPANNER_STATE: COMMITTEDTABLE_NAME: schema_migrationsTABLE_TYPE: BASE TABLESPANNER_STATE: COMMITTED...
Interact with the database using Rails
After the database and tables are created, you can interact with them from your code or use the Rails CLI. To start with the CLI, you
bin/rails console
This command will start a command prompt and you can run Ruby code within it. For example, to query the `articles` table:
irb(main):001:0> Article.allArticle Load (41.8ms) SELECT `articles`.* FROM `articles` /* loading for inspect */ LIMIT @p1=> #<ActiveRecord::Relation []>
You can see a `SELECT` SQL query runs under the hood. As expected, no record is returned since the table is still empty.
At the prompt, you can initialize a new `Article` object and save the object to the database:
irb(main):002:0> article = Article.new(title: "Hello Rails", body: "I am on Rails!")=> #<Article id: nil, title: "Hello Rails", body: "I am on Rails!", created_at: nil, updated_at: nil>irb(main):003:0> article.saveSQL (65.6ms) BEGINArticle Create (46.7ms) INSERT INTO `articles` (`title`, `body`, `created_at`, `updated_at`, `id`) VALUES (@p1, @p2, @p3, @p4, @p5)SQL (39.5ms) COMMIT=> true
You can see the adapter creates a SQL query to start a transaction and insert a new record into the database table.
If you review the object, you can see the field `id`, `created_at`, and `updated_at` have been set:
irb(main):004:0> article=> #<Article id: 1305753082206646533, title: "Hello Rails", body: "I am on Rails!", created_at: "2021-11-08 15:31:23.631114797 +0000", updated_at: "2021-11-08 15:31:23.631114797 +0000">
You can also modify existing records in the database. For example, you can change the `article` body to something else and save the change:
irb(main):005:0> article.body = 'Rails project is awesome!'=> "Rails project is awesome!"irb(main):006:0> article.saveSQL (27.4ms) BEGINArticle Update (25.4ms) UPDATE `articles` SET `body` = @p1, `updated_at` = @p2 WHERE `articles`.`id` = @p3SQL (8.3ms) COMMIT=> true
This code results in an `UPDATE` SQL statement to change the value in the database. You can verify the result from the Spanner console under the `Data` page:
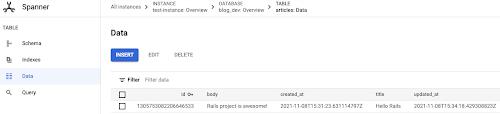
The adapter supports the Active Record Query Interface to retrieve data from the database. For example, you can query by the `title` or `id` using the following code. Both generate corresponding SQL statements to get the data back:
irb(main):002:0> Article.find_by title: "Hello Rails"Article Load (17.0ms) SELECT `articles`.* FROM `articles` WHERE `articles`.`title` = @p1 LIMIT @p2=> #<Article id: 1305753082206646533, title: "Hello Rails", body: "Rails project is awesome!", created_at: "2021-11-08 15:31:23.631114797 +0000", updated_at: "2021-11-08 15:34:18.429308823 +0000">irb(main):003:0> Article.find(1305753082206646533)Article Load (133.5ms) SELECT `articles`.* FROM `articles` WHERE `articles`.`id` = @p1 LIMIT @p2=> #<Article id: 1305753082206646533, title: "Hello Rails", body: "Rails project is awesome!", created_at: "2021-11-08 15:31:23.631114797 +0000", updated_at: "2021-11-08 15:34:18.429308823 +0000">
Migrating an Existing Database
The Cloud Spanner Active Record adapter also supports migrations for existing databases.
For instance, if you want to add two new columns to an existing table, you can create a migration file using the `rails generate migration` command:
bin/rails generate migration AddCommentAndRateToArticles comment:text rating:integerRunning via Spring preloader in process 1274invoke active_recordcreate db/migrate/20211108173214_add_comment_and_rate_to_articles.rb
The command will produce a migration file like the following one:
class AddCommentAndRateToArticles < ActiveRecord::Migration[6.1]def changeadd_column :articles, :comment, :textadd_column :articles, :rating, :integerendend
Finally, you can run the `rails db:migrate` command to commit the schema change:
bin/rails db:migrate== 20211108173214 AddCommentAndRateToArticles: migrating ======================-- add_column(:articles, :comment, :text)-> 23.2915s-- add_column(:articles, :rating, :integer)-> 23.1812s== 20211108173214 AddCommentAndRateToArticles: migrated (46.4730s) ============
Again, you could verify the change from the Spanner console:
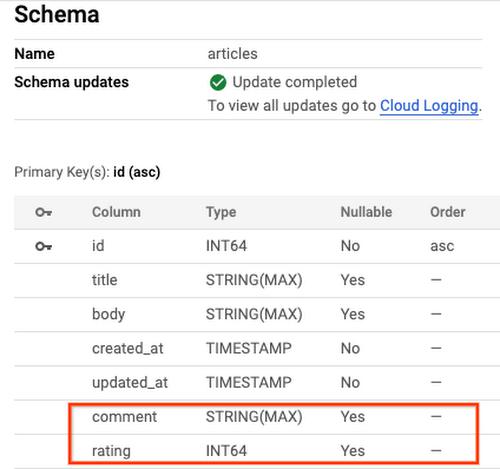
If you want to rollback the migration, you can run `rails db:rollback`. For more details about migration, you can read the Active Record Migrations doc. We also recommend you review the Spanner schema update documentation before you implement any migration.
Notable Features
Transaction support
Sometimes when you need to read and update the database, you want to group multiple statements in a single transaction. For those types of use cases, you can manually control the read/write transactions following this example.
If you need to execute multiple consistent reads and no write operations, it is preferable to use a read-only transaction, as shown in this example.
Commit timestamps
Commit timestamp columns can be configured during model creation using the `:commit_timestamp` symbol, as shown in this example. The commit timestamps can be read after an insert and/or an update transaction is completed.
Mutations
Depending on the transaction type, the adapter automatically chooses between mutations and DML for executing updates. For efficiency, it uses mutations instead of DML where possible. If you want to know how to use the `:buffered_mutations` isolation level to instruct the adapter to use mutations explicitly, you can read this example.
Query hints
Cloud Spanner supports various statement hints and table hints, which are also supported by the adapter. This example shows how to use the `optimizer_hints` method to specify statement and table hints. You can also find a join hint in the example, which cannot use the method but a join string instead.
Stale reads
Cloud Spanner provides two read types. By default, all read-only transactions will default to performing strong reads. You can opt into performing a stale read when querying data by using an explicit timestamp bound as shown in this example.
Generated columns
Cloud Spanner supports generated columns, which can be configured in the migration classes using the `as` keyword. This example shows how a generated column is used, and the `as` keyword is used in the class.
Limitations
The adapter has a few limitations. For example, it doesn’t auto-generate values for primary keys due to Cloud Spanner not supporting sequences, identity columns, or other value generators in the database. If your table does not contain a natural primary key, a good practice is to use a client-side UUID generator for a primary key.
We recommend that you go through the list of limitations before deploying any projects using this adapter. These limitations are documented here.
Customers using the Cloud Spanner Emulator may see different behavior than the Cloud Spanner service. For instance, the emulator doesn’t support concurrent transactions. See the Cloud Spanner Emulator documentation for a list of limitations and differences from the Cloud Spanner service.
Getting involved
We’d love to hear from you, especially if you’re a Rails user considering Cloud Spanner or an existing Cloud Spanner customer who is considering using Ruby for new projects. The project is open-source, and you can comment, report bugs, and open pull requests on Github.
We would like to thank Knut Olav Løite and Jiren Patel for their work on this project.
See also
Before you get started, you need to have a Rails project. For a complete example, you can find it in the gem’s GitHub repo or
By: Xiang Shen (Solutions Architect)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







