Kubernetes is a portable, extensible, open-source cluster manager for managing containerized workloads and services. The features of Kubernetes include automatic software deployment, orchestration, automatic scaling, and management of virtualized resources used by the services. Kubernetes also include a scheduler to distribute tasks evenly among worker nodes.
This blog is going to focus on the scheduler component in the Kubernetes Cluster Management. Further, we are going to zoom in how we can customize the Scheduler to address some specific use cases.
From our partners:
Let’s first have a quick refresher of the Kubernetes cluster manager.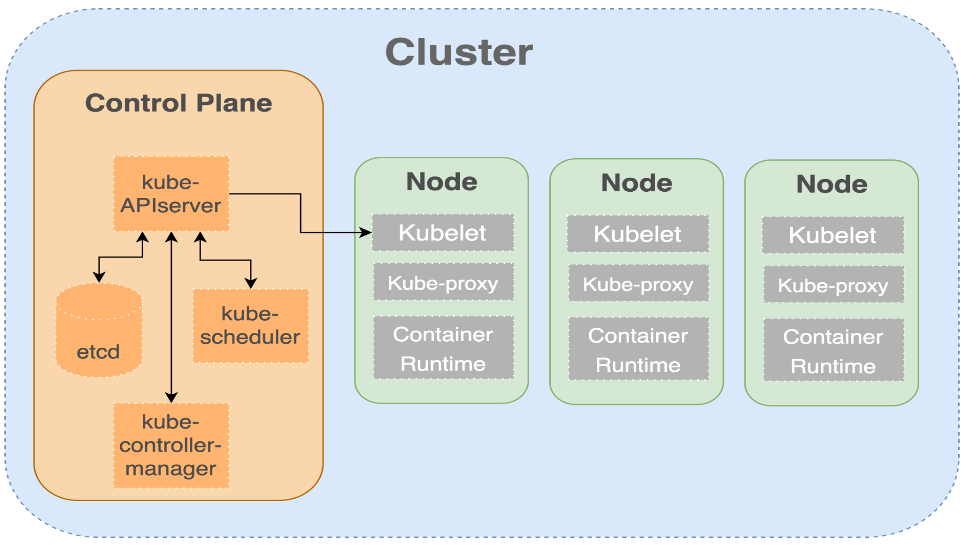 Figure 1. Kubernetes Cluster System Structure
Figure 1. Kubernetes Cluster System Structure
Figure 1 depicts the standard structure of a Kubernetes cluster. Kubernetes is a distributed management system, it contains at least one Master Node (Control Plane), and multiple worker nodes. The master node contains the following components:
- API server — responsible for the communication with Kubelet on the worker nodes. API server is also responsible for the authentication and check for the authorization of the requestor.
- Etcd — this is the key-value store of the critical state of the system. Etcd is responsible for snapshotting the status of the Kubernets cluster.
- Controller manager — responsible for monitoring the shared state of the cluster through the apiserver and makes changes attempting to move the current state towards the desired state. Examples of controllers that ship with Kubernetes include the replication controller, endpoints controller, namespace controller, and service accounts controller.
- Kube Scheduler — The Kube Scheduler is responsible for selecting the worker node for a POD, and provision the POD on the target node according to its resource specifications.
The worker node is where the containers (PODs) are scheduled to run. It contains the Kubelet, the Kube-proxy, as well as the actual Container Runtime Library. This blog we will not go into the details of the worker node components. Please refer to Reference #1 for details.
Role of Kube scheduler in K8S cluster management
The Kube scheduler is a control plane process which assigns Pods to worker nodes. The scheduler determines which Nodes are valid placements for each Pod in the scheduler queue according to its constraints and available resources. The scheduler then ranks each valid Node and binds the Pod to a target Node. The kube scheduler is designed so that, if you want and need to, you can write your own scheduling component and use that instead.
Kube Scheduler control flow
The Kube Scheduler runs as a process daemon on the Master node. It monitors the status and resource utilization of all worker nodes. Upon a user’s request to create a POD, the scheduler finds a node among the workers that best fits its Resource Specification through a Filtering and a Scoring mechanism. The scheduler then tells the API server to bind the POD to the target node.
The Kubelet on the target node will listen to the API server. Upon the bind request, kubelet will retrieve the specification of the POD and provision the containers accordingly. Once the POD is created successfully, the controller on the master node will checkpoint the state change of the worker node in Etcd. This scheduling and provisioning process is depicted in figure 2. Figure 2. Kubernetes POD scheduling & provisioning process
Figure 2. Kubernetes POD scheduling & provisioning process
Scheduling Policies
A Scheduling Policy can specify the predicates and priorities for the kube-scheduler to select the target node. Predicates are used for Filtering and Priorities are used for Scoring the candidate node that passed the filtering predicates.
Filtering
Kube scheduler filtering is used to filter out worker nodes that are not suitable for a POD. Examples of Filtering predicates include:
- General predicates (e.g., PodFitsResources,PodFitsNodeSelector)
- Storage related predicates (e.g., NoDiskConflict,MaxCSIVolumeCount)
- Compute node related predicates (e.g., PodToleratesNodeTaint)
- Runtime related predicates(e.g., CheckNodeCondition , CheckNodeMemoryPressure)
Scoring
- Kube scheduler scoring phase is to rank the nodes that survived filtering phase and to choose the most suitable Pod placement. The scheduler assigns a score to each of the remaining nodes, based on the scoring priorities. Finally, kube-scheduler assigns the Pod to the node with the highest ranking.
- Scoring Priorities include SelectorSpreadPriority, InterPodAffinityPriority, LeastRequestedPriority, NodeAffinityPriority, BalancedResourceAllocate, etc. For each priority passed, the corresponding node will be given a score (1~10), based on the weigh assigned by the user, The sum of all priority score determines the score of a worker node.
For more understanding about how to customizing kubernetes scheduler. Please refer to our next article.
Gemini Open Cloud is a CNCF member and a CNCF-certified Kubernetes service provider. With more than ten years of experience in cloud technology, Gemini Open Cloud is an early leader in cloud technology in Taiwan.
We are currently a national-level AI cloud software and Kubernetes technology and service provider. We are also the best partner for many enterprises to import and management container platforms.
Except for the existing products “Gemini AI Console” and “GOC API Gateway”, Gemini Open Cloud also provides enterprises consulting and importing cloud native and Kubernetes-related technical services. Help enterprises embrace Cloud Native and achieve the goal of digital transformation.
Guest post originally published on Gemini Open Cloud‘s blog by Patrick Fu, CEO of Gemini Open Cloud
Source CNCF
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!