
At this year’s Google Data Cloud Summit, we announced Cloud Spanner change streams. Today, we are thrilled to announce the general availability of change streams. With change streams, Spanner users are now able to track and stream out changes (inserts, updates, and deletes) from their Cloud Spanner database in near real-time.
Change streams provides a wide range of options to integrate change data with other Google Cloud services. Common use cases include:
From our partners:
- Analytics: Send change events to BigQuery to ensure that BigQuery has the most recent data available for analytics.
- Event triggering: Send data change events to Pub/Sub for further processing by downstream systems.
- Compliance: Save the change events in Google Cloud Storage for archiving purposes.
Getting started with change streams
This section walks you through a simple example of creating a change stream, reading its data, and sending the data to BigQuery for analytics.
If you haven’t already done so, get yourself familiar with Cloud Spanner basics with the Spanner Qwiklab.
Creating a change stream
Spanner change streams are created with DDL, similar to creating tables and indexes. Change stream DDL requires the same IAM permission as any other schema change (spanner.databases.updateDdl).
A change stream can track changes on a set of columns, a set of tables, or an entire database. Each change stream can have a retention period of anywhere from one day to seven days, and you can set up multiple change streams to track exactly what you need for your specific objectives. Learn more about creating and managing change streams.
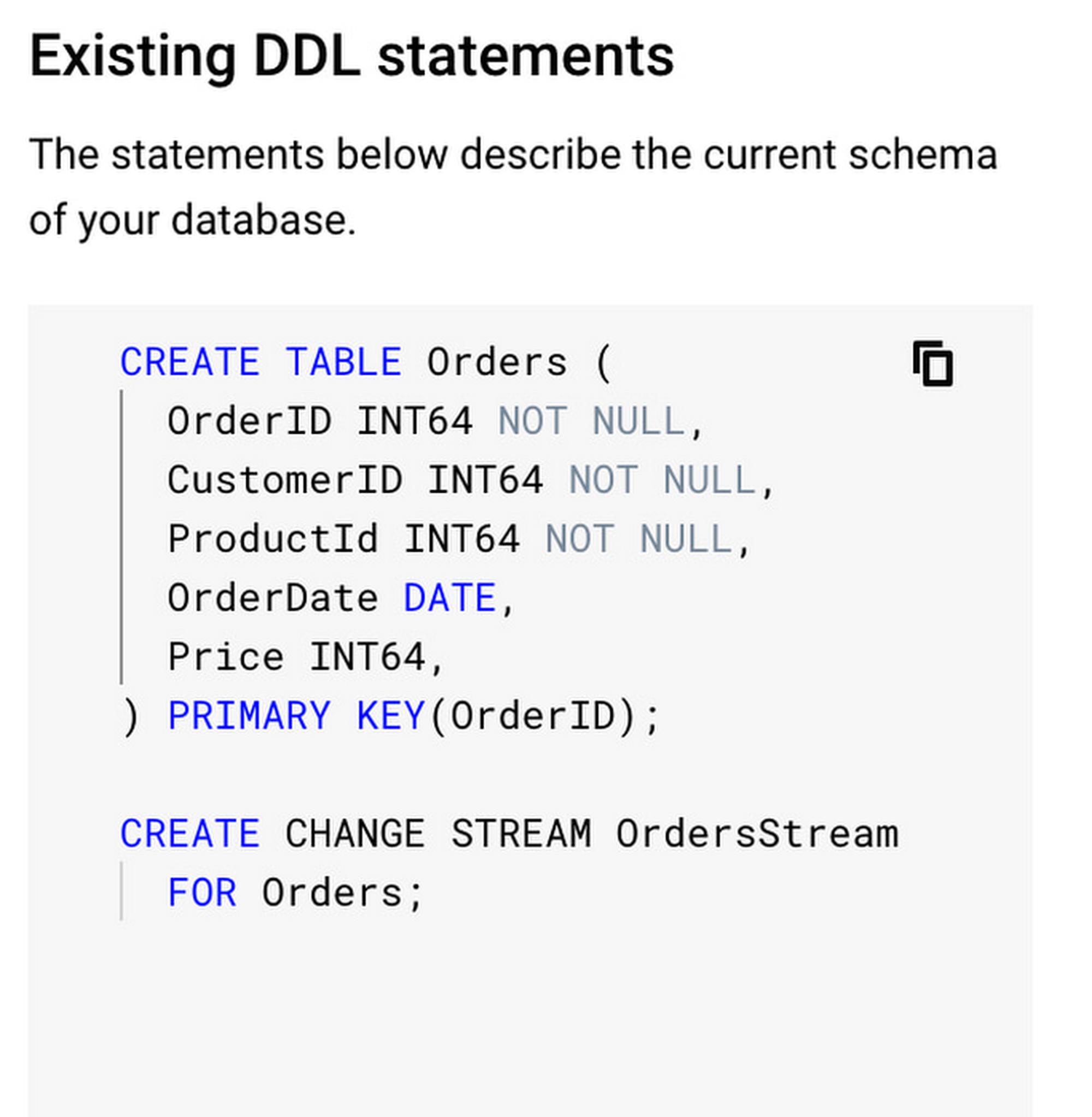
Suppose you have a table Orders like this:
CREATE TABLE Orders (OrderID INT64 NOT NULL,CustomerID INT64 NOT NULL,ProductId INT64 NOT NULL,OrderDate DATE,Price INT64,) PRIMARY KEY(OrderID);
The DDL to create a change stream that tracks the entire Orders table with a (implicit) default retention of 1 day would be defined as:
CREATE CHANGE STREAM OrdersStream FOR Orders;
Creating change streams is a long running operation. You can check the progress on the change streams page in the Cloud console:
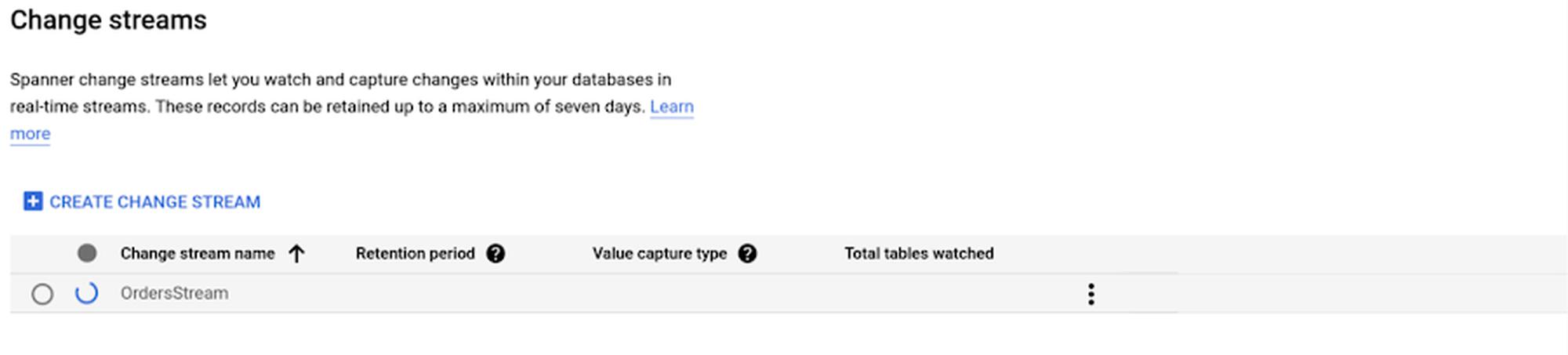

Once created, you can click on the change stream name to view more details:
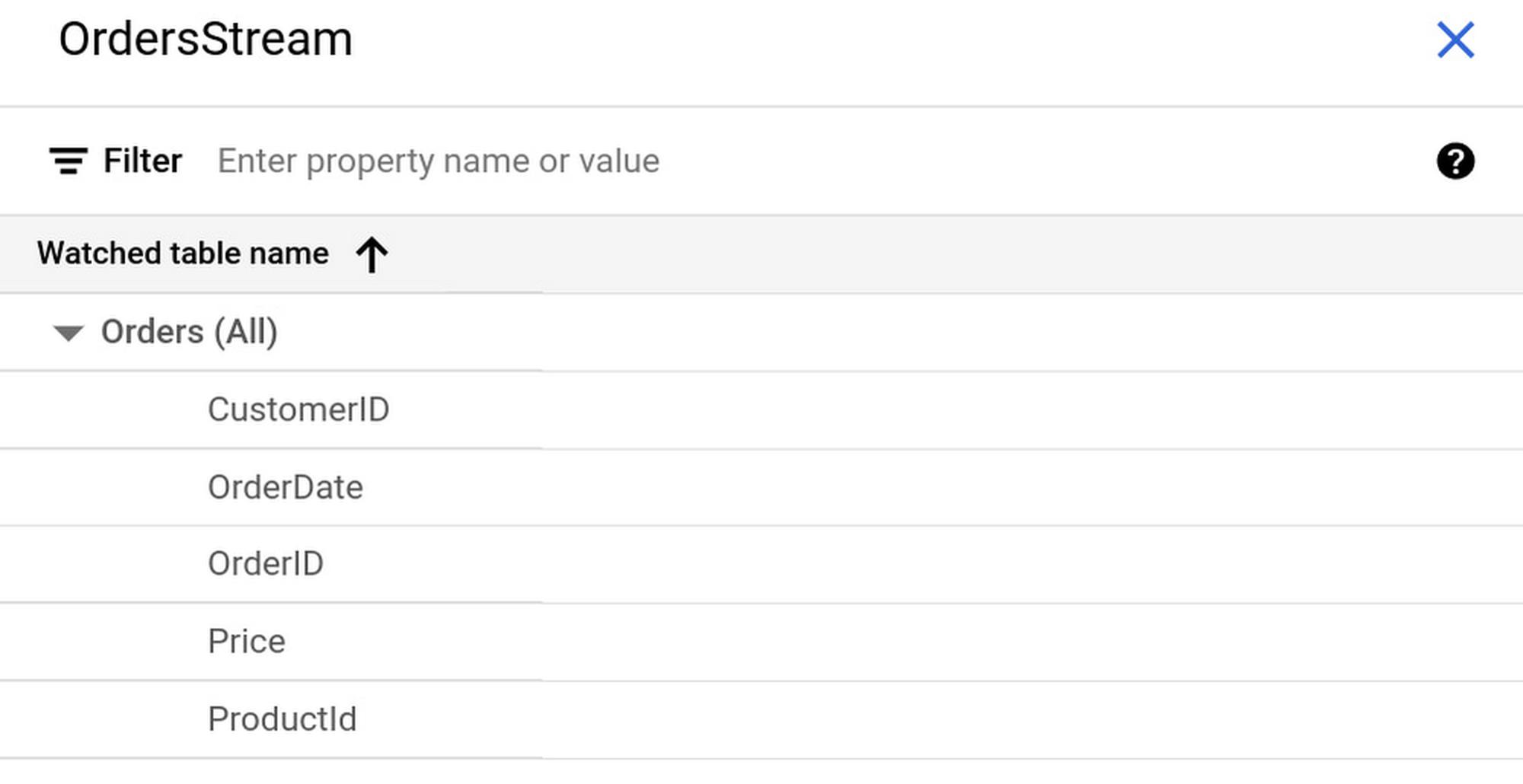

Your database DDL should look something like:

Now that the change stream has been created, you can process the change stream data.
Streaming data to BigQuery
There are several ways to process change stream data. The easiest way is to use the Spanner connector for Apache Beam which allows you to build scalable data processing pipelines for Google Cloud Dataflow. We provide Dataflow templates for processing and writing change data to BigQuery or Google Cloud Storage respectively. Learn more about how Cloud Spanner change streams work with Dataflow.
In this example, we will use the Spanner change streams to BigQuery template to write change stream data to BigQuery.
First, navigate to your project’s Dataflow Jobs page in the Google Cloud Console. Click on CREATE JOB FROM TEMPLATE, choose the Change streams to BigQuery template, then fill in the required fields:
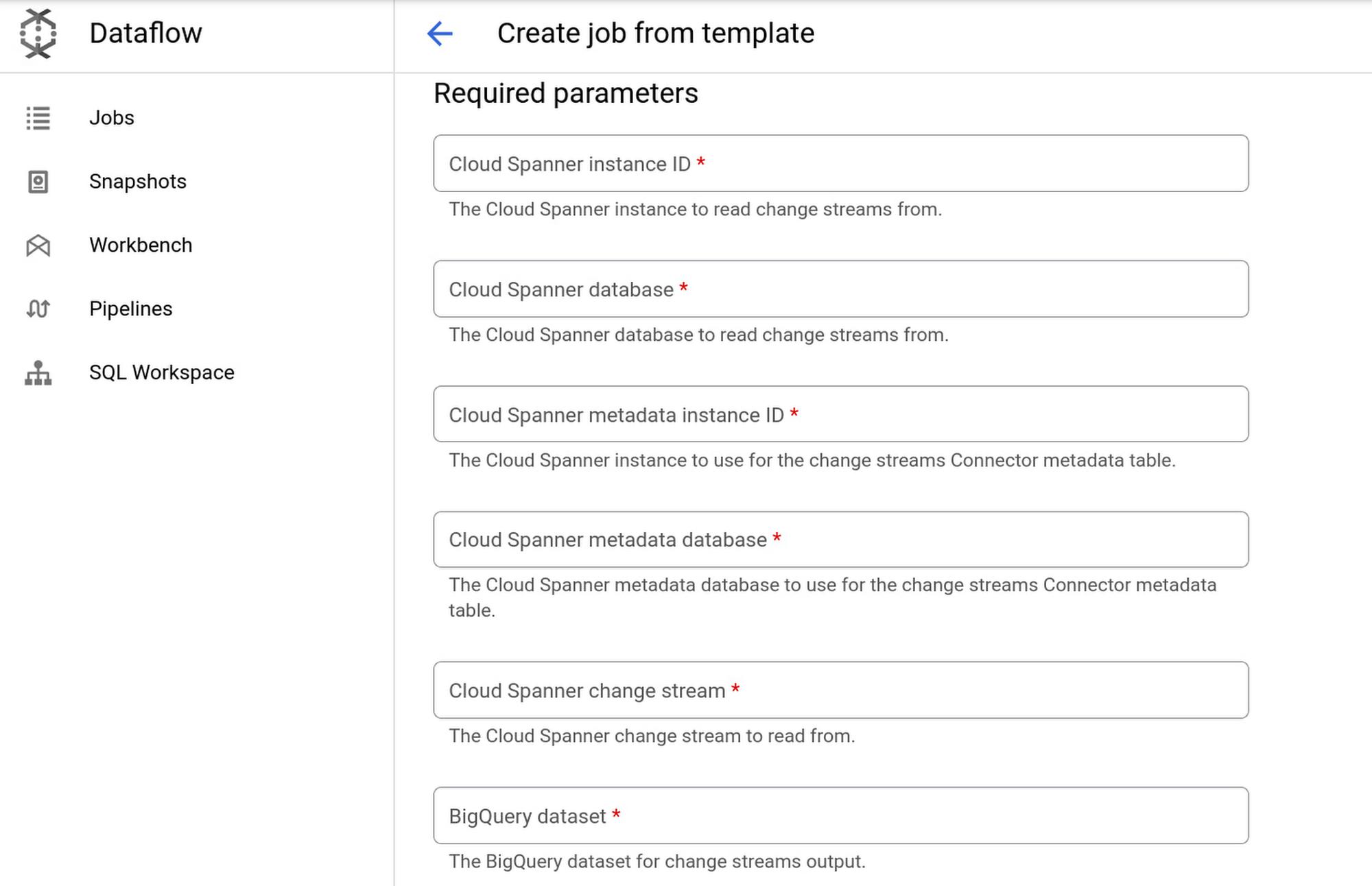

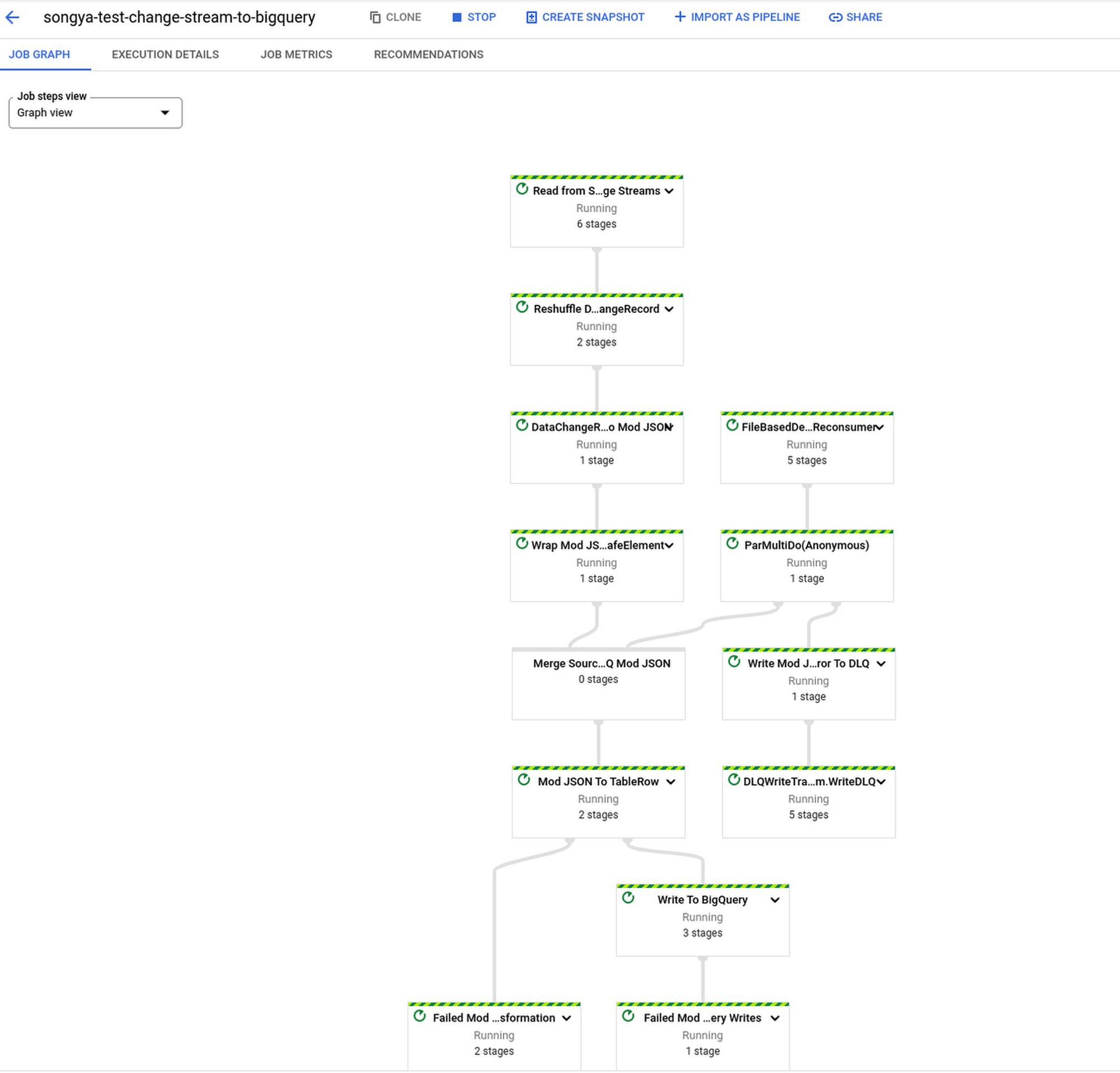
Click RUN JOB, and wait for Dataflow to build the pipeline and launch the job. Once your Dataflow pipeline is running, you can view the job graph, execution details, and metrics on the Dataflow Jobs page:

Now let’s write some data into the tracked table Orders:
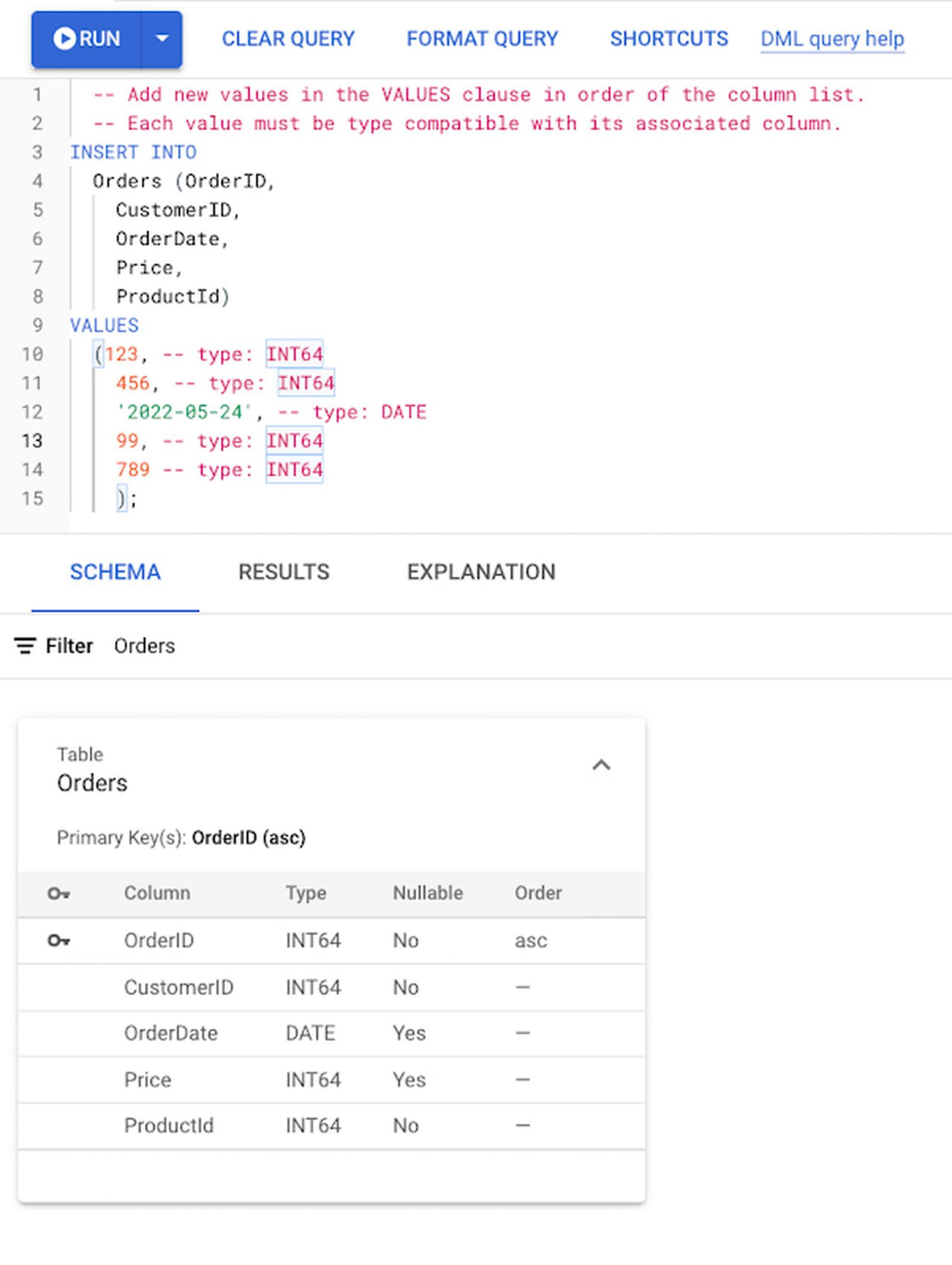
Under the hood, when Spanner detects a data change in a data set tracked by a change stream, it writes a data change record synchronously with that data change, within the same transaction. Spanner co-locates both of these writes so they are processed by the same server, minimizing write processing. Learn more about how Spanner writes and stores change streams.
Finally, when you view your BigQuery dataset, you will see the row that you just inserted, with some additional information from the change stream records.


You are all set! As long as your Dataflow pipeline is running, the data changes to the tracked tables will be seamlessly streamed to your BigQuery dataset. Learn more about monitoring your pipeline.
More ways to process change stream data
Instead of using the Google-provided Dataflow templates for BigQuery and Google Cloud Storage, you can choose to build a custom Dataflow pipeline to process change data with Apache Beam. For this case, we provide the SpannerIO Dataflow connector that outputs change data as an Apache Beam PCollection of DataChangeRecord objects. This is a great choice if you want to define your own data transforms, or want a different sink than BigQuery or Google Cloud Storage. Learn more about how to create custom Dataflow pipelines that consume and forward change stream data.
Alternatively, you can process change streams with the Spanner API. This approach, which is particularly well-suited for more latency-sensitive applications, does not rely on Dataflow. The Spanner API is a powerful interface that lets you read directly from a change stream to implement your own connector and stream changes to the pipeline of your choice. With the Spanner API, a change stream is divided into multiple partitions, each of which can be used to query a change stream in parallel for higher throughput. Spanner dynamically creates these partitions based on load and size. Each partition is associated with a Spanner database split, allowing change streams to scale as effortlessly as the rest of Spanner. Learn more about using the change stream query API.
What’s next
Spanner change streams is available to all customers today at no additional cost – you’ll pay only for any extra compute and storage of the change stream data at the regular Spanner rates. Since change streams are built right into Spanner, there’s no software to install, and you get external consistency, industry-leading availability, and effortless scale with the rest of the database.
Start exploring change streams from the change stream overview today!
By: Le Chang (Software Engineer) and Yang Song (Software Engineer)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







