
In January, we previewed Neo4j’s and Google Cloud Vertex AI’s partnership in a blog about how you can use graphs for smarter AI when using Neo4j AuraDS to generate graph embeddings.
This blog post garnered a lot of attention from data scientists looking to amplify their machine learning (ML) pipelines by feeding knowledge (graph features) of the graph to enhance the ML model’s predictability.
From our partners:
Since then, Neo4j released a new 2.0 version of the Neo4j Graph Data Science Platform. This makes it incredibly simple to get started on Google Cloud with the general availability of Neo4j AuraDS, the Graph Data Science as a Service solution.
Why are graphs important?
In today’s world, we connect, communicate, and interact with one another or machines in entirely new ways that evolve and change daily. It’s impossible for us to ignore how these relationships between people, places, objects, and events signify and influence the value and importance of our interactions.
Using graphs as a data structure has become especially important in more recent years. They’ve changed the way we create pharmaceuticals, improved how we discover and combat fraud in finance, provided better recommendations to customers, and disambiguated entities and their identities.

Graphs and graph data science allow us to find what’s important for a data point based on its connections or where it lives within a network. We can use the same techniques to find the inverse – what is unusual about the network. This allows us to predict what’s going to happen next with greater accuracy by computing graph features that can be used for graph native ML or fed into tools like Vertex AI.
Using the graph structure to compute algorithms or create embeddings has increased the accuracy and reliability of Neo4j and Google Cloud’s customers’ machine learning pipelines. If you would like to explore how graph data science can empower you, check out these resources and notebooks that walk you through worked examples with Neo4j Graph Data Science:
- Entity Resolution: White paper, Worked example (with code)
- Fraud & Anomaly Detection: White paper, Worked example (with code)
- Recommendation Systems: White paper, Worked example (with code)
Graph Data Science as a Service: AuraDS
AuraDS is Neo4j’s fully managed graph data science offering. Neo4j has built a complete platform that makes it easy for data scientists to start and take their use case all the way from a hypothesis to production without the need for a team of software engineers, database managers, or IT administrators.
You have access to over 65 state-of-the-art graph and machine learning algorithms that can enhance your enterprise’s analytics and machine learning solutions. We include all of your compute, storage, IO, and network costs in a simple hourly pricing model. You get all of the graph data science goodness available in the cloud, on Google Cloud Platform.
“Neo4j AuraDS has a simple pricing structure that makes it easy to understand and manage costs associated with compute.” – Mike Morley, Director AI/ML, Arcurve
My favorite feature of all? Because AuraDS is a managed service, we’re constantly pushing out new algorithms, performance improvements, and bug fixes directly to your instances so you don’t have to worry about cumbersome operation concerns.
To get started, creating an instance is super simple. We guide you through the process, and all you need to provide is:
- Number of Nodes
- Number of Relationships
- What Algorithm Categories do you wish to use


This allows us to size the correct instance for the algorithms in the categories you’ve selected against the number of nodes and relationships you would like to run. Of course, as your use case grows or shrinks, you can resize your instance up or down to meet your needs, and when you’re not using it, you can pause them to save costs.
If you’re unsure and exploring, you can also select that option. As you get more familiar with your needs, AuraDS will tell you when you need to scale up to run particular algorithms.
“Neo4j AuraDS is a great tool because we can tweak our models over time to improve them. We have everything we need all in one place with Neo4j Graph Data Science – it makes it easy for us to focus on building our business because the software works easily with our existing toolset and data science approaches.” – Zack Gow, CTO, Orita
How to integrate AuraDS with Vertex AI
We’ve seen lots of customers integrate AuraDS into their estate in many ways. We’ve conceptualized this into a spectrum to help you select the right one for you depending on your needs and the maturity of your machine learning pipeline.
If you’re integrating AuraDS in a transient way, it’s super easy to plug into a mature ML pipeline, because you’re computing the features and moving them out into Vertex AI feature store.
A more centric approach allows you to not only compute graph features but also persist the data still in a graph format, which makes it fast to query deep paths and do exploratory data analysis with tools like Neo4j Bloom.


There is no wrong or right answer as to where you should start – it’s all driven by your architecture and business needs.
“Today we have Spark jobs running in Google Dataproc that uses our Graph features generated by AuraDS. We’re looking to replace our current architecture with Vertex AI to simplify our development and deployment options. The features and integrations we get from AuraDS and Vertex AI make generating graph features, developing and managing our ML pipelines and monitoring our ML models a breeze.” – Zack Gow, CTO, Orita
In our worked example, we’re going to use a centric approach where we not only store the data in AuraDS but also compute our graph embeddings with FastRP and feed that into our Vertex AI workflow.
Since our last post, we’ve released our native Python client for Neo4j Graph Data Science. This makes integrating with Vertex AI even simpler without needing to write lots of boilerplate code for querying and converting. You can now write pure Python code to project graphs, run algorithms, and retrieve results as DataFrames. You can even project your graph directly into memory from DataFrames without the need to import it into the database first.
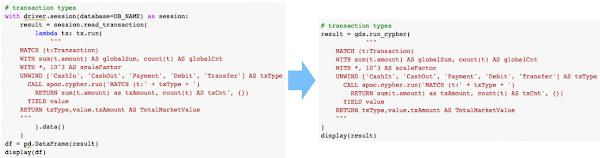

You can follow along with the updated notebook here to learn more about how to generate graph embeddings using FastRP.
With the embedding calculated, we can now write them to a CSV and push that to a cloud storage bucket where Google Cloud’s Vertex AI can work with it. These steps are detailed in the notebook here.
Using graph features in Vertex AI
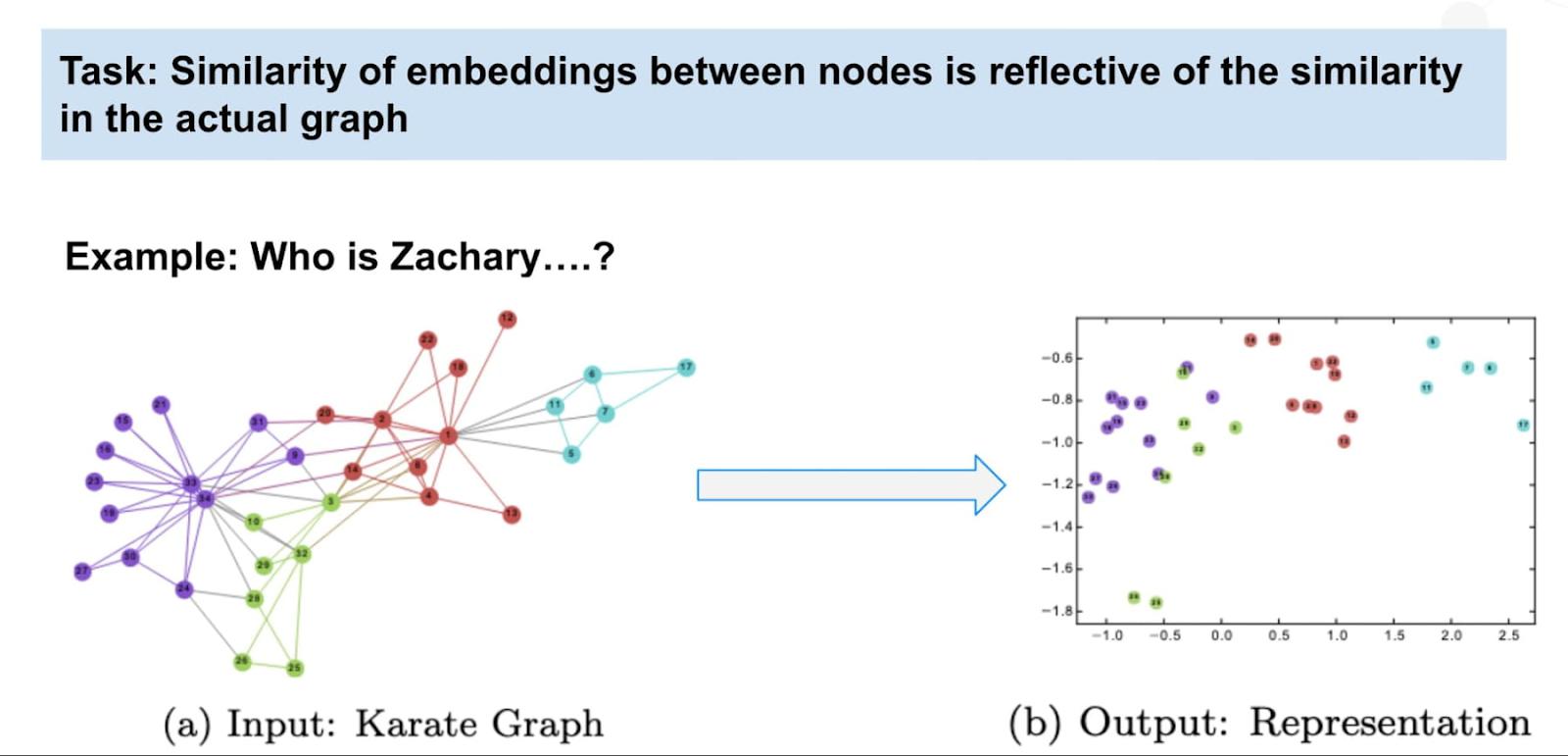

The embeddings represent a node’s placement within the graph and how it interacts with other nodes. The reason we use a vector as a data structure is so we can use tabular methods in Google Cloud’s Vertex AI to train a machine learning model.
First, we need to pull the data from a cloud storage bucket and use that to create a dataset in Vertex AI. The Python call looks like this:
dataset = aiplatform.TabularDataset.create(display_name="paysim",gcs_source=os.path.join("gs://", STORAGE_BUCKET, STORAGE_PATH, TRAINING_FILENAME),)
With the dataset created, we can then train a model on it. That Python call looks like this:
model = job.run(dataset=dataset,target_column="is_fraudster",training_fraction_split=0.8,validation_fraction_split=0.1,test_fraction_split=0.1,model_display_name="paysim-prediction-model",disable_early_stopping=False,budget_milli_node_hours=1000,)
You can view the results of that call in the notebook. Alternatively, you can log into the GCP console and view the results in the Vertex AI’s GUI.
The Vertex AI console view is awesome. It includes neat visualizations like ROC curves and the confusion matrices, so you can understand how your ML model is performing.
Vertex AI also offers helpful tooling for deploying the trained model. The dataset can be loaded into a Vertex AI feature store. Then, an endpoint can be deployed. New predictions can be computed by calling that endpoint. This is detailed in the notebook here.
Take the next steps
If you found this blog post interesting and want to give the technology a spin, you can find AuraDS in the GCP marketplace.
You can also learn more about Vertex AI here. The notebook we’ve worked through is here. We hope you fork it and modify it to meet your needs. Pull requests are always welcome!
By: Luke Gannon (Product Manager, AuraDS)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







