
Imagine what could be possible if we had a dataset that could automatically and in near real-time show you how the Earth has changed week over week, month over month, year over year. We would get a birds eye view of recent events like floods, fires, snowstorms from days ago and be able to identify seasonal changes on the surface of the Earth at a global scale, and remediate with regenerative solutions.
From our partners:
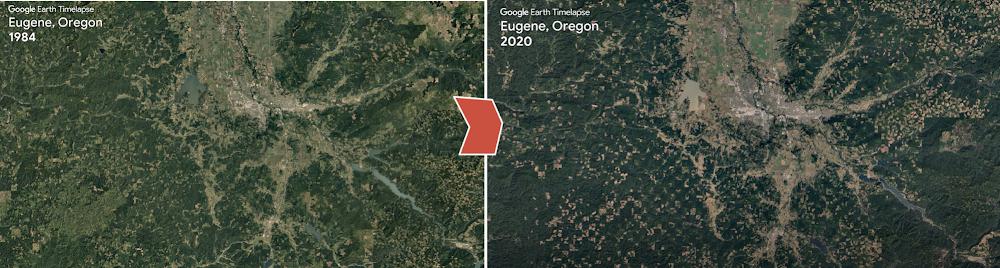
Such a project called Dynamic World has made this possible. It offers a freely available near real time 10 meter land cover dataset with over 5,000 images generated every day. It is one of the largest global-scale land cover datasets produced to date, producing probabilities per-pixel for Sentinel-2 scenes that have 35% or less cloud cover.
Historically, globally consistent datasets that are timely and up-to-date, reflecting the present material on the surface of the Earth, also known as land cover, were not available. Satellite imagery allows people to observe changes on the planet, and land cover data allows us to quantify those changes, where they are happening on the ground. Land cover types for Dynamic World include trees, crops, built-up areas, flooded vegetation, bare ground, snow/ice, scrub/shrub, water, and grass.

Automating 🗺️ land cover classification
Dynamic World uses Google Earth Engine, AI, and Google cloud computing to classify images of the planet into different land categories. This resulting land cover dataset shares the probability of different land cover types on a per-pixel basis, which represents the real world more accurately. Historically, land cover datasets only assign one land cover class per pixel. Now, we have much more detailed information to derive final maps from.
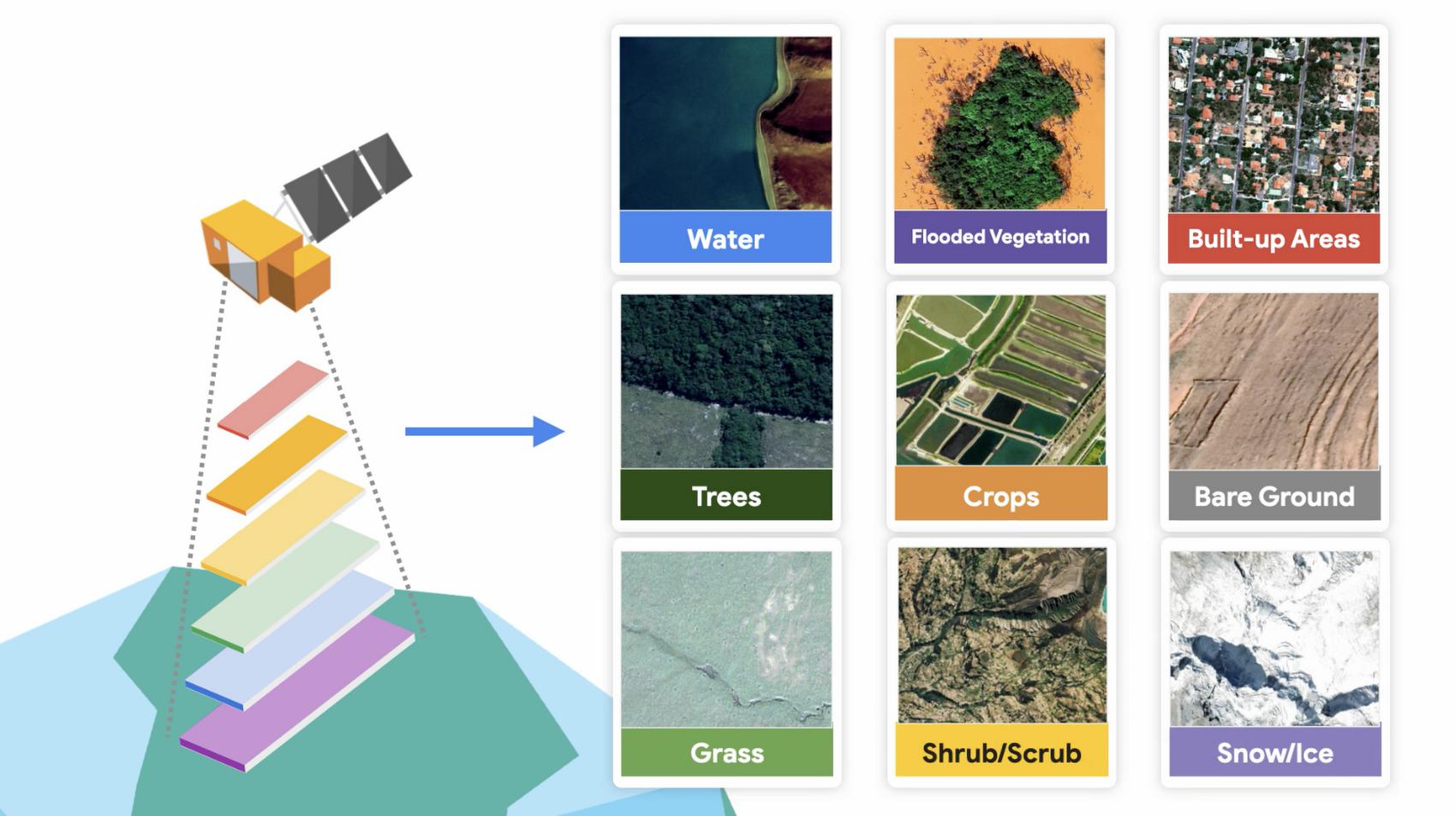
Each pixel provides the amazing granularity of 10 meters by 10 meters, thanks to the open availability of Copernicus Sentinel 2, a satellite constellation from the European Space Agency. Dynamic World is produced in partnership with Google and the World Resource Institute.
You can explore Dynamic World at dynamicworld.app If you are a Google Earth Engine user, try loading it as an image collection in Earth Engine’s code editor as GOOGLE/DYNAMICWORLD/V1. For non-commercial users, there’s no cost for creating an Earth Engine account.
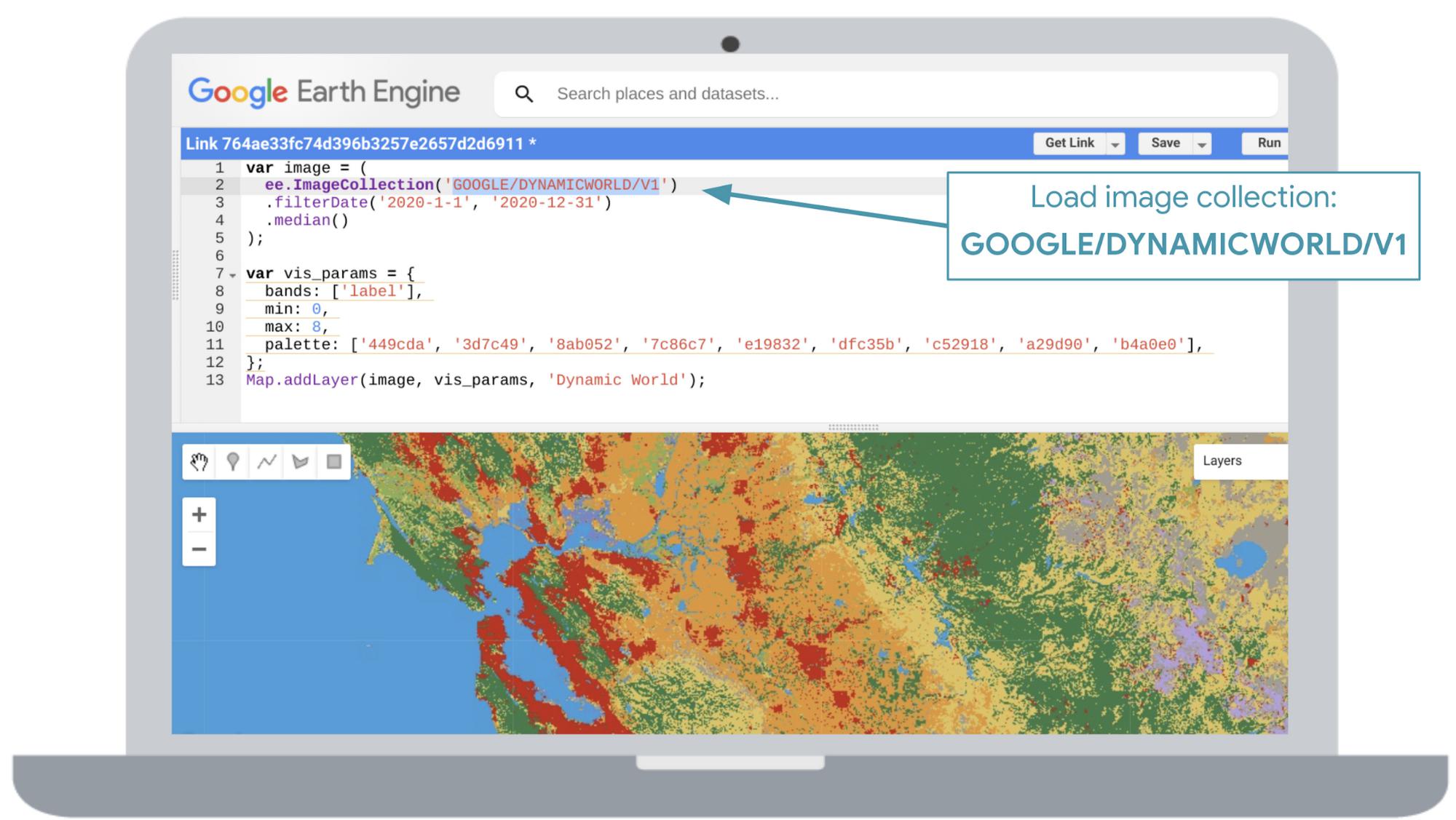
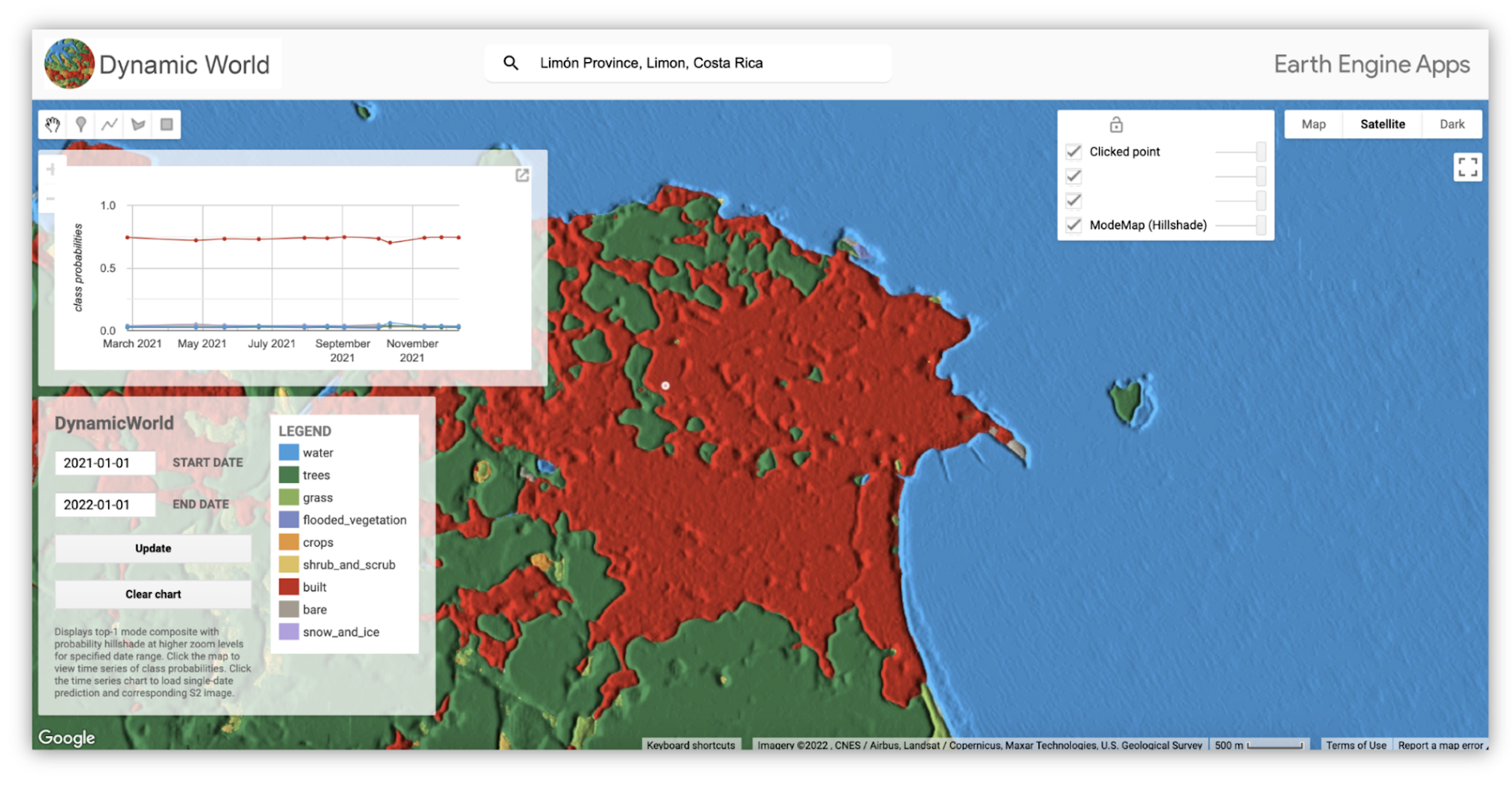
You can also visualize data in a custom web app. This app’s interface enables you to search by location, and choose a desired date range. You can click a specific area to dive into the model’s classification confidence via a chart. If you click on a point on the chart, you see the corresponding Sentinel-2 image that Dynamic World used to infer the land cover classification for that date. You can also toggle different map layers such as Satellite, Terrain or Google Maps basemap.
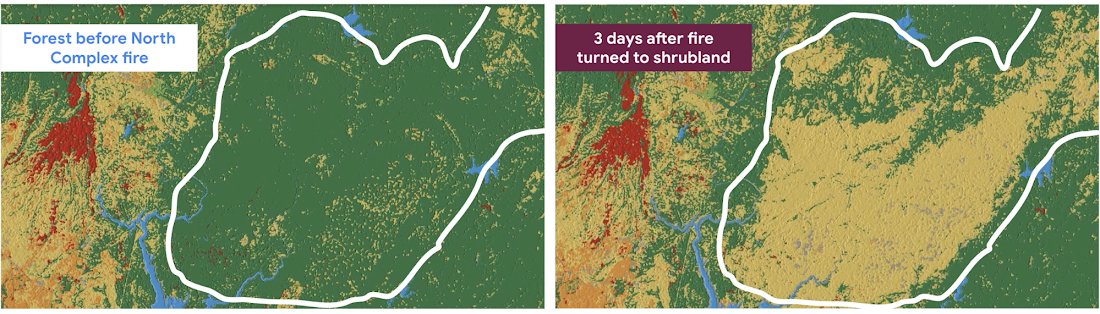
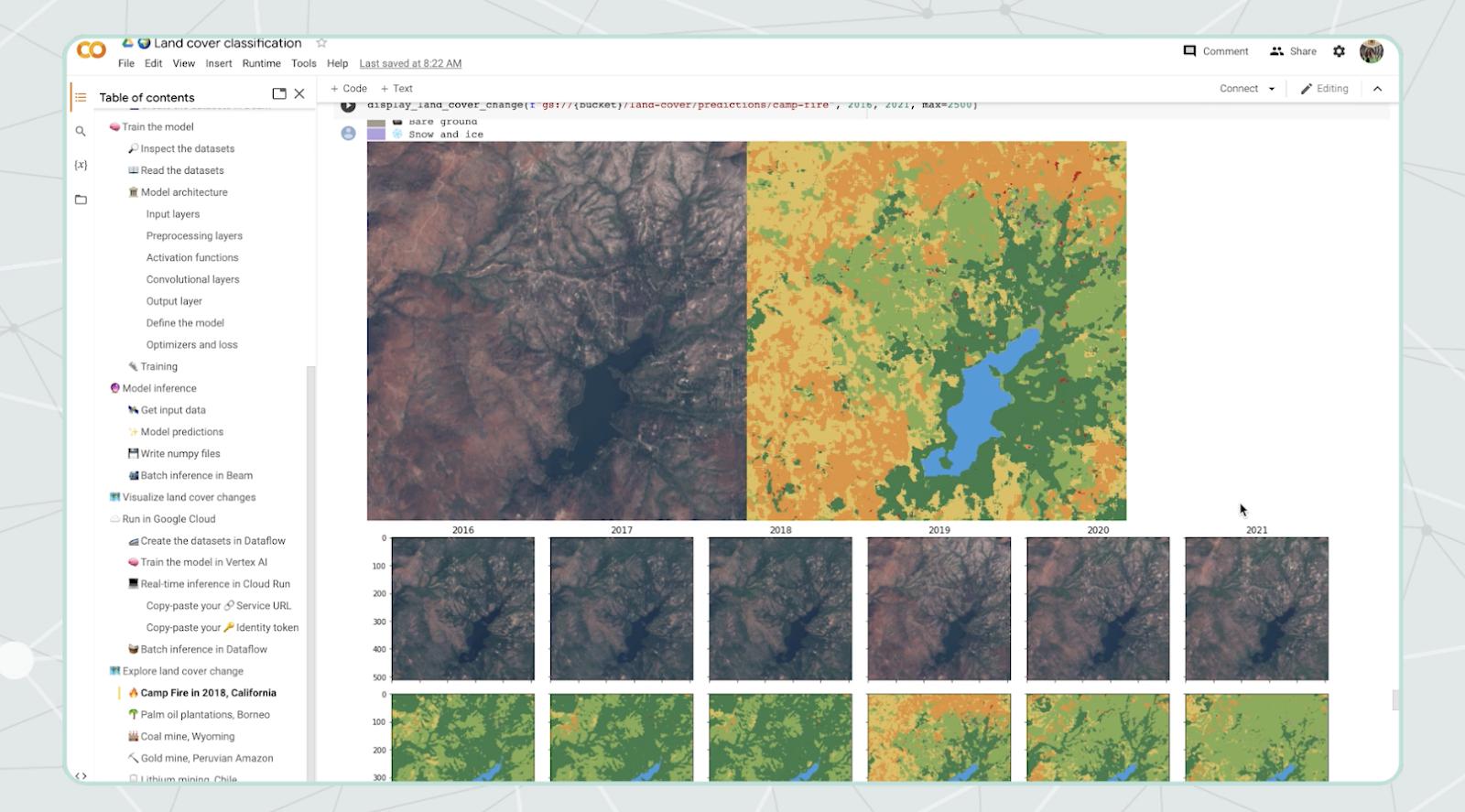
Here’s an example of how we can see forest loss after a wildfire. We visualize how 300,000 acres of beautiful forest east of Chico, California were burned, and classified as shrubland in a few days.
It’s a powerful sustainability platform built on Google Cloud and Earth Engine. It helps unlock greater flexibility and timely insights compared to annual static maps built from manual curations. The core intention for this near real time land cover dataset is to encourage organizations to build derivative maps so we can make wiser decisions to protect, manage and restore natural ecosystems.
The team expects NGOs, academia, the corporate sector, and existing users of land cover datasets, to use this data for climate-related research in agriculture, land use planning, conservation, and more. They are producing this dataset to support monitoring, forecasting, and decision making in the public sphere.
Inspired by this wonderful project, we in Developer Relations explored how to approach this Data Analytics and AI problem in our People and Planet AI series. This project requires combining many datasets from different sources, and then computing labels for the entire Earth. We recommend you use the Dynamic World’s dataset and app, but if you want to learn how to get started with building a lightweight model like Dynamic World’s, keep reading. A geo-spatial multi-class classification model is a fancy way of saying “a model that classifies many things from satellite imagery.” To better understand this technology I also recommend taking a look at our 10 min YouTube video, and our interactive notebook with all our code. You can also find Dynamic World’s GitHub.
Building a 🛰️ geospatial multi-class classification model
Here is the architecture diagram. This solution costs as low as $1 to perform (as of the date of this post).
The first step is to identify a land cover dataset that will help us train a model to classify the globe. Earth Engine’s catalog already hosts several. We chose the European Space Agency World Cover. We found it by searching for “land cover” in the catalog’s search bar. Note there’s over 11 land categories in the dataset, but will only use 9, as the Dynamic World team did. You can also use Dynamic World’s training data, which is open access here. Alternatively you can derive an EU training dataset from this LUCAS dataset.
You also want to use many datasets as data inputs, such as elevation data, etc. For simplicity we only used images of the Earth from Sentinel 2’s Top of Atmosphere dataset. We also want to define a function to remove clouds if detected. Luckily there are several off-the-shelf solutions to masking clouds, and so lots of people copy and paste functions. We made a simplified version.
We use convolutional neural networks (or CNNs) as our go-to ML technique when working with satellite image data in our People and Planet AI series. This is because they work like our eyes, they analyze images and find patterns for us from the surroundings.
We then need to understand the shape of our inputs and outputs. Satellites observe different wavelengths or “bands” from the electromagnetic spectrum. Our inputs in this case have three dimensions: width, height, and number of bands.
The outputs are the probability of a classification of each patch of pixels. Since we have 9 classification labels, we have 9 values. Each value is the probability of being a type of surface on the Earth. We then take the highest probability as the final label.
Next, we use Dataflow (a data processing service in Google Cloud) and Earth Engine’s function ee.image.getDownloadURL. They work together to create a balanced dataset that is shuffled at random. We do this to minimize bias in our model.
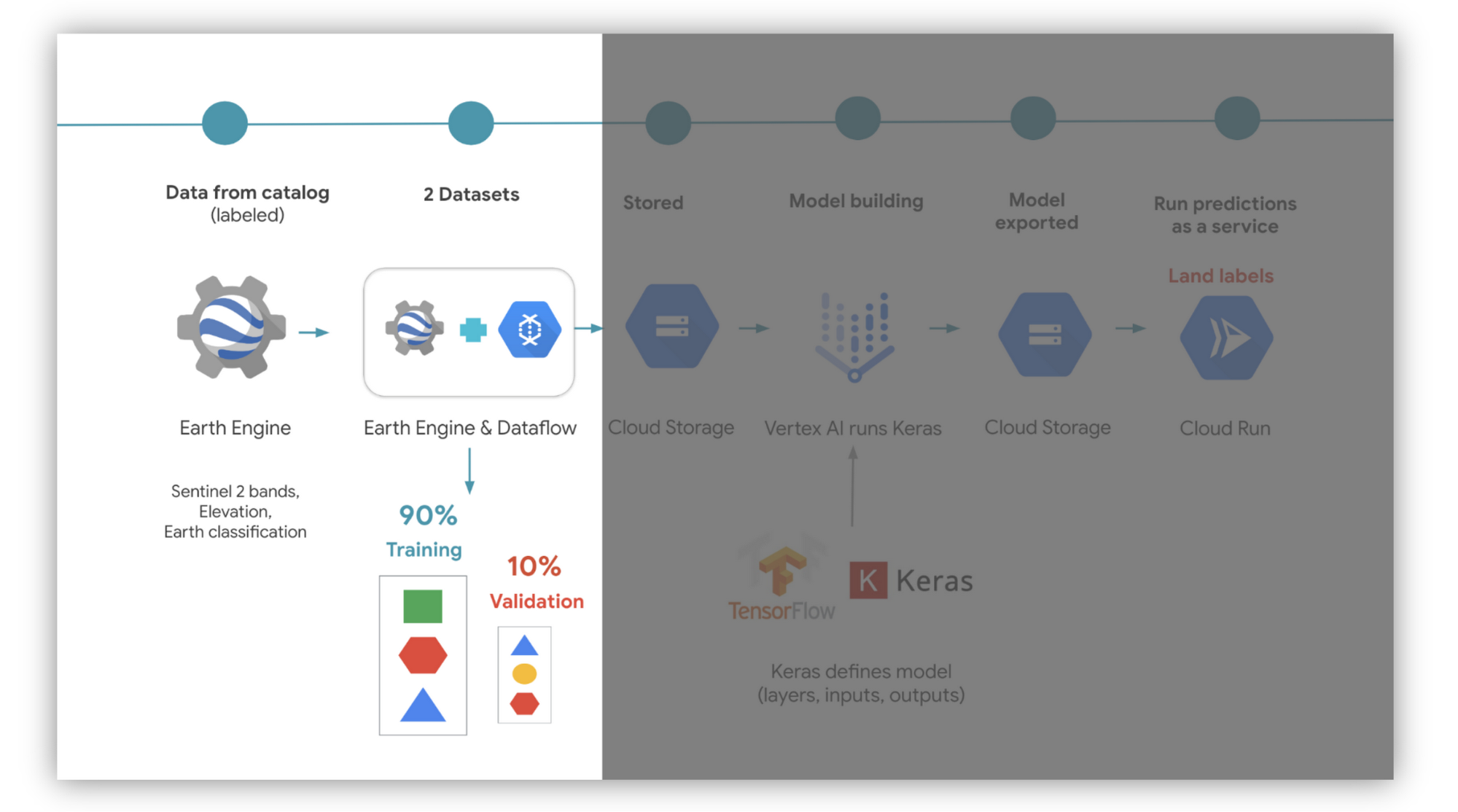
We choose how much of this data goes to building two datasets: one for training and the other for validation. We partition the data respectively in a 90:10 ratio, ensuring that no data point is shared in both datasets. Earth Engine exports the datasets into a format called TFRecords into Google Cloud Storage. This is a file format optimized for TensorFlow, which is an ML library.
At this stage, we are ready to train a model by using TensorFlow. We then proceed to read the training dataset from Cloud Storage. We define the model in Python with Tensorflow Keras (which is a high level API or interface to TensorFlow). The validation dataset is used to check the predictions on data it has never seen before. We then train the model in Vertex AI using Vertex AI’s pre-built containers for custom models. The container includes TensorFlow and has GPUs enabled to help speed up training.
Part of this journey will also need retraining the training dataset many times (shuffled so it doesn’t find bias in the order). Every time the model goes through the entire training dataset (this is called an epoch). Try it with 10 epochs, and see what happens with the accuracy score (aka how well it classifies a surface). Also tinker with how long you want to train the model for.
Once you are happy with the training results, the model is saved again into Cloud Storage.
Get 🪄 predictions from the model
💻 Predictions online service for new images
Next, we host the model on Cloud Run, which can be used to classify incoming images of the Earth (you create a trigger). You could also host the model in Vertex AI, but we preferred Cloud Run for this use case. This is because we do not need VMs running all the time. By only using compute resources when we need them (as opposed to running VMs 24 hours), we reduce compute costs and our carbon footprint from the energy supplying those VMs.
💽 Batch predictions on entire dataset
We could also run predictions in batch for the entire dataset of images using Dataflow. This is useful if you update the model and want to reclassify all historical data again. You can then use Cloud Run in tandem to perform classifications on new images thereafter. This is because once an image is classified we do not need to run it through the model unless the model changes.
💻 Visualize insights
To turn results into useful and actionable tools, we leverage an interactive notebook like Google Colab (our sample is hosted in one). In it, we can use Python libraries to make visual maps of changes on the Earth from different years. Visuals can either be static images, GIFs, etc.
Upon identifying features that are important for your organization, you can create a custom web app. The app can display maps, charts, timelapses, scorecards of total miles affected, etc. You could also store GIFs or images in Cloud Storage and have them autogenerate Google Slide presentations on a routine basis.
✏️ Try it out
If you have some familiarity with Python, and would like to review more implementation considerations, please check out our interactive code sample. It covers things like why we use the ML Adam optimizer or Softmax for rating the model’s confidence. You can also enter your own Google Cloud project and run these resources live if you have an account. But, we recommend deleting these resources once you are done to avoid ongoing costs 🙂. You can alternatively check out Dynamic World’s GitHub here.
If you are interested in following more of our episodes please follow us at @open_eco_source on Twitter or our YouTube playlist.
Also please join us at our virtual Google Cloud Sustainability Summit on June 28th 2022 9am-11:40am PST. It is an event to discover the latest technology moonshots.
By: Alexandrina Garcia-Verdin (Cloud Developer Advocate)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







