
Many organizations struggle to create data-driven cultures where each employee is empowered to make decisions based on data. This is especially true for enterprises with a variety of systems and tools in use across different teams. If you are a leader, manager, or executive focused on how your team can leverage Google’s SRE practices or wider DevOps practices, definitely you are in the right place!
What do today’s enterprises or mature start-ups look like?
Today large organizations are often segmented into hundreds of small teams which are often working around data in the magnitude of several petabytes and in a wide variety of raw forms. ‘Working around data’ could mean any of the following: generating, facilitating, consuming, processing, visualizing or feeding back into the system. Due to a wide variety of responsibilities, the skill sets also vary to a large extent. Numerous people and teams work with data, with jobs that span the entire data ecosystem:
From our partners:
- Centralizing data from raw sources and systems
- Maintaining and transforming data in a warehouse
- Managing access controls and permissions for the data
- Modeling data
- Doing ad-hoc data analysis and exploration
- Building visualizations and reports
Nevertheless, a common goal across all these teams is keeping services running and downstream customers happy. In other words, the organization might be divided internally, however, they all have the mission to leverage the data to make better business decisions. Hence, despite silos and different subgoals, destiny for all these teams is intertwined for the organization to thrive. To support such a diverse set of data sources and the teams supporting them, Looker supports over 60 dialects (input from a data source) and over 35 destinations (output to a new data source).
Below is a simplified* picture of how the Looker ecosystem is central to a data-rich organization.
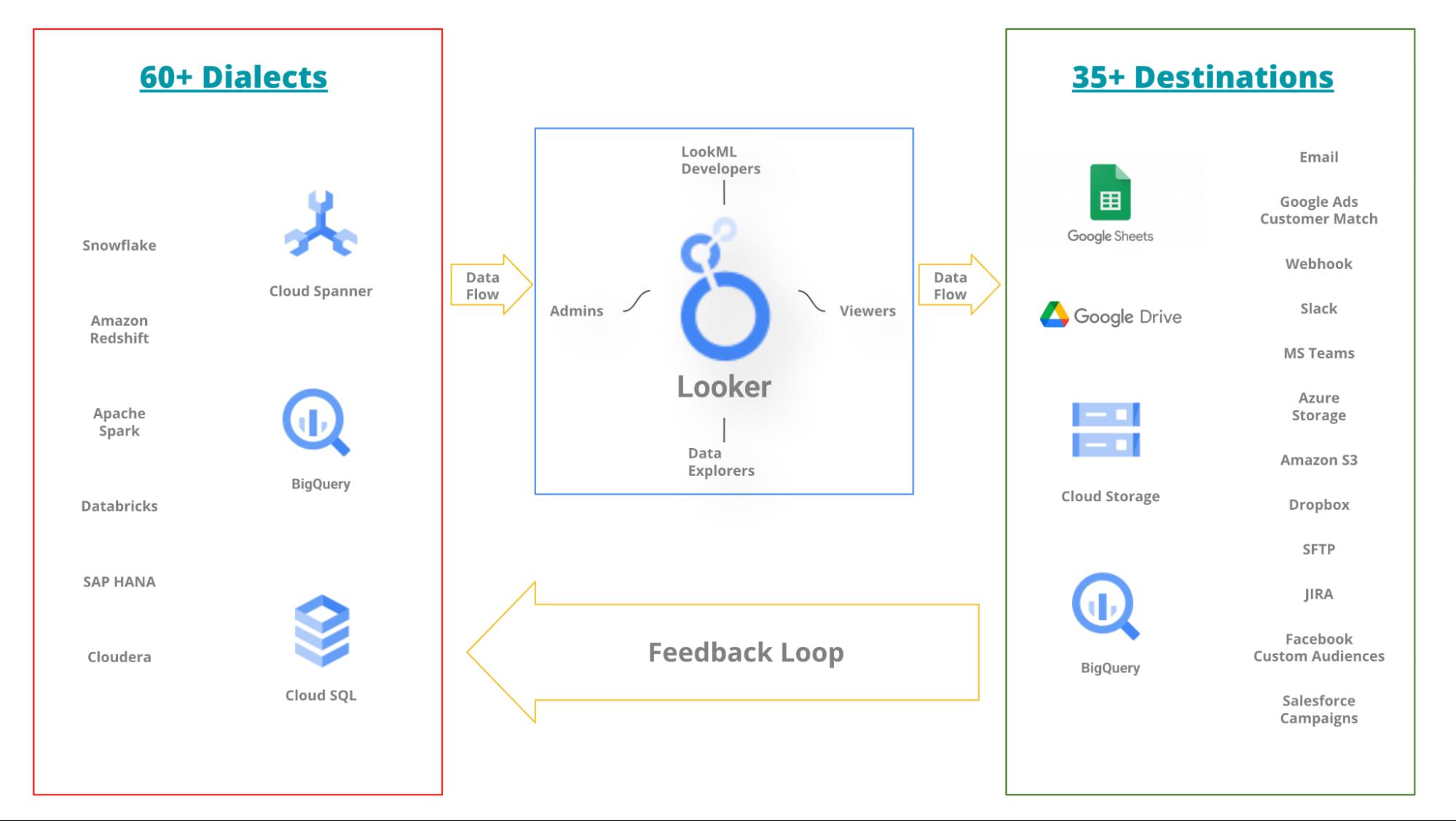
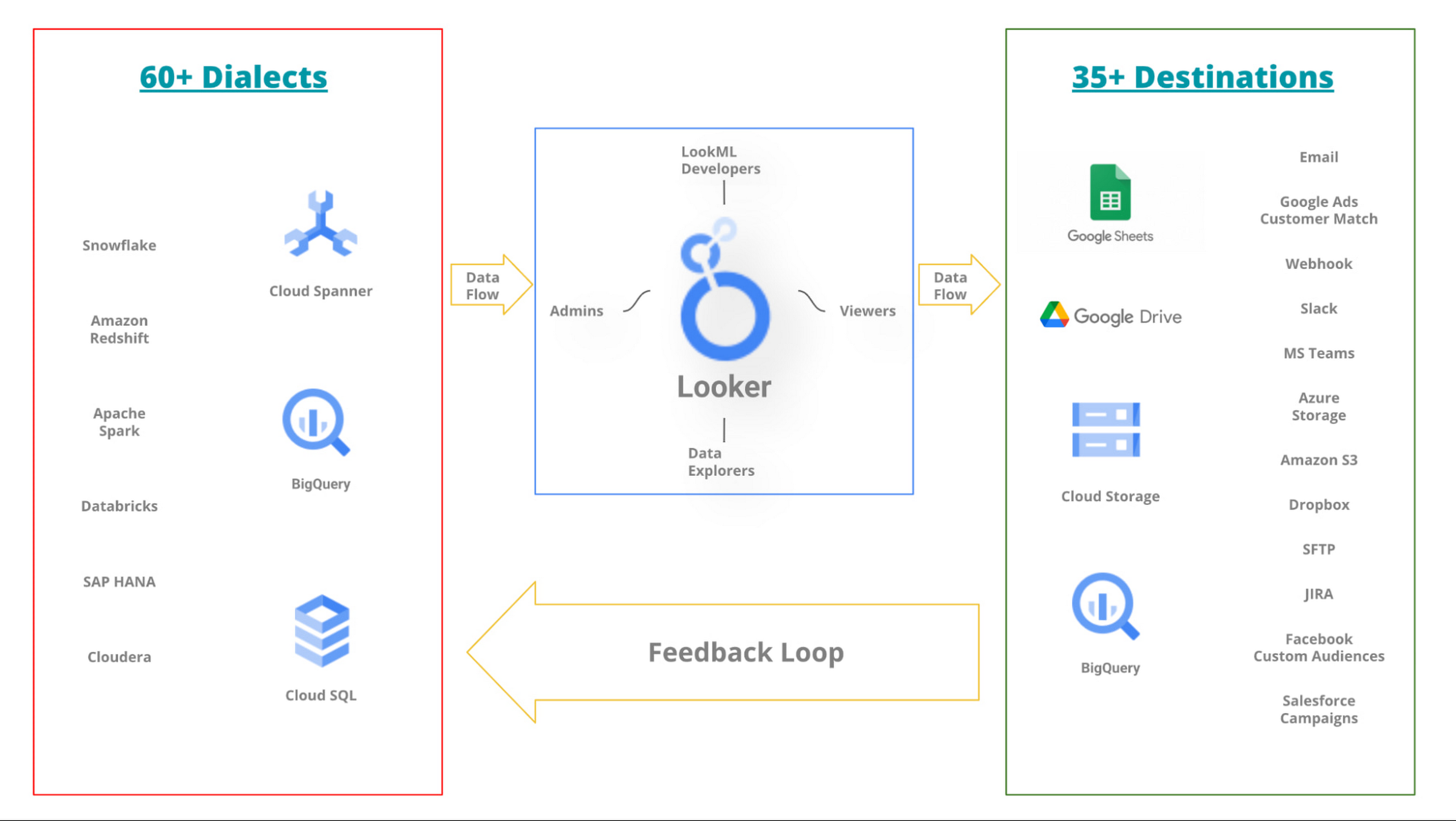
*The picture hides the complexity of team(s) accountable for each data source. It also hides how a data source may have dependencies on other sources. Looker Marketplace can also play an important role in your ecosystem.
What role can DevOps and SRE practices play?
In the most ideal state, all these teams will be in harmony as a single-threaded organization with all the internal processes so smooth that everyone is empowered to experiment (i.e. fail, learn, iterate and repeat all the time). With increasing organizational complexities, it is incredibly challenging to achieve such a state because there will be overhead and misaligned priorities. This is where we look up to the guiding principles of DevOps and SRE practices. In case you are not familiar with Google SRE practices, here is a starting point. The core of DevOps and SRE practices are mature communication and collaboration practices.
Let’s focus on the best practices which could help us with our Looker ecosystem.
- Have joint goals. There should be some goals which are a shared responsibility across two or more teams. This helps establish a culture of psychological safety and transparency across teams.
- Visualize how the data flows across the organization. This enables an understanding how each team plays their role and how to work with them better.
- Agree on the Golden Signals (aka core metrics). These could mean data freshness, data accuracy, latency on centralized dashboards etc. These signals allow teams to set their error budgets and SLIs.
- Agree on communication and collaboration methods that work across teams.
- Regular bidirectional communication modes – have shared Google Chat spaces/slack channels.
- Focus on artifacts such as jointly owned documentations pages, shared roadmap items, reusable tooling, etc. For example, System Activity Dashboards could be made available to all the relevant stakeholders and supplemented with notes tailored to your organization.
- Set up regular forums where commonly discussed agenda items include major changes, expected downtime and postmortems around the core metrics. Among other agenda items, you could define/refine a common set of standards, for example centrally defined labels, group_labels, descriptions, etc. in the LookML to ensure there is a single terminology across the board.
- Promote informal sharing opportunities such as lessons learned, TGIFs, Brown bag sessions, and shadowing opportunities. Learning and teaching have an immense impact on how teams evolve. Teams often become closer with side projects that are slightly outside of their usual day-to-day duties.
- Have mutually agreed upon change management practices. Each team has dependencies so making changes may have an impact on other teams. Why not plan those changes systematically? For example, getting common standards across the Advance deploy mode.
- Promote continuous improvements. Keep looking for better, faster, cost-optimized versions of something important to the teams.
- Revisit your data flow. After every major reorganization, ensure that organizational change has not broken the established mechanisms.
despite silos and different subgoals, destiny for all these teams is intertwined for the organization to thrive.
Are you over-engineering?
There is a possibility that in the process of maturing the ecosystem, we may end up in an overly engineered system – we may unintentionally add toil to the environment. These are examples of toil that often stem from communication gaps.
- Meetings with no outcomes/action plans – This one is among the most common forms of toil, where the original intention of a meeting is no longer valid but the forum has not taken efforts to revisit their decision.
- Unnecessary approvals – Being a single threaded team can often create unnecessary dependencies and your teams may lose the ability to make changes.
- Unaligned maintenance windows – Changes across multiple teams may not be mutually exclusive hence if there is misalignment then it may create unforeseen impacts on the end user.
- Fancy, but unnecessary tooling – Side projects, if not governed, may create unnecessary tooling which is not being used by the business. Collaborations are great when they solve real business problems, hence it is also required to refocus if the priorities are set right.
- Gray areas – When you have a shared responsibility model, you also may end up in gray areas which are often gaps with no owner. This can lead to increased complexity in the long run. For example, having the flexibility to schedule content delivery still requires collaboration to reduce jobs with failures because it can impact the performance of your Looker instance.
- Contradicting metrics – You may want to pay special attention to how teams are rewarded for internal metrics. For example, if a team focuses on accuracy of data and other one on freshness then at scale they may not align with one another.
Conclusion
To summarize, we learned how data is handled in large organizations with Looker at its heart unifying a universal semantic model. To handle large amounts of diverse data, teams need to start with aligned goals and commit to strong collaboration. We also learned how DevOps and SRE practices can guide us navigate through these complexities. Lastly, we looked at some side effects of excessively structured systems. To go forward from here, it is highly recommended to start with an analysis of how data flows under your scope and how mature the collaboration is across multiple teams.
Further reading and resources
- Getting to know Looker – common use cases
- Enterprise DevOps Guidebook
- Know thy enemy: how to prioritize and communicate risks—CRE life lessons
- How to get started with site reliability engineering (SRE)
- Bring governance and trust to everyone with Looker’s universal semantic model
Related articles
By: Saurabh Bangad (Technical Account Manager, Middle East)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







