
We’re excited to announce that the Pub/Sub Group Kafka Connector is now Generally Available with active support from the Google Cloud Pub/Sub team. The Connector (packaged in a single jar file) is fully open source under an Apache 2.0 license and hosted on our GitHub repository. The packaged binaries are available on GitHub and Maven Central.
From our partners:
Simplifying data movement
As you migrate to the cloud, it can be challenging to keep systems deployed on Google Cloud in sync with those running on-premises. Using the sink connector, you can easily relay data from an on-prem Kafka cluster to Pub/Sub or Pub/Sub Lite, allowing different Google Cloud services as well as your own applications hosted on Google Cloud to consume data at scale. For instance, you can stream Pub/Sub data straight to BigQuery, enabling analytics teams to perform their workloads on BigQuery tables.
If you have existing analytics tied to your on-prem Kafka cluster, you can easily bring any data you need from microservices deployed on Google Cloud or your favorite Google Cloud services using the source connector. This way you can have a unified view across your on-prem and Google Cloud data sources.
The Pub/Sub Group Kafka Connector is implemented using Kafka Connect, a framework for developing and deploying solutions that reliably stream data between Kafka and other systems. Using Kafka Connect opens up the rich ecosystem of connectors for use with Pub/Sub or Pub/Sub Lite. Search your favorite source or destination system on Confluent Hub.
Flexibility and scale
You can configure exactly how you want messages from Kafka to be converted to Pub/Sub messages and vice versa with the available configuration options. You can also choose your desired Kafka serialization format by specifying which key/value converters to use. For use cases where message order is important, the sink connectors transmit the Kafka record key as the Pub/Sub message `ordering_key`, allowing you to use Pub/Sub ordered delivery and ensuring compatibility with Pub/Sub Lite order guarantees. To keep the message order when sending data to Kafka using the source connector, you can set the Kafka record key as a desired field.
The Connector can also take advantage of Pub/Sub’s and Pub/Sub Lite’s high-throughput messaging capabilities and scale up or down dynamically as stream throughput requires. This is achieved by running the Kafka Connect cluster in distributed mode. In distributed mode, Kafka Connect runs multiple worker processes on separate servers, each of which can host source or sink connector tasks. Configuring the `tasks.max` setting to greater than 1 allows Kafka Connect to enable parallelism and shard relay work for a given Kafka topic across multiple tasks. As message throughput increases, Kafka Connect spawns more tasks, increasing concurrency and thereby increasing total throughput.
A better approach
Compared to existing ways of transmitting data between Kafka and Google Cloud, the connectors are a step-change.
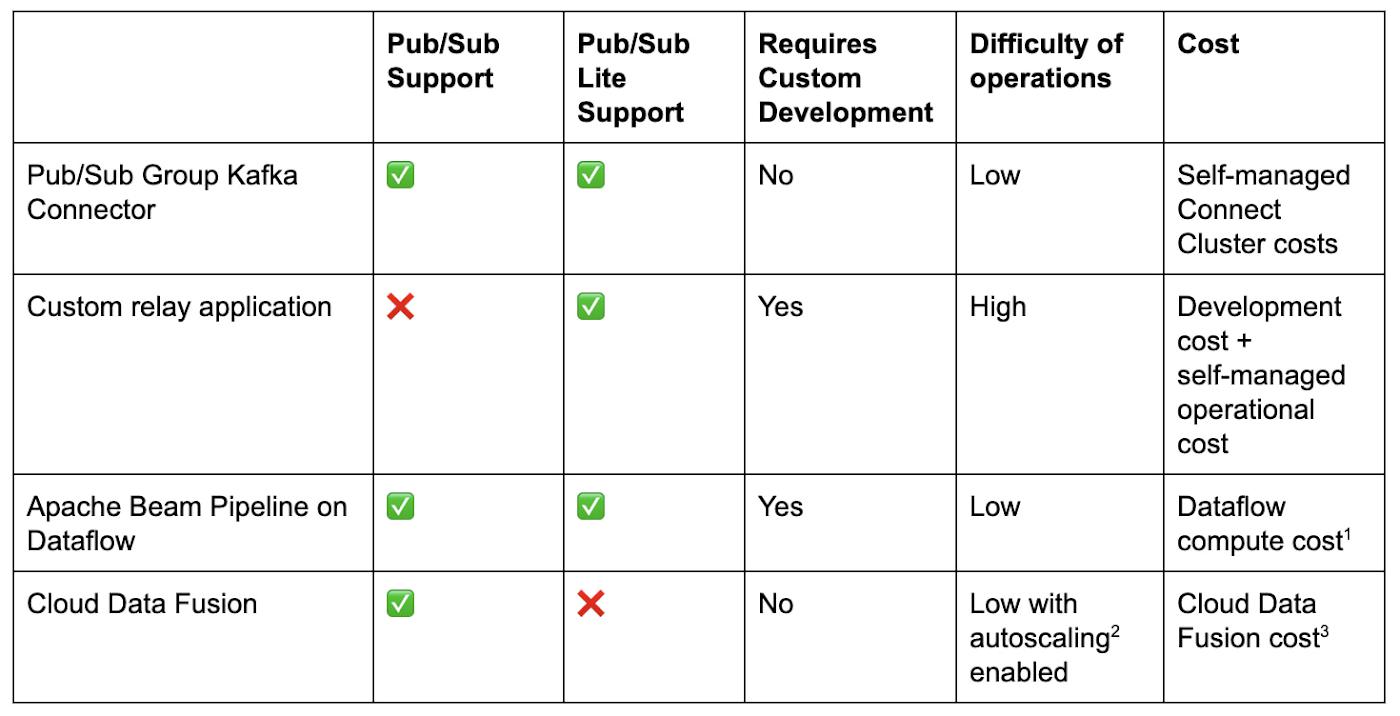
1. Dataflow compute cost. 2. autoscaling. 3. Cloud Data Fusion cost
By: Samarth Singal (Software Engineer) and Tianzi Cai (Developer Relations Engineer)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







