
In Deloitte’s annual “State of AI in the Enterprise” survey, 94% of business leaders identified AI as critical to their organizations’ success over the next five years. That survey also uncovered a 29% increase in the number of organizations struggling to achieve meaningful AI-driven business outcomes. Part of this challenge lies in the ability to capitalize on existing data, in its various formats spread throughout the organization. For example, up to 80% of enterprise information assets are scattered across the organization in text, PDFs, emails, web pages, and other unstructured formats. This includes a wealth of valuable insights embedded within contracts, buried within patient files, recorded in chat transcripts, noted in EHR/CRM text fields, and present in other formats. This wealth of unstructured data is often untapped, as some business leaders may be unaware of the value or unsure how to leverage it.
Challenges: The need to put unstructured data to use more rapidly
Accessing data across various locations and file types and then operationalizing that data for AI usage is usually a cumbersome, manual, time-consuming, and costly process. Individually labeling files to build an adequate dataset to train a machine learning (ML) model is notoriously slow, while human errors and inconsistencies also tend to degrade data quality and negatively impact ML model performance.
From our partners:
Often, analyzing enterprise data requires the expertise of analysts, clinicians, lawyers or other domain specific experts. In highly-regulated industries such as financial services and healthcare, privacy regulations, standards, and other access restrictions make the challenges posed in using unstructured data proportionally higher.
Solution approach
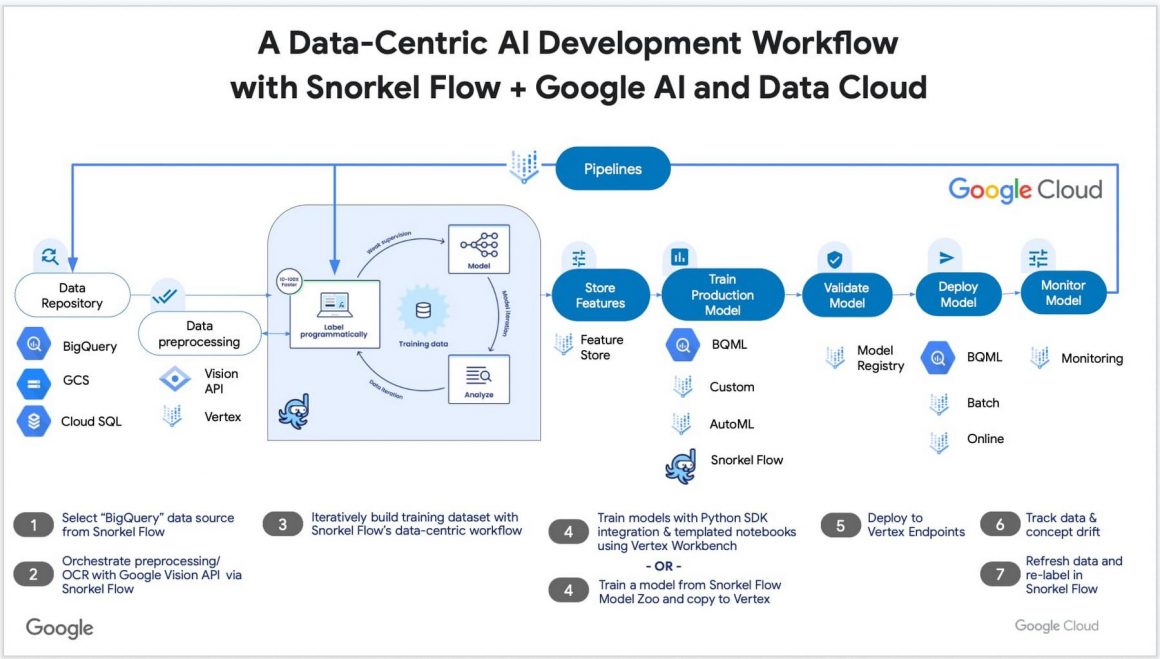
Snorkel AI has teamed with Google Cloud to help organizations transform raw, unstructured data into a format that can be used to train actionable AI-powered models for insights and decision making. By combining Google Cloud services such as BigQuery and Vertex AI with Snorkel AI’s data-centric AI platform for programmatic data curation and preparation, organizations can accelerate AI development 10-100x [1]. Tapping into the value of unstructured data stored in BigQuery and making that data ready for ML training empowers enterprises to incorporate all types of data for training AI models.
Snorkel AI’s data-centric approach unlocks new ways of preparing ML training workloads
Snorkel AI addresses one of the biggest blockers to preparing data for AI development: the massive hand-labeled training datasets needed to prepare data for supervised training of ML models. Snorkel AI overcomes this bottleneck through using a programmatic labeling approach implemented in Snorkel Flow, a novel data-centric AI platform.
Leveraging business logic, and using foundation models as a means of generating labels, data science and ML teams can use Snorkel Flow’s labeling functions to programmatically label data using various sources, including previously-labeled datasets that may have been poorly labeled while encoding knowledge or heuristics from subject matter experts. Snorkel Flow can leverage these multiple data and knowledge sources to label large quantities of unstructured data at scale.
In addition to data scientists, other users in the ML lifecycle, such as ML engineers, can leverage Snorkel Flow to rapidly improve training data quality and model performance using integrated error analysis and model-guided feedback mechanisms to develop more accurate AI applications.
The data-centric AI workflow within Snorkel Flow operates as follows:
- Data scientists, ML engineers, and subject matter experts programmatically label large amounts of data in minutes to hours by creating labeling functions.
- Upon creating labeling functions, Snorkel Flow generates a probabilistic labeled dataset that is used to train a model within the platform.
- Next, data scientists use guided error analysis to analyze the model’s performance deficits. They look for the gaps that facilitate creation of more targeted and relevant labeling assignments. In other words, data scientists and other users specifically work on places where the model is most wrong, or on particular high-value examples, or on commonly confused classes of data.
- Next, users collaboratively iterate on these gaps with internal experts, refining or adding labeling functions as needed to label even more data with which they can again feed into the model for analysis.
- Users repeat this iteration even after deploying a model and monitoring a slice of production data.
- As a result of this loop, the metrics improvements in an AI application are often orders-of-magnitude greater than what can be achieved with model-centric AI and hand-labeled data.
Solution details
Unified access to data stored on Google Cloud
With training data curation and preparation unblocked via programmatic labeling of unstructured data, data scientists can harness the full power of Google’s end-to-end BigQuery ML and/or Vertex AI platforms to fast-track the development of analytics and AI applications. Google Cloud customers can easily deploy Snorkel Flow on their Google Cloud infrastructure using Google Kubernetes Engine (GKE), then consume unstructured, semi-structured or structured data from Google Cloud data services such as BigQuery and Google Cloud Storage (GCS). See the below figure for data sources and integrations.
BigQuery is a serverless, cost-effective, and cross-cloud analytics data warehouse built to address the needs of data-driven organizations. BigQuery breaks down silos across clouds, allowing enterprises to centralize all of their data – structured, semi-structured, and unstructured – in a single secure repository. BigQuery support for unstructured data management includes built-in capabilities to secure, govern, and share unstructured data.
Snorkel Flow + Google Cloud BigQuery
The Snorkel Flow platform integrates natively with BigQuery to streamline and simplify AI development:
- With a few clicks, data scientists can immediately pull relevant data from BigQuery directly into Snorkel Flow using the integrated BigQuery connector.
- Data can then be labeled programmatically using a data-centric AI workflow in Snorkel Flow to quickly generate high-quality training sets over complex, highly variable data. Snorkel Flow includes templates to classify and extract information from unstructured text, native PDFs, richly formatted documents, HTML data, conversational text, and more.
- Newly labeled datasets can then be used to either train custom ML models or fine-tune pre-built models.
- Labeled data can be loaded back into the BigQuery environment as structured data.
Real-world impact
Top U.S. banks, healthcare, insurance, and other Fortune 500 organizations have used Snorkel Flow to extract information from complex documents such as 10-K reports, clinical trial protocols, technical manuals, rent rolls, legal contracts, and more. One Fortune 500 telecom provider and long-time Google Cloud customer, for example, uses Snorkel Flow to classify encrypted network data flows into key application categories. Using Snorkel Flow’s comprehensive data exploration and error analysis tools, the telco successfully trained 200,000 labels in a matter of hours, achieving 25% better accuracy compared to an internal ground truth baseline.
Google and Snorkel AI have collaborated on a Snorkel research project for Google’s internal use. Google used early versions of Snorkel’s core technology to tackle data labeling for content, product, and event classification problems that were not amenable to manual labeling due to the rapid variations in the labels. Using Snorkel, Google condensed a six month process involving thousands of hand-labeled examples into just 30 minutes and built content classification models that achieved an average performance improvement of 52% [2, 3, 4].
Better together: Snorkel AI + Google Cloud
Together, Google Cloud and Snorkel AI enable Fortune 500 enterprises, federal agencies, and other AI innovators to operationalize unstructured data to build and and accelerate AI applications to solve their most critical challenges
To learn more, schedule a custom demo tailored to your use case with Snorkel AI ML experts or watch one of the below recent presentations:
- Accelerate AI development by eliminating the pain of manual labeling, delivered by Snorkel AI co-founder Henry Ehernberg as part of a Google Cloud BigQuery Innovation event
- Promises and Compromises of Responsible Generative AI Model Adoption in the Enterprise, delivered by Google Director, Cloud Partner Engineering, Dr. Ali Arsanjani at Snorkel’s Foundation Model Summit
[1] Snorkel AI documented customer results reflect 45x, 52%, 98% and similar improvements vs hand-labeling https://snorkel.ai/case-studies/
[2] Case study on Google’s use of Snorkel’s core technology: https://snorkel.ai/google-content-classification-models-case-study/
[3] Harnessing Organizational Knowledge for Machine Learning: https://ai.googleblog.com/2019/03/harnessing-organizational-knowledge-for.html
[4] Snorkel DryBell: A Case Study in Deploying Weak Supervision at Industrial Scale: https://arxiv.org/abs/1812.00417
By: Dr. Ali Arsanjani (Director, Cloud Partner Engineering, Google) and Devang Sachdev (VP of Marketing, Snorkel.ai)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







