Greetings everyone! Today we would like to share our experience using Google Kubernetes Engine to manage our Kubernetes clusters. We’ve been using it for the latest three years in production and are pleased that we no longer have to worry about managing these clusters ourselves.
Currently, we have all our test environments and unique infrastructure clusters under the control of Kubernetes. Today, we want to talk about how we encountered an issue on our test cluster and how we hope this article will save others time and effort.
From our partners:
We must provide information about our test infrastructure to understand our problem fully. We have more than five permanent test environments and are deploying environments for developers on request. The number of modules on weekdays reaches 6000 during the day and continues to grow. Since the load is unstable, we pack modules very tightly to save on costs, and reselling resources is our best strategy.

Slack notification KubeAPIErrorsHigh from Production
This configuration worked well for us until one day when we received an alert and could not delete a namespace. The error message we received regarding the namespace deletion was:
$ kubectl delete namespace arslanbekov
Error from server (Conflict): Operation cannot be fulfilled on namespaces "arslanbekov": The system is ensuring all content is removed from this namespace. Upon completion, this namespace will automatically be purged by the system.
Even using the force deletion option did not resolve the issue:
$ kubectl get namespace arslanbekov -o yaml
apiVersion: v1
kind: Namespace
metadata:
...
spec:
finalizers:
- kubernetes
status:
phase: Terminating
To resolve the stuck namespace issue, we followed a guide. Still, this temporary solution was not ideal as our developers should have been able to create and delete their environments at will, using the namespace abstraction.
Determined to find a better solution, we decided to investigate further. The alert indicated a metrics problem, which we confirmed by running a command:
$ kubectl api-resources --verbs=list --namespaced -o name
error: unable to retrieve the complete list of server APIs: metrics.k8s.io/v1beta1: the server is currently unable to handle the request
We discovered that the metrics-server pod was experiencing an out-of-memory (OOM) error and a panic error in the logs:
apiserver panic'd on GET /apis/metrics.k8s.io/v1beta1/nodes: killing connection/stream because serving request timed out and response had been started
goroutine 1430 [running]:
The reason was in limits for the pod’s resources:

The container was encountering these issues due to its definition, which was as follows (limits block):
resources:
limits:
cpu: 51m
memory: 123Mi
requests:
cpu: 51m
memory: 123Mi
The issue was that the container was allocated only 51m CPU, which is roughly equivalent to 0.05 of one core CPU, and this was not enough to handle metrics for such a large number of pods. Primarily the CFS scheduler is used.
Usually, fixing such issues is straightforward and involves simply allocating more resources to the pod. However, in GKE, this option is not available in the UI or via the gcloud CLI. This is because Google protects the system resources from being modified, which is understandable considering that all management is done on their end.
We discovered that we were not the only ones facing this issue and found a similar problem where the author tried to change the pod definition manually. He was successful, but we were not. When we attempted to change the resource limits in the YAML file, GKE quickly rolled them back.
We needed to find another solution.
Our first step was to understand why the resource limits were set to these values. The pod consisted of two containers: the metrics-server and the addon-resizer. The latter was responsible for adjusting resources as nodes were added or removed from the cluster, acting like a caretaker for the cluster’s vertical autoscale.
Its command line definition was as follows:
command:
- /pod_nanny
- --config-dir=/etc/config
- --cpu=40m
- --extra-cpu=0.5m
- --memory=35Mi
- --extra-memory=4Mi
...
In this definition, CPU and memory represent the baseline resources, while extra-cpu and extra-memory represent additional resources per node. The calculations for 180 nodes would be as follows:
0.5m * 180 + 40m=~130m
The same logic is applied to the memory resources.
Unfortunately, the only way to increase resources was by adding more nodes, which we did not want to do. So, we decided to explore other options.
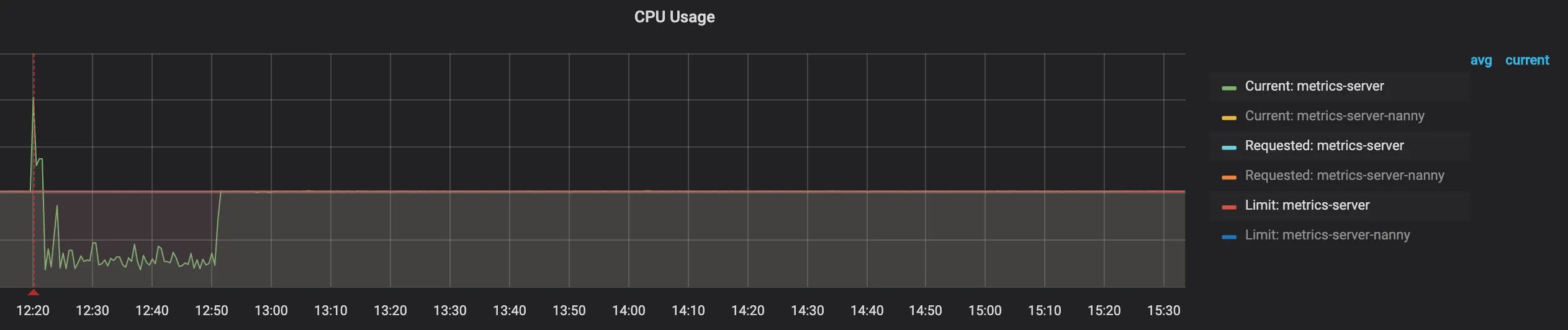
Despite not being able to resolve the issue entirely, we wanted to stabilize the deployment as quickly as possible. We learned that some properties in the YAML definition could be changed without being rolled back by GKE. To address this, we increased the number of replicas from 1 to 5, added a health check, and adjusted the rollout strategy according to this article.
These actions helped to reduce the load on the metrics-server instance and ensured that we always had at least one working pod that could provide metrics. We took some time to reconsider the problem and refresh our thoughts. The solution ended up being simple and obvious in retrospect.
We delved deeper into the internals of the addon-resizer and discovered that it could be configured through a config file and command line parameters. At first glance, it seemed that the command line parameters should override the config values, but this was not the case.
Upon investigating, we found that the config file was connected to the pod through the command line parameters of the addon-resizer container:
--config-dir=/etc/config
The config file was mapped as a ConfigMap with the name metrics-server-config in the system namespace, and GKE does not roll back this configuration!
We added resources via this config as follows:
apiVersion: v1
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
baseCPU: 100m
cpuPerNode: 5m
baseMemory: 100Mi
memoryPerNode: 5Mi
kind: ConfigMap
metadata:
And it worked! This was a victory for us.
We left two pods with health checks and a zero-downtime strategy in place while the cluster was resizing, and we did not receive any more alerts after making these changes.
Conclusions
- You may encounter issues with the metrics-server pod if you have a densely packed GKE cluster. The default resources allocated to the pod may not be sufficient if the number of pods per node is close to the limit (110 per node).
- GKE protects its system resources, including system pods, and direct control over them is impossible. However, sometimes it is possible to find a workaround.
- It’s important to note that there is no guarantee that the solution will still work after future updates. We have only encountered these issues in our test environments, where we have an overselling strategy for resources, so while it is frustrating, we can still manage it.
Source: Cyberpogo
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!






{kind=link}
{kind=link}