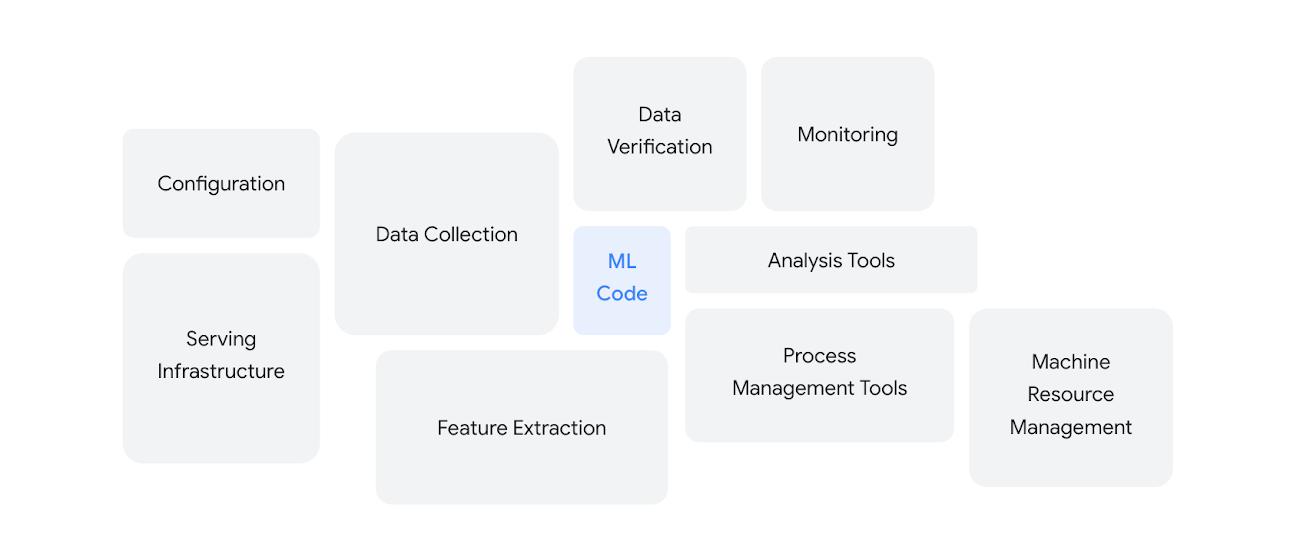
Bringing AI models to a production environment is one of the biggest challenges of AI practitioners. Much of the discussions in the AI/ML space revolve around model development. As shown in this diagram from the canonical Google paper “Hidden Technical Debt in Machine Learning Systems”, the bulk of activities, time and expense in building and managing ML systems is not in Model training, but in the myriad ancillary tasks that make an ML system ‘work’.
Another very interesting whitepaper authored by Google is the Practitioners guide to MLOps: A framework for continuous delivery and automation of machine learning. In addition to thought leadership in the AI/ML space, Google Cloud provides a rich set of tools to assist Data Scientists and ML engineers on their journey from prototyping to production.
Despite the growing recognition of AI/ML as a crucial pillar of digital transformation, successful deployments and effective operations are a bottleneck for getting value from AI. Only one in two organizations has moved beyond pilots and proofs of concept.
In this article, our goal is to take best practices provided in the aforementioned resources and bring them to a Google Cloud project. We are going to discuss everything BUT model development, since the focus here is on MLOps and the tooling options for encapsulating your ML workflow into a pipeline. This notebook, available in our Github repository, will walk you through a Vertex Pipeline construction that will take you from model ideation to model deployment.
We’ll leave the actual model creation and optimization processes to the experts: BigQuery ML and AutoML Tables. Even better, we’ll train two different models and select the one that performs better with our dataset. Before we dive into the pipeline, let’s take a quick look at the tools we’ll rely on for model development:
BigQuery ML (BQML) lets you create and execute machine learning models in BigQuery using standard SQL queries while leveraging BigQuery’s petabyte scale. BigQuery ML democratizes machine learning by letting SQL practitioners build models using existing SQL tools and skills.
AutoML Tables is even more hands-off. You don’t need to write any model code in order to reap the benefits from a very advanced machine learning framework. AutoML automatically experiments with many different model architectures and comes up with a state-of-the-art model that addresses your needs.
The pipeline
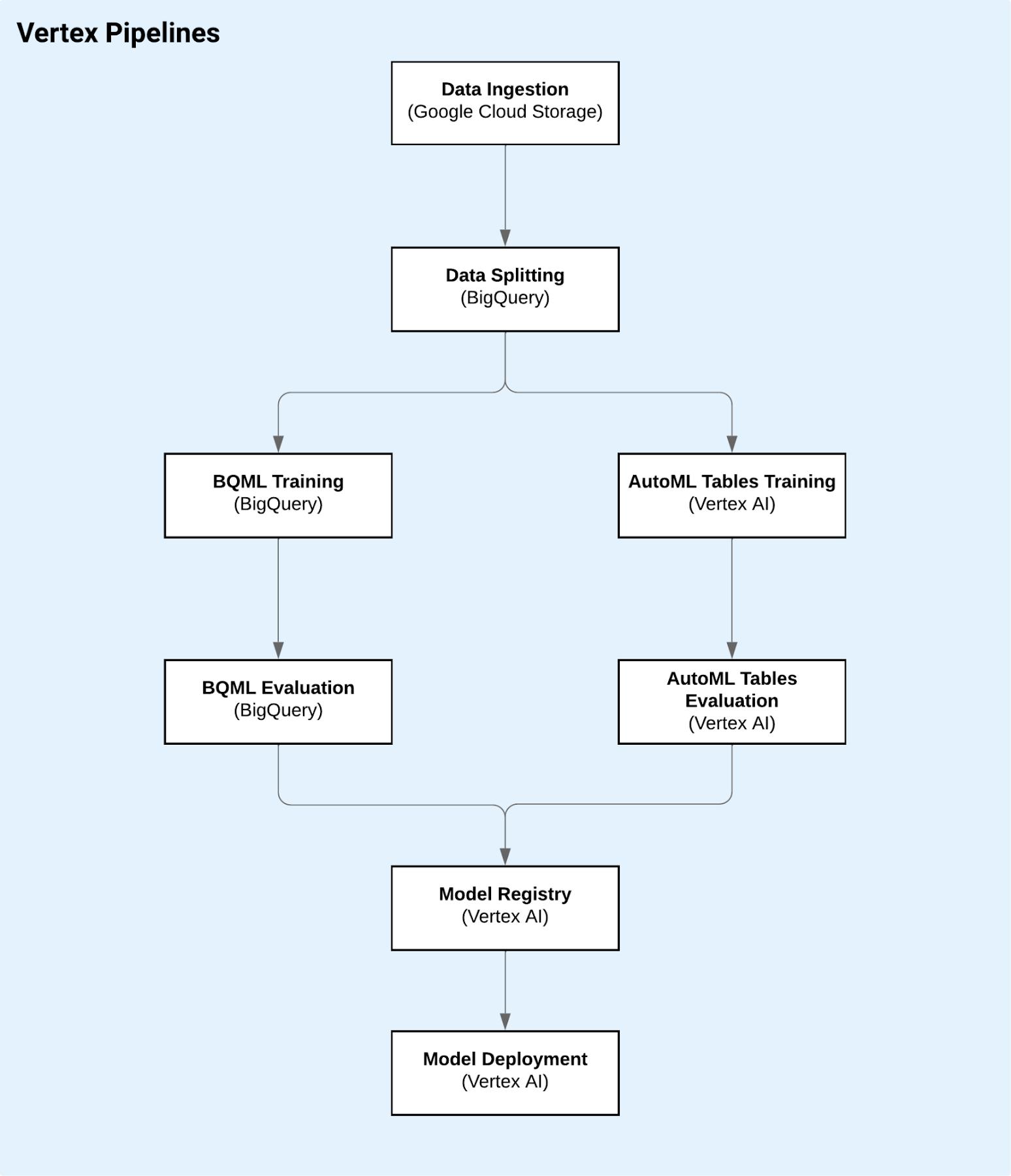
In order to piece together all the steps of this workflow, we are going to use Vertex Pipelines. Vertex Pipelines lets you orchestrate your ML workflows in a serverless manner. Before Vertex Pipelines can orchestrate your ML workflow, you must describe your workflow as a pipeline. In our example we are going to use the Kubeflow Pipelines v2 SDK.
The beauty of using Vertex AI for your Machine Learning workloads is that the solutions you use throughout your pipeline workflow talk to one another. When you run a pipeline, Vertex AI will automatically track metadata & lineage for all the artifacts generated during the pipeline execution. The Pipeline Metadata can help you answer questions like:
- Which dataset was used to train a certain model?
- Which of my organization’s models have been trained using a certain dataset?
- Which run produced the most accurate model, and which hyperparameters were used to train that model?
In the image below, we are able to trace a specific model all the way back to the raw .csv file used to create the dataset.

The data

Abalones are marine snails and our goal for this exercise will be to predict the age of a snail based on the physical dimensions of its shell. Our dataset, provided by the University of California, contains 4,177 instances, with one categorical and six numerical features. We will treat this as a regression problem, as we are going to predict the number of rings that the snail has based on its measurements. With the number of rings of these animals, we can infer their ages.
The journey begins with a .csv file hosted on a Google Cloud Storage (GCS) bucket. Once you have access to the data, it is now time to import it into BigQuery, Google’s Data Warehouse. Today, we’re splitting the dataset in 3 subsets: train (80%), evaluate (10%), test (10%). The training and evaluation slices will be used to create and optimize the model and the test portion will be used for the model selection. This article describes best practices for creating training data.
Model training
You can build models with BQML using just a few lines of SQL. In this demo, we will use a linear regression model on BQML. However, you can be creative with other model architectures, such as Deep Neural Networks, Boosted Trees etc. For a full list of models supported by BQML, look here: End-to-end user journey for each model. Even though it is not covered in this article, it is also worth mentioning BQML supports hyperparameter tuning when training ML models, with very advanced features such as Neural Architecture Search.
Vertex Pipelines offers several pre-built components to simplify the process of creating and orchestrating Kubeflow pipelines. All you have to do is specify a few parameters, such as the dataset you are using and the target column you are trying to predict. To illustrate this, we will use the AutoMLTabularTrainingJobRunOp and BigqueryCreateModelJobOp.
Before starting the AutoML model training, you will need to create a Vertex Dataset using the BigQuery table created earlier in the pipeline. This can be done using the TabularDatasetCreateOp pre-built component. Once the dataset is created, you can use the AutoMLTabularTrainingJobRunOp to train your model.
from google_cloud_pipeline_components import \aiplatform as vertex_pipeline_components# Creates a Vertex AI Tabular dataset using a pre-built-component.dataset_create_op = vertex_pipeline_components.TabularDatasetCreateOp(project=project,location=region,display_name=DISPLAY_NAME,bq_source=split_datasets_op.outputs["dataset_bq_uri"],)# Trains an AutoML Tables model using a pre-built-component.automl_training_op = vertex_pipeline_components.AutoMLTabularTrainingJobRunOp(project=project,location=region,display_name=f"{DISPLAY_NAME}_automl",optimization_prediction_type="regression",optimization_objective="minimize-rmse",predefined_split_column_name="split_col",dataset=dataset_create_op.outputs["dataset"],target_column="Rings",column_transformations=[{"categorical": {"column_name": "Sex"}},{"numeric": {"column_name": "Length"}},[…] # More features{"numeric": {"column_name": "Rings"}},],)
For the BQML portion, the first step is to define a SQL query according to BQML’s CREATE MODEL statement. As you can see below, you have to specify the feature columns and the target label (Rings in this case):
def _query_create_model(project_id:str, bq_dataset: str, training_data_uri: str, model_name: str):model_uri = f"{project_id}.{bq_dataset}.{model_name}"model_options = """OPTIONS( MODEL_TYPE='LINEAR_REG',input_label_cols=['Rings'],[...])"""query = f"""CREATE OR REPLACE MODEL`{model_uri}`{model_options}ASSELECTSex,Length,[...] # More featuresRings # our label columnFROM`{training_data_uri}`;"""return query
Once you have created the SQL query, you can use the BigqueryCreateModelJobOp pre-built component and let Vertex Pipeline manage the underlying resources for you.
from google_cloud_pipeline_components.experimental import bigquery as bq_components# Generates the query to create a BQML using a static function.create_model_query = _query_create_model(project, bq_dataset, split_datasets_op.outputs['dataset_uri'])# Builds BQML model using pre-built-component.bqml_create_op = bq_components.BigqueryCreateModelJobOp(project=project,location=bq_location,query=create_model_query)
Model evaluation
Once the models have been trained using BQML and AutoML we need to answer the first evaluation question: which model performs better on the test dataset?
AutoML Tables generates evaluation metrics and displays them directly on the UI. BQML offers a pre-built component (BigqueryEvaluateModelJobOp), which collects metrics such as mean_absolute_error and mean_squared_log_error. Our first task is to gather these metrics programmatically and compare them to one another. On the notebook you will find the two custom components we created to showcase how you can interact with these services.
The metric we chose to evaluate the performance of the models was root mean squared error (RMSE). These metrics are very important to analyze the model performance, so we will want to make sure we log some Metadata that can be used to understand the performance of the pipeline later on. Fortunately, Vertex Pipelines allows you to log metadata and compare successive runs of your pipeline. This can be useful to compare different model architectures, different datasets, or even changes you will eventually make to your training code.
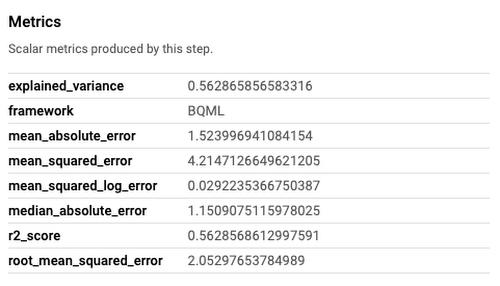
Once we know which model is the best one, we need to ensure that it meets the minimum requirements in order to be pushed to production. We did this by setting a threshold for deployment, for this demonstration we chose RMSE <= 2.5. If the best performing model has an RMSE lower than the threshold, then we will proceed to the next steps on the pipeline.
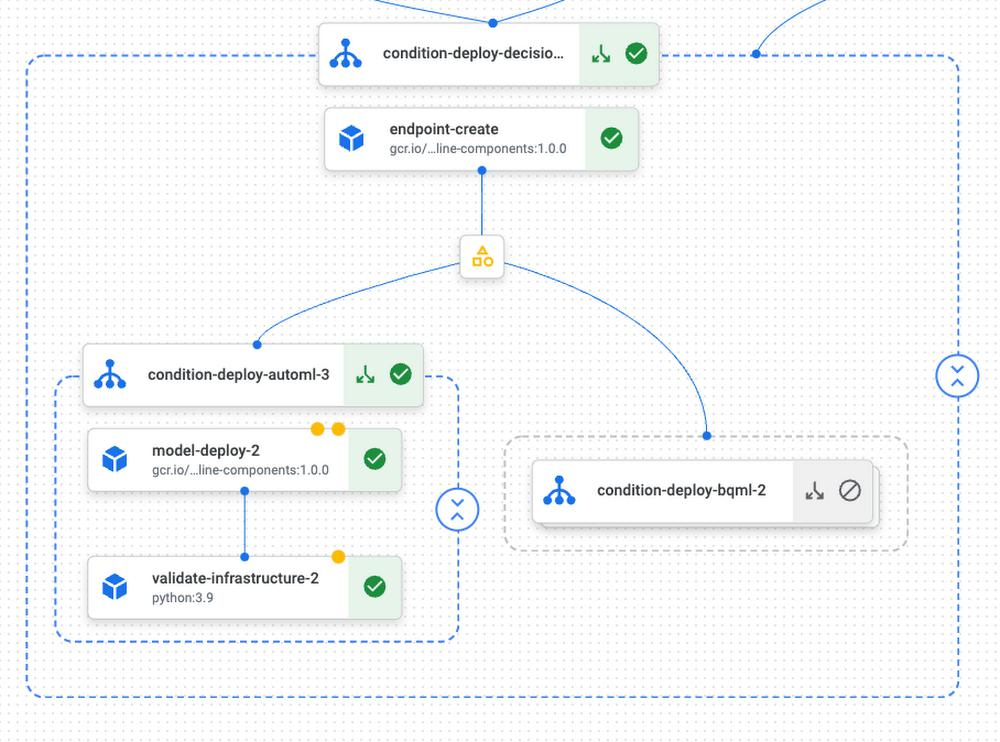
Model deployment
The model evaluation step should give us the best performing model. Now it is time to deploy it to an endpoint and serve it. To do that, we will use Vertex Prediction. Vertex Prediction makes it easy to deploy models into production for online serving via HTTP. Both the BQML and the AutoML models come with pre-built TensorFlow images so you can serve them without having to worry about creating a container.
Using pre-built components simplifies the process of creating a new endpoint and deploying a model to it. The code snippet below shows how you can concatenate two conditions in your pipeline to answer the following questions:
- Does our best performing model meet our minimum accuracy threshold?
- If so, which model should I deploy to production: AutoML or BQML?
# If the deploy condition is True, then it deploys the best model.with dsl.Condition(best_model_task.outputs["deploy_decision"] == "true",name="deploy_decision",):# Creates a Vertex AI endpoint using a pre-built-component.endpoint_create_op = vertex_pipeline_components.EndpointCreateOp(project=project,location=region,display_name=endpoint_display_name,)#endpoint_create_op.after(best_model_task)# In case the BQML model is the best...with dsl.Condition(best_model_task.outputs['best_model'] == 'bqml',name="deploy_bqml",):# Deploys the BQML model (now on Vertex AI) to the recently created endpoint using a pre-built component.model_deploy_bqml_op = vertex_pipeline_components.ModelDeployOp(endpoint=endpoint_create_op.outputs["endpoint"],model=bqml_vertex_model,deployed_model_display_name=DISPLAY_NAME + "_best_bqml",dedicated_resources_machine_type="n1-standard-2",dedicated_resources_min_replica_count=2,dedicated_resources_max_replica_count=2,traffic_split={'0': 100} #newly deployed model gets 100% of the traffic).set_caching_options(False)
At this stage, your model is ready for production and is now accepting prediction requests. To test this, we added the validate_infra component, which makes an HTTP request to the newly deployed model. You can see how we did this by searching for validate_infrastructure on the notebook.
Conclusion
In this article, we described some of the challenges AI practitioners face when bringing ideas to production. In our notebook, we used 14 components spanning multiple Google Cloud tools that can be used to develop a machine learning pipeline:
- Google Cloud Storage
- BigQuery
- Vertex Pipelines
- BigQuery ML (BQML)
- AutoML Tables
- Vertex ML Metadata
- Vertex Prediction
Next steps
Give it a try. Run the notebook and see with your own eyes the benefits of Vertex AI. The tight integration of multiple GCP services allows you to bring a model from ideation to production with a lot less effort so you can increase your ML productivity.
Thank you for reading! Have a question or want to chat? Find me on LinkedIn.
By: Rafa Carvalho (Customer Engineer, Machine Learning)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!