- The first problem is a data bottleneck. There’s only one team, sometimes just one person or system that can access the data, so every request for data must go through them. The central team is also asked to interpret the use cases for that data, and make judgments on the data assets required without having much domain knowledge about the data. This situation causes a lot of frustration for data analysts, data scientists and ultimately any business user who requires data for decision making. Over time, people give up on waiting and make decisions without data.
- Data chaos is the other thing that happens, because people get fed up with the bottleneck. People copy the most relevant data they can find, not knowing if it is the best option available to them. This data duplication (and subsequent uses) can happen enough times that users lose track of the source of truth of the data, its freshness, and what the data means. Aside from being a data governance nightmare, this creates unnecessary work and a waste of system resources, leading to increased complexity and cost. It slows everyone down and erodes trust in data.
To address the above challenges, organizations may wish to give business domains autonomy in generating, analyzing, and exposing data as data products, as long as these data products have a justifiable use case. The same business domains would own their data products throughout their entire lifecycle.
From our partners:
In this model, the need for a central data team remains, although without ownership of the data itself. The goal of the central team is to support users in generating value from data by enabling them to autonomously build, share, and use data products. The central team does this via a set of standards and best practices for domains to build, deploy, and maintain data products that are secure and interoperable, governance policies to build trust in these products (and the tooling to assist domains to adhere to them), and a common platform to enable self-serve discovery and use of data products by domains. Their job is made easier by an already self-service and serverless data platform.
In 2019, Zhamak Dehghani introduced to the world the notion of Data Mesh, applying a DevOps mentality that was developed through infrastructure modernization to data. Coincidentally, this is how Google has been operating internally over the last decade. A decentralized data platform is achieved by using BigQuery behind the scenes. As a result, instead of moving data from domains into a centrally owned data lake or platform, domains can host and serve their domain datasets in an easily consumable way. The business area generating data becomes responsible for owning and serving their datasets for access by teams with a business need for that data. We have been working with numerous customers over the last two years who are eager to try Data Mesh out for themselves.
We have written about how to build a data mesh on Google Cloud in detail: you can read the full whitepaper here, and a follow up guide to implementation here. In a nutshell, Data Mesh is an architectural paradigm that decentralizes data ownership into the teams that have the greatest business context about that data. These teams take on the responsibility of keeping data fresh, trustworthy, and discoverable by data consumers elsewhere in the company. Data effectively becomes a product, owned and managed within a domain by the teams who know it best. For this approach to work, governance also needs to be federated across the domains, so that management of data and access can be customized, within boundaries, by the data owners as well.
The idea of a Data Mesh is alluring; it combines business needs with technology in a way we don’t typically see. It promises a solution to help break down organizational barriers in extracting value from data. To do this, companies must adopt four principles of Discoverability, Accessibility, Ownership, and (Federated) Governance, which require a coordinated effort across technical and business unit leadership. In practice, each group that owns a data domain across a decentralized organization may need to employ a hybrid group of data workers to take on the increased data curation, data management, data engineering, and data governance tasks required to own and maintain data products for that domain. From day-to-day operations of the team to employee management and performance evaluations, this significantly impacts an organization, so it is not a small change to make and needs buy-in from cross-functional stakeholders and leadership across the company.
It is essential that the offices of the Chief Information Security Officer (CISO), Chief Data Officer (CDO), and Chief Information Officer (CIO) are engaged as the key stakeholders as early as possible to enable business units to manage data products in addition to their business-as-usual activities. There must also be business unit leaders willing to have their teams assume this new responsibility. If key stakeholders are less involved in your organizational planning, this may result in inadequate resources being allocated and the overall project failing. Fundamentally, Data Mesh is not just a technical architecture but rather an operating model shift towards distributed ownership of data and autonomous use of technology to enable business units to optimize locally for agility. Thinh Ha’s article on organizational features that are anti-candidates for Data Mesh is a must-read if you are considering this approach at your company.
At Google Cloud, we have built managed services to help companies like Delivery Hero modernize their analytics stack and implement Data Mesh practices.
Data Mesh promises domain-oriented, decentralized data ownership and architecture where each domain is responsible for creating and consuming data – which in turn allows faster scaling of the number of data sources and use cases. You can achieve this by having federated computation and access layers while keeping your data in BigQuery and BigLake. Then you can join data from different domains, even raw data if needed, with no duplication or data movement. Analytics Hub is then used for discovery together with Dataplex. In addition, Dataplex provides the ability to handle centralized administration and governance. This is further complemented by having Looker, which fits in perfectly as it allows scientists, analysts, and even business users to access their data with a single semantic model. This universal semantic layer abstracts data consumption for business users and harmonizes data access permissions.
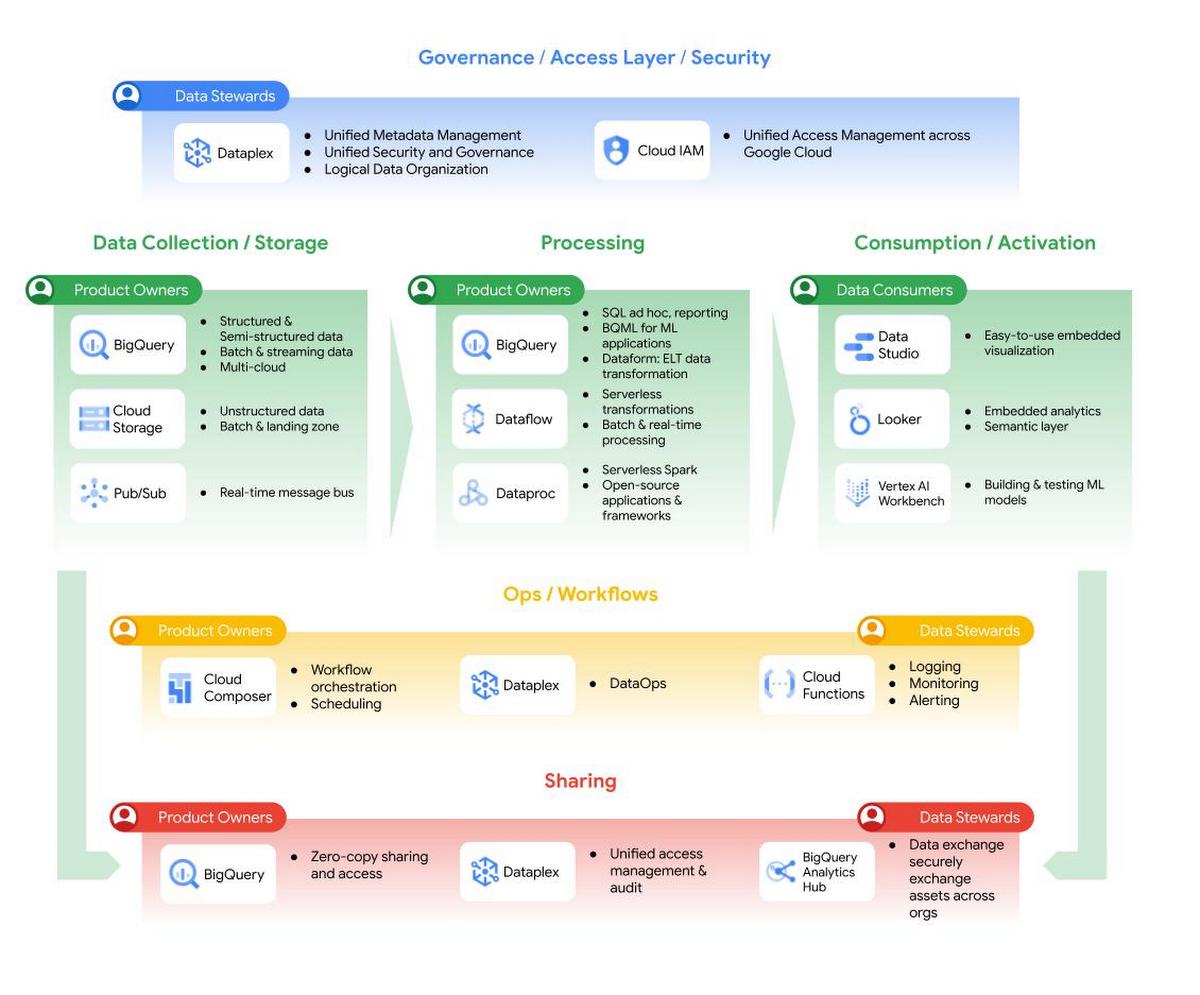
Figure 1: Data Mesh in Google’s Data Cloud
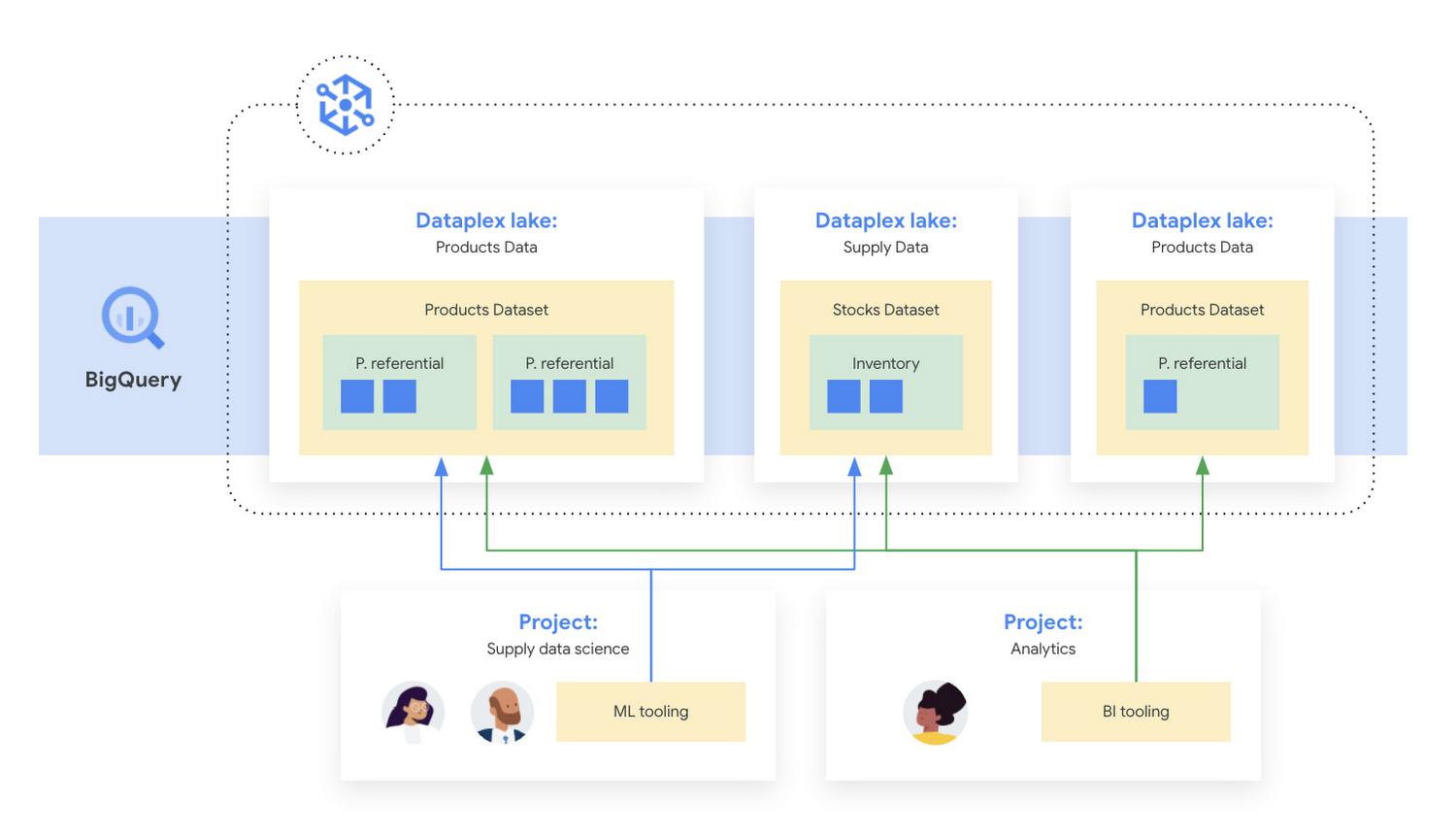
Figure 2: Data Mesh example architecture
Acknowledgements
It was an honor and privilege to work on this with Diptiman Raichaudhuri, Sergei Lilichenko, Shirley Cohen, Thinh Ha, Yu-lm Loh, Johan Pcikard, Yu-lm Loh and Maxime Lanciaux for support, work they have done and discussions.
By: Firat Tekiner (Product Management, Google) and Susan Pierce (Senior Product Manager)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!