Why Scio
SCIO provides high level abstraction for developers and is preferred for following reasons:
From our partners:
- Striking balance between concise and performance. Pipeline written in Scala are concise compared to java with similar performance
- Easier migration for Scalding/Spark developers due to similar semantics compared to Beam API thereby avoiding a steep learning curve for developers.
- Enables access to a large ecosystem of infrastructure libraries in Java e.g. Hadoop, Avro, Parquet and high level numerical processing libraries in Scala like Algebird and Breeze.
- Supports Interactive exploration of data and code snippets using SCIO REPL
Reference Patterns
Let us checkout few concepts along with examples:
1. Graph Composition
If you have a complex pipeline consisting of several transforms, the feasible approach is tocompose the logically related transforms into blocks. This would make it easy to manageand debug the graph rendered on dataflow UI. Let us consider an example using popularWordCount pipeline.
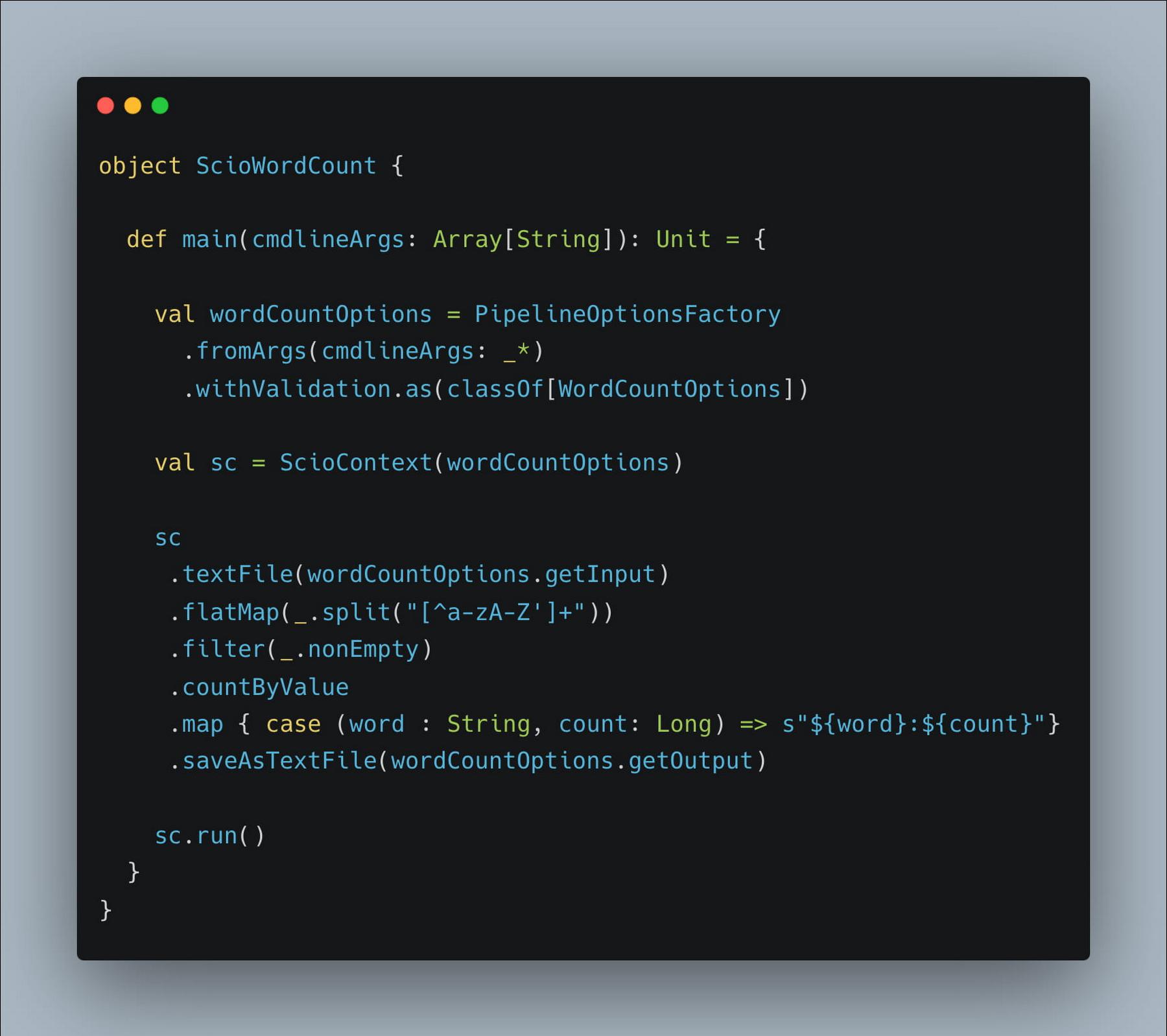
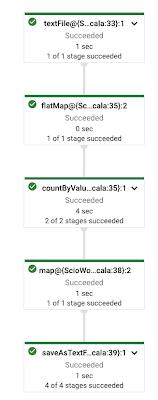
Fig: Word Count Pipeline without Graph Composition
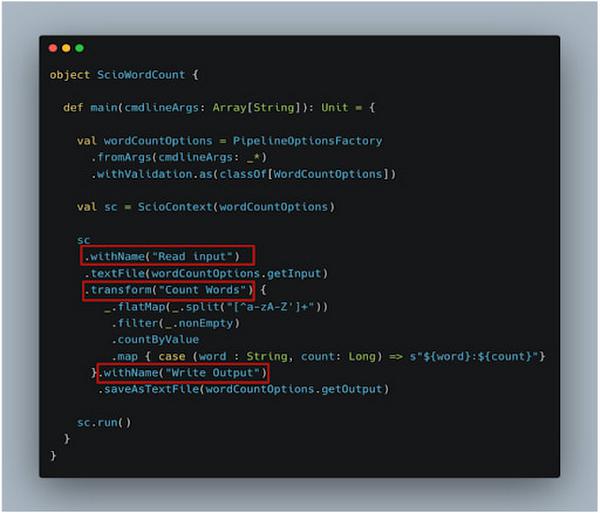

Fig: Word Count Pipeline with Graph Composition
2. Distributed Cache
Distributed Cache allows to load the data from a given URI on workers and use thecorresponding data across all tasks (DoFn’s) executing on the worker. Some of the commonuse cases are loading serialized machine learning model from object stores like GoogleCloud Storage for running predictions, lookup data references etc.
Let us checkout an example that loads lookup data from CSV file on worker duringinitialization and utilizes to count the number of matching lookups for each input element.
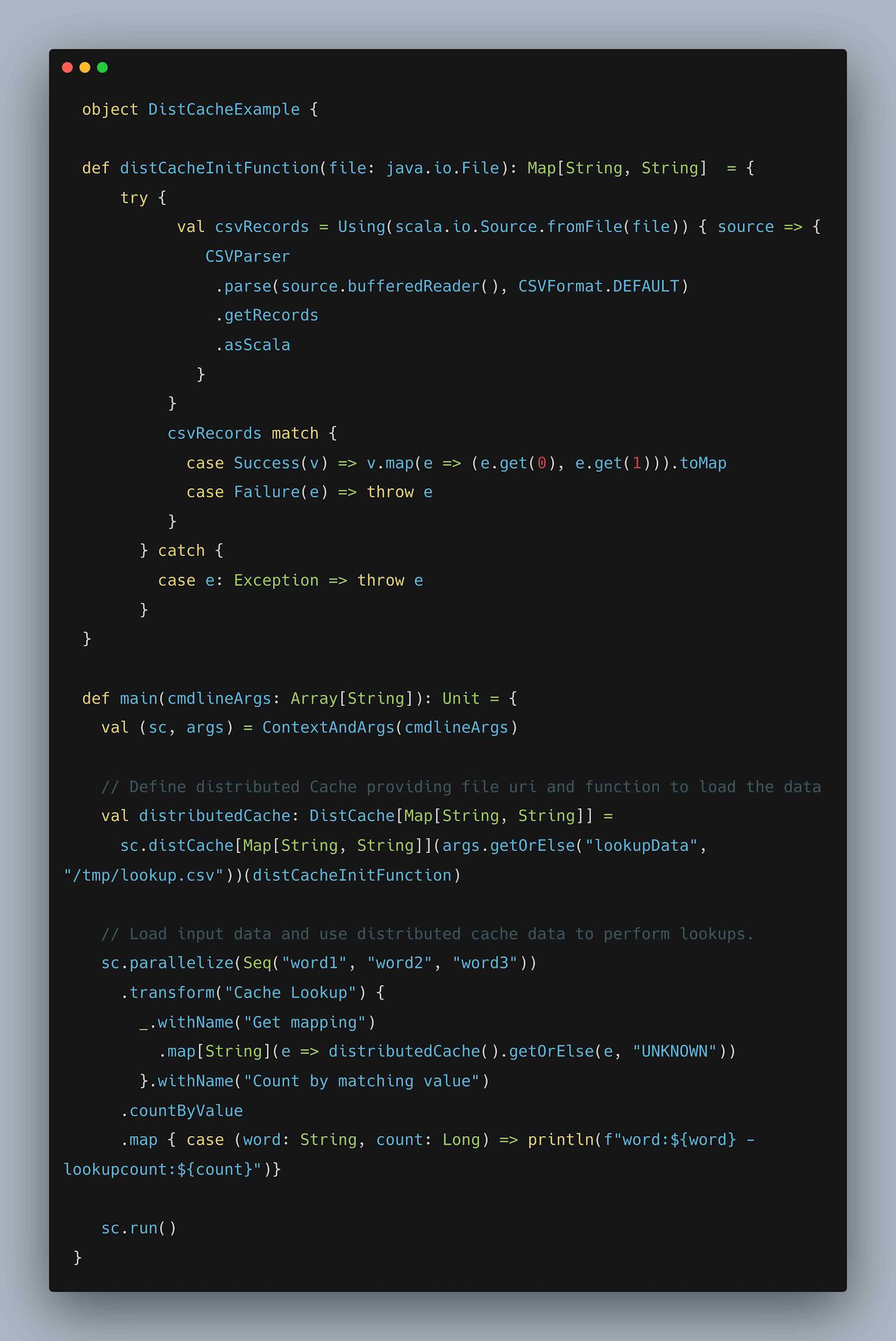
Fig: Example demonstrating Distribute Cache
3. Scio Joins
Joins in Beam are expressed using CoGroupByKey while Scio allows to express variousjoin types like inner, left outer and full outer joins through flattening the CoGbkResult.
Hash joins (syntactic sugar over a beam side input) can be used, if one of the dataset isextremely small (max ~1GB) by representing a smaller dataset on the right hand side. Sideinputs are small, in-memory data structures that are replicated to all workers and avoidsshuffling.
MultiJoin can be used to join up to 22 data sets. It is recommended that all data sets beordered in descending size, because non-shuffle joins do require the largest data sets to be onthe left of any chain of operators
Sparse Joins can be used for cases where the left collection (LHS) is much larger than theright collection (RHS) that cannot fit in memory but contains a sparse intersection of keysmatching with the left collection . Sparse Joins are implemented by constructing aBloom filter of keys from the right collection and split the left side collection into 2partitions. Only the partition with keys in the filter go through the join and the rest areeither concatenated (i.e Outer join) or discarded (Inner join). Sparse Join is especially usefulfor joining historical aggregates with incremental updates.
Skewed Joins are a more appropriate choice for cases where the left collection (LHS) ismuch larger and contains hotkeys. Skewed join uses Count Mink Sketch which is aprobabilistic data structure to count the frequency of keys in the LHS collection. LHS ispartitioned into Hot and chill partitions. While the Hot partition is joined withcorresponding keys on RHS using a Hash join, chill partition uses a regular join and finallyboth the partitions are combined through union operation.
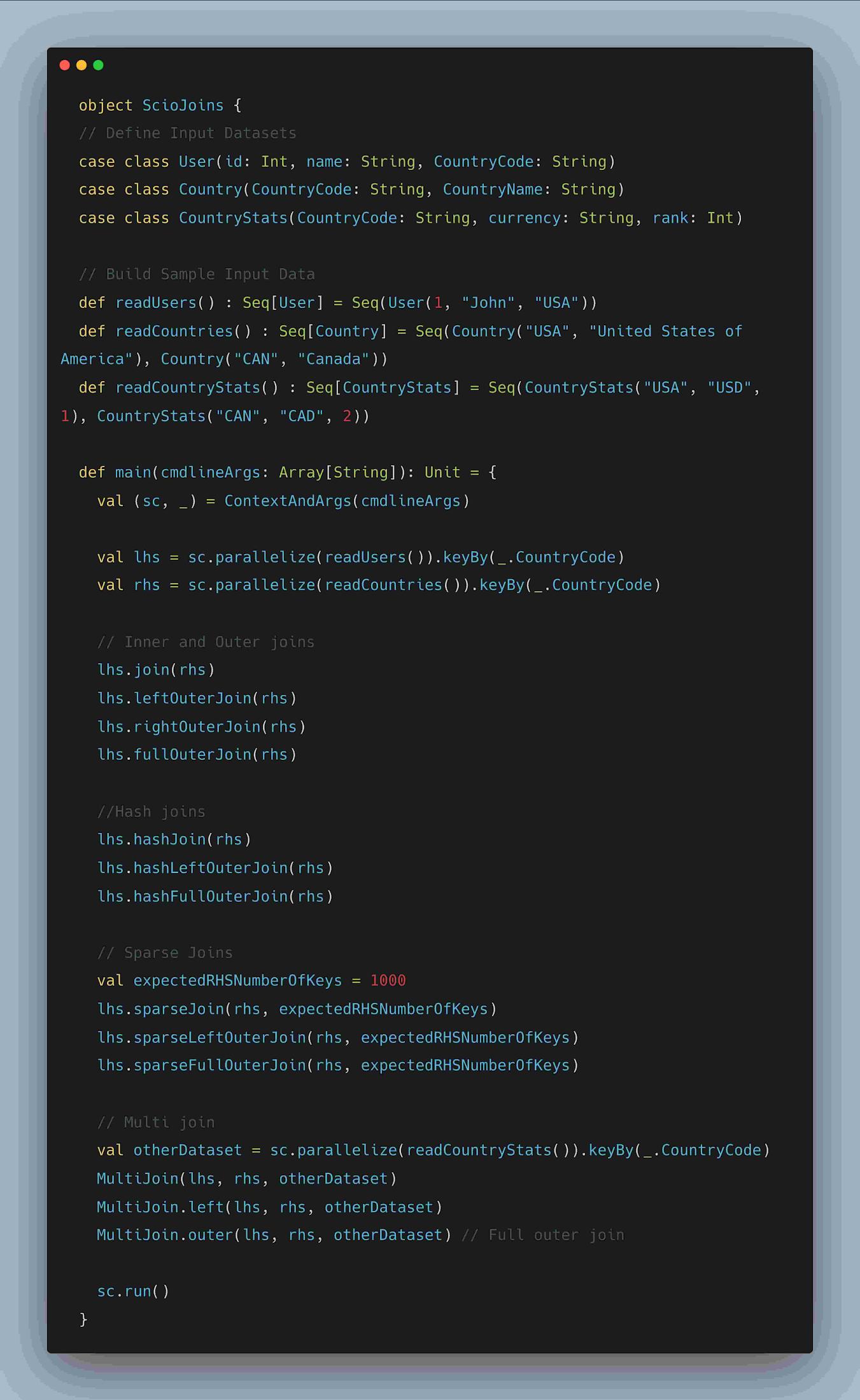
Fig: Example demonstrating Scio Joins
4. AlgeBird Aggregators and SemiGroup
Algebird is Twitter’s abstract algebra library containing several reusable modules for parallelaggregation and approximation. Algebird Aggregator or Semigroup can be used withaggregate and sum transforms on SCollection[T] or aggregateByKey and sumByKeytransforms on SCollection[(K, V)]. Below example illustrates computing parallelaggregation on customer orders and composition of result into OrderMetrics class
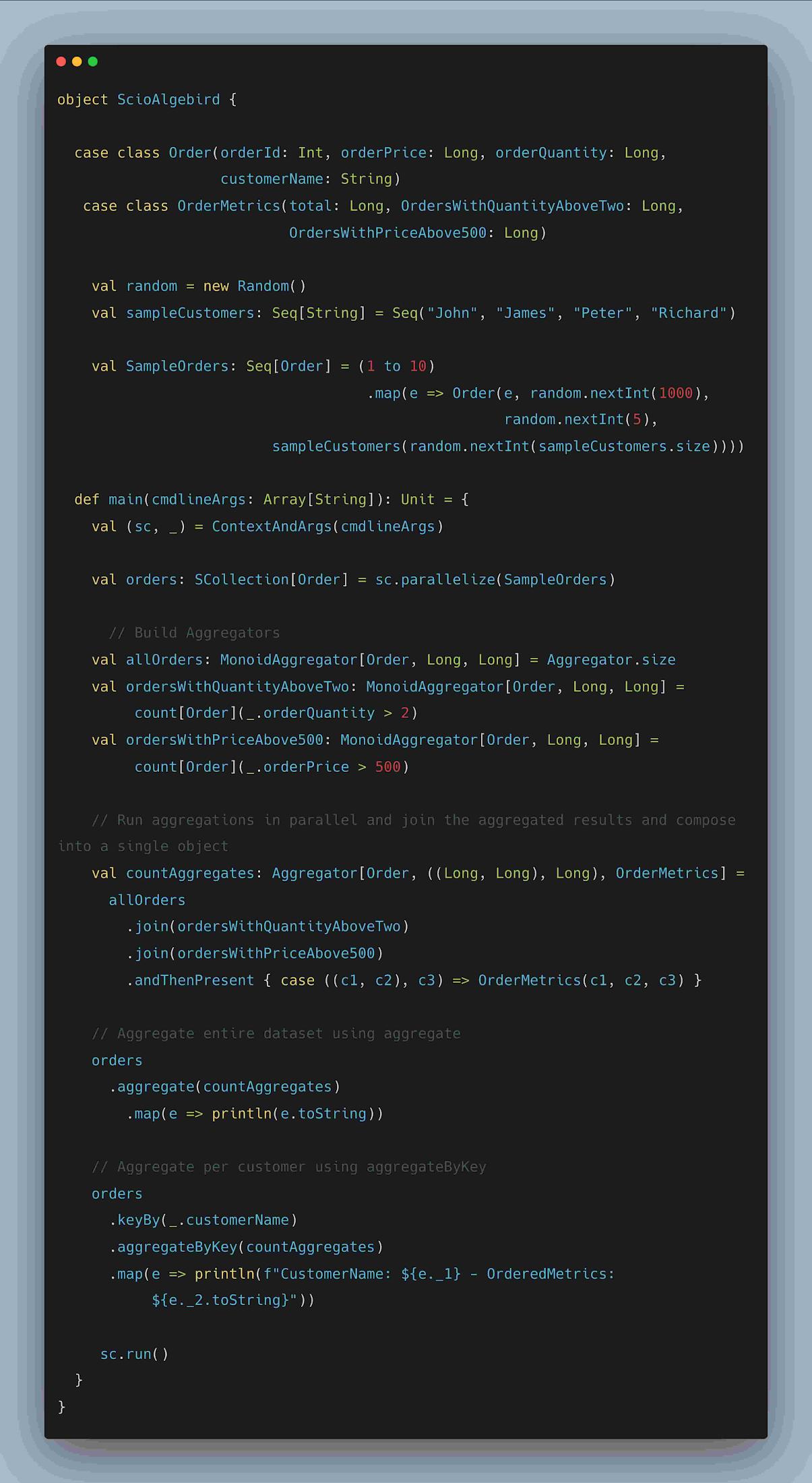
Fig: Example demonstrating Algebird Aggregators
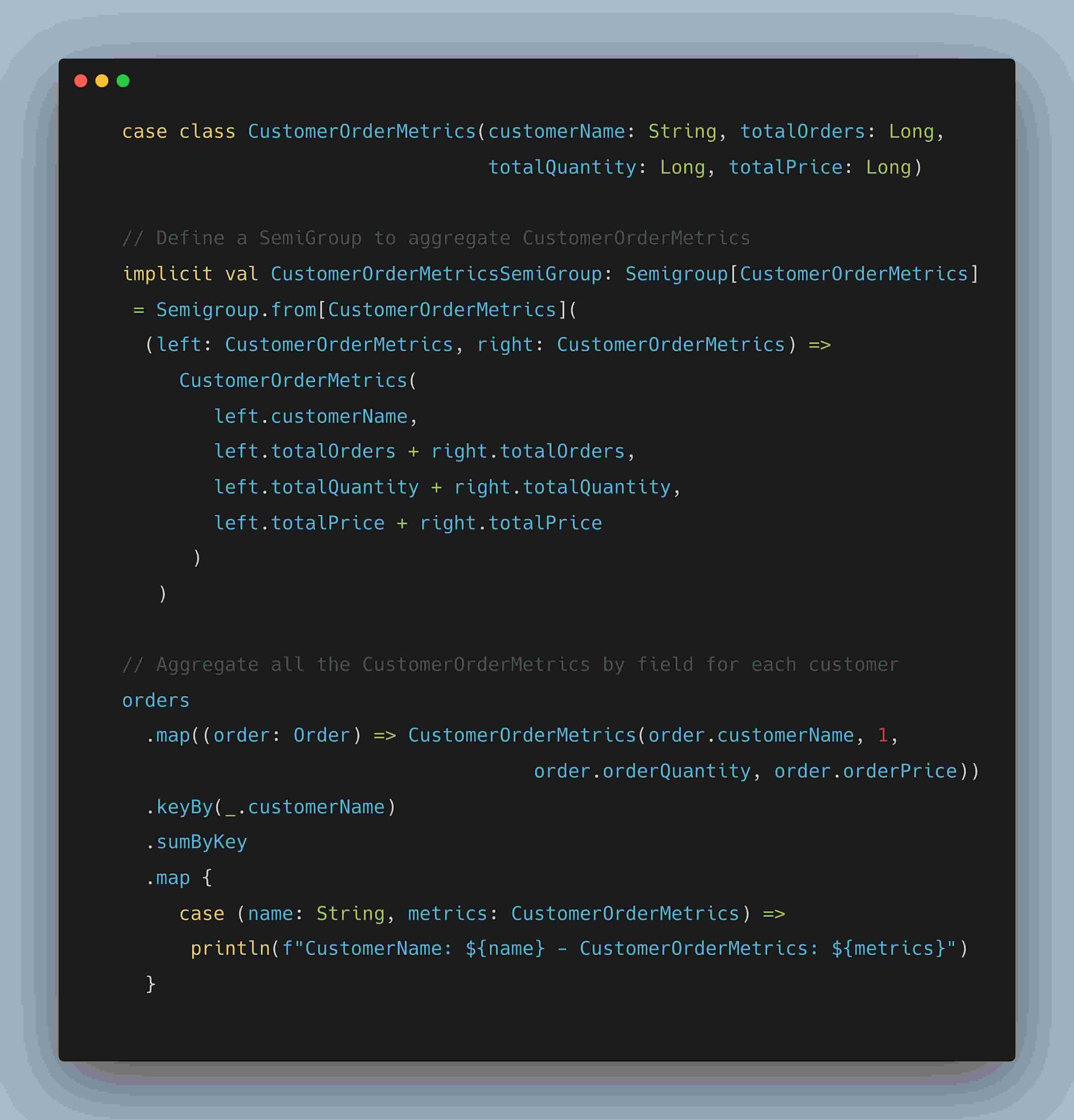
Fig: Example demonstrating Algebird SemiGroup
5. GroupMap and GroupMapReduce
GroupMap can be used as a replacement of groupBy(key) + mapValues(_.map(func))or_.map(e => kv.of(keyfunc, valuefunc))+groupBy(key)
Let us consider the below example that calculates the length of words for each type. Insteadof grouping by each type and applying length function, the GroupMap allows combiningthese operations by applying keyfunc and valuefunc.

Fig: Example demonstrating GroupMap
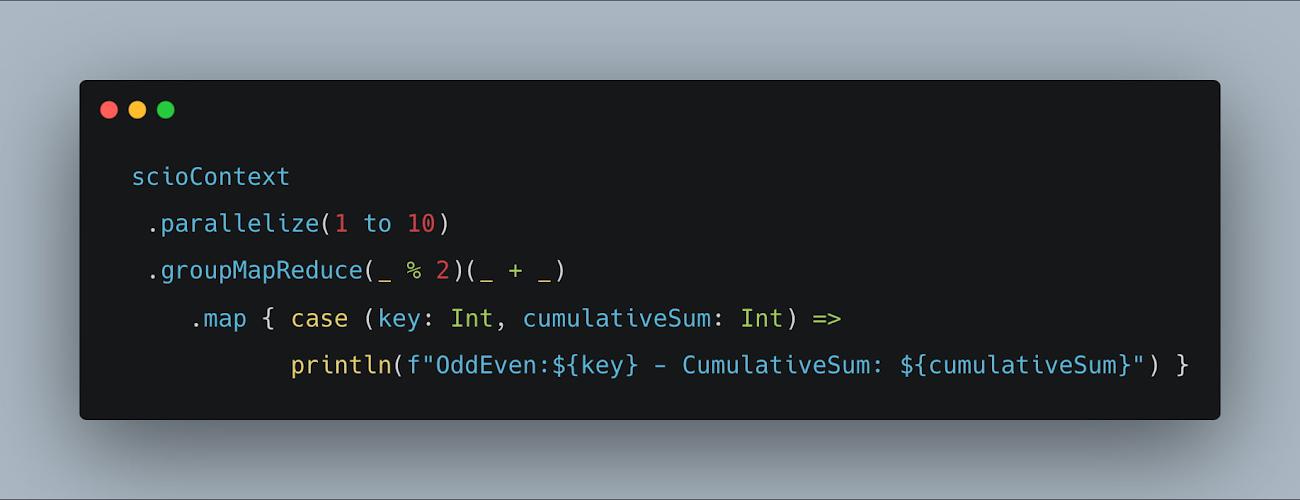
Fig: Example demonstrating GroupMapReduce
Conclusion
Thanks for reading and I hope now you are motivated to learn more about SCIO. Beyond thepatterns covered above, SCIO contains several interesting features like implicit coders forScala case classes, Chaining jobs using I/O Taps , Distinct Count using HyperLogLog++ ,Writing sorted output to files etc. Several use case specific libraries like BigDiffy (comparisonof large datasets) , FeaTran (used for ML Feature Engineering) were also built on top of SCIO.
For Beam lovers with Scala background, SCIO is the perfect recipe for building complexdistributed data pipelines.
By: Prathap Kumar Parvathareddy (Staff Data Engineer)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!