When designing cloud systems, a major consideration is reliability. As infrastructure architects, what do we want to guarantee to our customers, whether they’re internal or end users? How much time can we possibly allow our services to be down? How do we design services for resiliency?
From our partners:
Service availability, SLAs, and SLOs
Generally, service availability is calculated as # of successful units / # of total units. Such as, uptime / (uptime + downtime), or successful requests / (successful requests + failed requests). Availability acts as a reporting tool and a probability tool for discussing the likelihood that your system will perform as expected in the future. It’s then reported as a percentage, like 99.99%. For example, “my web page serves content to visitors 99.99% of the time.”
Within Google Cloud, services and products have their own service-level agreements (SLAs) that describe their target availability. For example, if properly configured, a single Compute Engine instance in one zone will offer a Monthly Uptime Percentage of >= 99.5% .
Note, an SLA is different from an SLO (Service-Level Objective). An SLO defines a numerical target for a service’s availability, whereas an SLA defines a promise to the service’s users that an SLO is met over a given time period. For simplicity, we’ll use the term “SLA” for the remainder of the document.
However, it’s rare that customer systems on Google Cloud are made up of a single Compute Engine instance. In reality, applications are much more complicated, with services intertwined and dependent on each other. Can you guarantee your users an SLA of >=99.5% for an application running on a single Compute Engine instance if that instance is also dependent on a Cloud Storage bucket that is only 99.0% available?
What we need to calculate is the combined availability across all the different services that make up an application — the composite availability of an application. We need to analyze how the relationship between services in an application impacts the resulting availability of the application overall. This approach allows us to better design more resilient systems and therefore offer users a better experience.
Depending on the relationship between the services, the composite availability might be higher or lower than an individual service alone. Let’s take a look at some application design examples. While this calculation only speaks to the architectural-level availability (i.e., procedural and operational risks that are specific to customer’s systems are excluded), it provides meaningful “upper-bounds” of availability to help guide design.
Dependent services
Dependent services are defined as services where one service’s availability is dependent on the other. There are a few common variants of dependent service architecture. The first one to consider is “Serial Services.”
Serial services
Consider an application where successive services are dependent on each other directly:
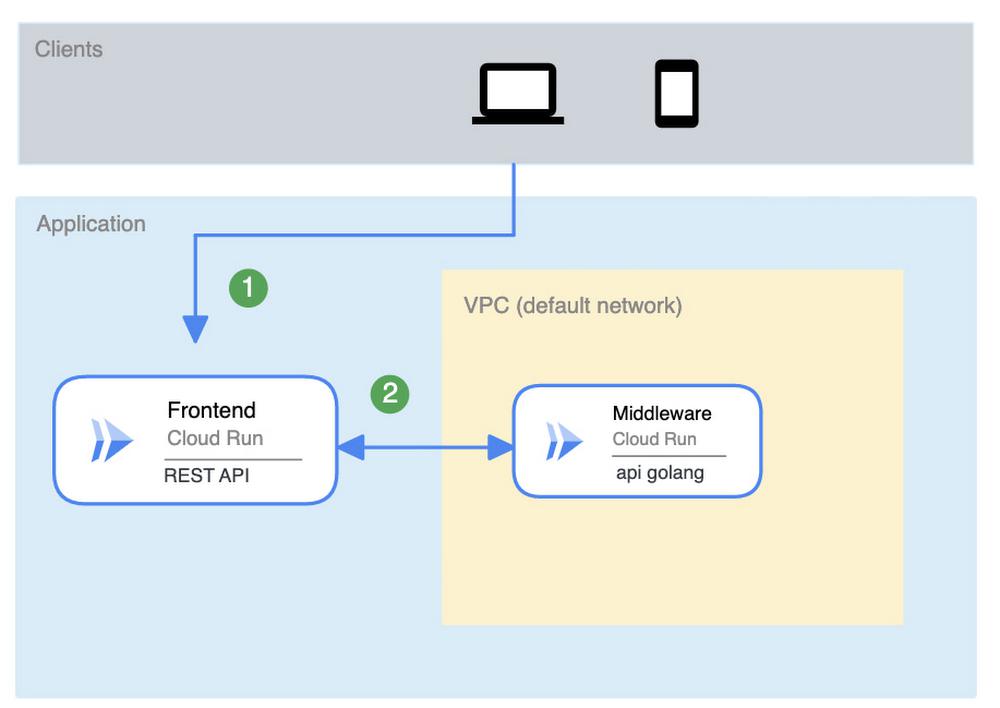
Frontend_SLA * Middleware_SLA = SLA of system
.9995 * .9995 = 0.999
(SLA_1) * (SLA_2) … * (SLA_N) = SLA of system
Parallel services
Another common dependent service architecture is to place your services in parallel, where your app is the composite of all of them. For example, middleware is now dependent on a backend running on Cloud SQL and a cache running on Memorystore. Let’s assume you need both the cache and the backend up and running for the middleware to function.
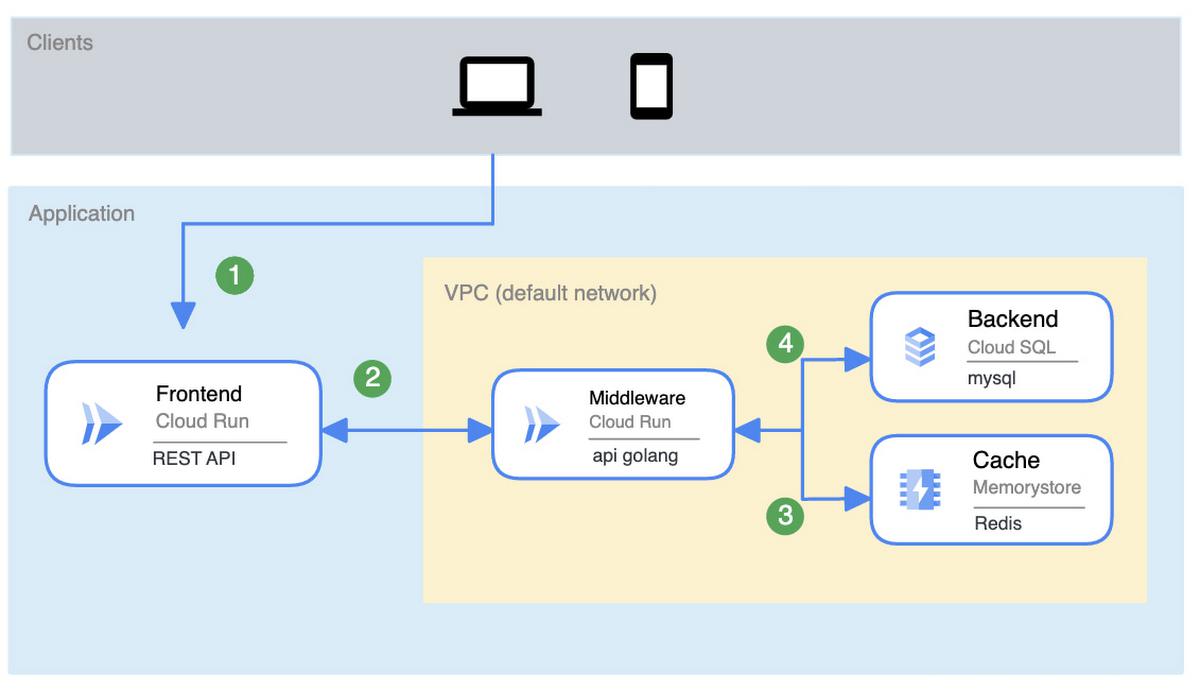
Frontend_SLA * Middleware_SLA * Backend_SLA * Cache_SLA = SLA of system
.9995 * .9995 * .9995 * .999 = .997
Independent services
So… how can we improve the SLA of a system? We need a way to introduce services that can increase the resiliency of an application as a whole. A good example of this is redundancy!
Redundant services
Having independent copies of the service means that as long as one copy is running, your application is running. So what if we duplicated the application — perhaps across multiple regions — and load balanced between them?
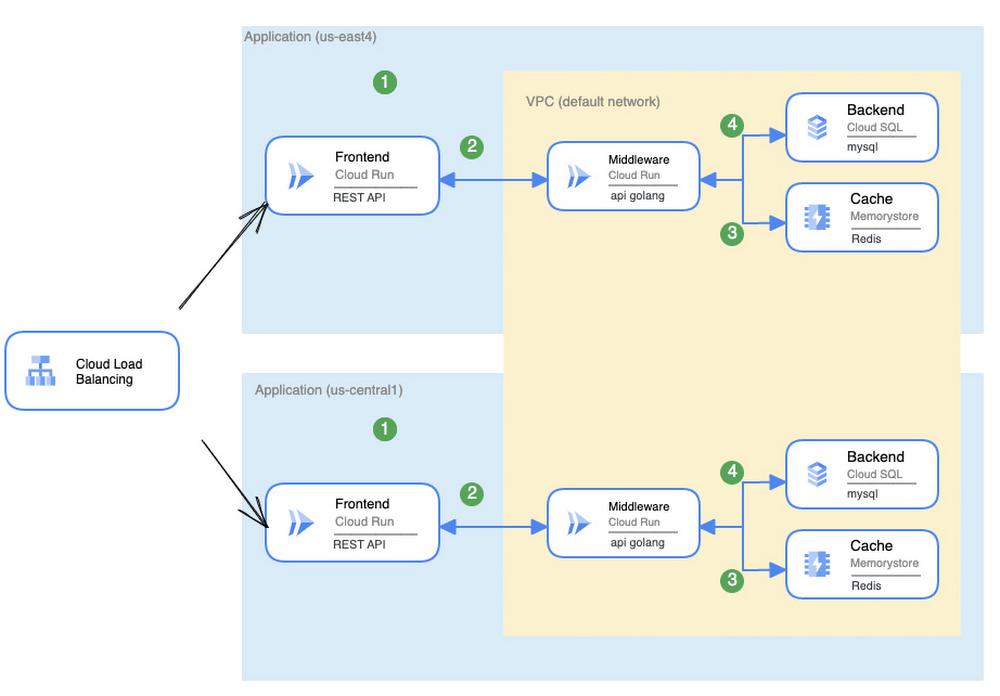
1 - ( (probability_failure_replica1) * (probability_failure_replica2) … (probability_failure_N)) = SLA of the system excluding Cloud LB1 - ( (1-(Frontend_SLA * Middleware_SLA * Backend_SLA * Cache_SLA) * (1-(Frontend_SLA * Middleware_SLA * Backend_SLA * Cache_SLA)) = SLA of the system excluding Cloud LB
1 - ( (1-.997) * (1-.997)) = SLA of the system excluding Cloud LB
1 - ((.003) * (.003)) = = SLA of the system excluding Cloud LB
= 0.999991
Load Balancers
With all this in mind, it begs the question: why can’t we get infinite 9s in our applications then? Theoretically, we could duplicate our application to our heart’s content. Here’s where the Cloud Load Balancer comes into play. The two replicas can’t simply failover to each other by themselves – they need to be routed to by the Cloud Load Balancer and the Cloud Load Balancer has its own availability. Therefore, the system will be down if either the Cloud Load Balancer fails or if both replicas fail:
Cloud_LB_SA * (1 - ( (probability_failure_1) * (probability_failure_2) … (probability_failure_N))) = SLA of the systemCloud_LB_SA * ( (1-(Frontend_SLA * Middleware_SLA * Backend_SLA * Cache_SLA) * (1-(Frontend_SLA * Middleware_SLA * Backend_SLA * Cache_SLA)) = SLA of the system
.9999 * ( (1-.997) * (1-.997)) = SLA of the system
.9999 * (1 - ((.003) * (.003))) = SLA of the system
.9999 * . 0.999991 = SLA of the system
.999891 = SLA of the system
Real-life considerations
It seems like the problem of calculating composite availability has been solved. In reality, things are a bit more complicated. As mentioned, these calculations are just the “upper-bounds” of availability. There are considerations of capacity and resource budgets, time and effort associated with configuration— and in the end, oftentimes, the bottleneck of reliability isn’t even the infrastructure at all. It’s the network, application logic, and most notably, the real life implications of people managing complex systems.
Reliability is the responsibility of everyone in engineering: development, product management, Ops, Dev, SRE, and more. Team members are accountable for knowing their project’s reliability target, risk and error budgets, and prioritizing and escalating work appropriately.
Ultimately, designing for composite availability is important but is only a piece of the puzzle. It’s important to contextualize your infrastructure with your own customer defined SLOs, your error budgets, and what operational complexity your teams can take on. Finding a balance is the key for your application’s success and your users’ happiness.
Further reading:
By: Cat Chu (Strategic Cloud Engineer, App Modernization) and Gang Chen (Strategic Cloud Engineer, Infrastructure Modernization)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!