
Artificial intelligence (AI) and machine learning (ML) have become an increasingly important enterprise capability, including use cases such as product recommendations, autonomous vehicles, application personalization, and automated conversational platforms. Building and deploying ML models demand high-performance infrastructure. Using NVIDIA GPUs can greatly accelerate the training and inference system. Consequently, monitoring GPU performance metrics to understand workload behavior is critical for optimizing the ML development process.
From our partners:
- How to setup NVIDIA DCGM in your GKE cluster, and
- How to observe the GPU utilization using either a Cloud Monitoring Dashboard or Grafana with Prometheus.
NVIDIA Data Center GPU Manager
NVIDIA DCGM simplifies GPU administration, including setting configuration, performing health checks, and observing detailed GPU utilization metrics. Check out NVIDIA’s DCGM user guide to learn more.
Here we focus on the gathering and observing of GPU utilization metrics in a GKE cluster. To do so, we also make use of NVIDIA DCGM exporter. This component collects GPU metrics using NVIDIA DCGM and exports them as Prometheus style metrics.
GPU Monitoring Architecture
The following diagram describes the high-level architecture of the GPU monitoring setup using NVIDIA DCGM, NVIDIA DCGM Exporter, and Google Managed Prometheus,Google Cloud’s managed offering for Prometheus.
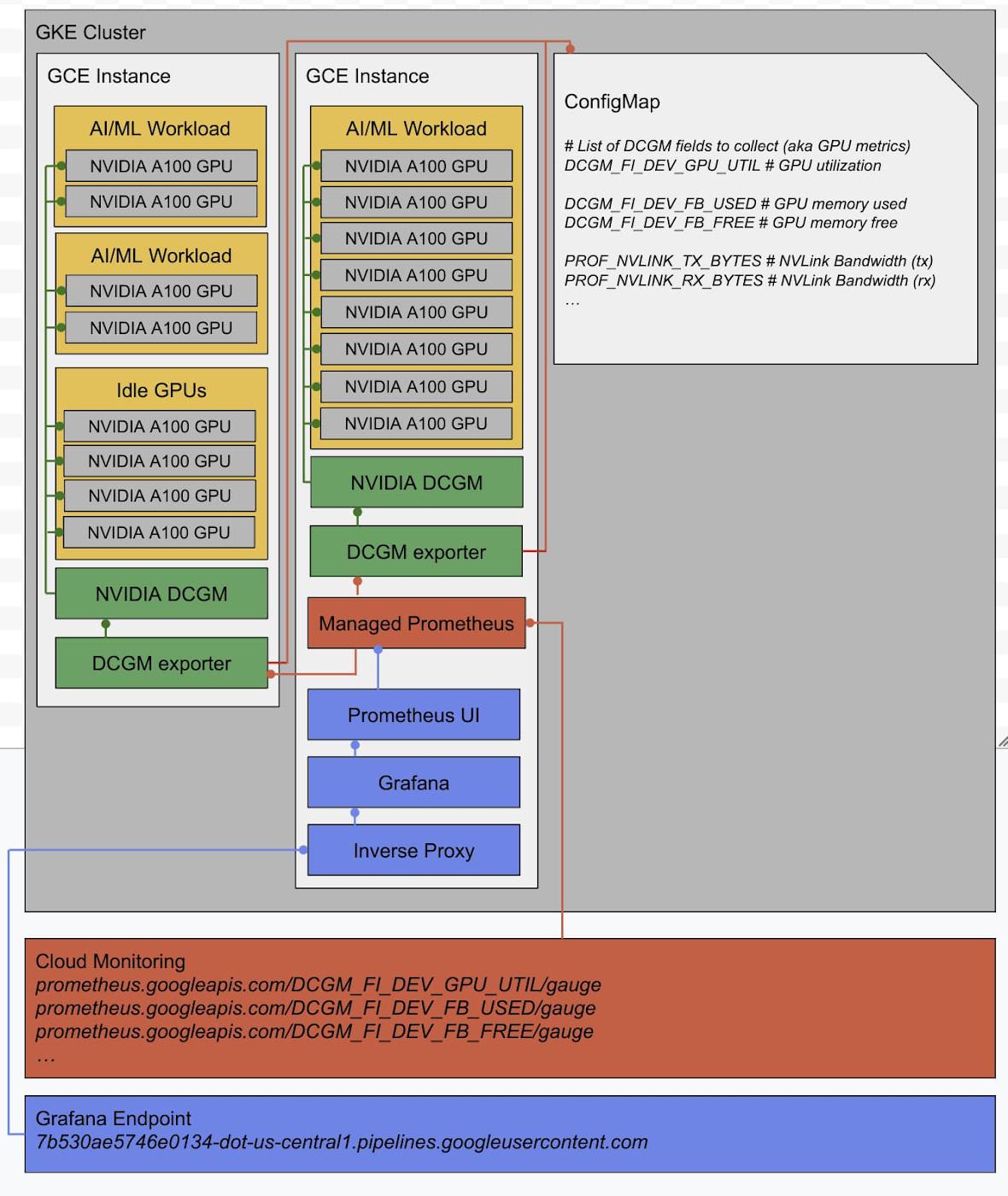
All the GPU monitoring components are deployed to a namespace “gpu-monitoring-system.”
Requirements
- Google Cloud Project
- Quota for NVIDIA GPUs (more information at GPU quota)
- GKE version 1.21.4-gke.300 with “beta” component to install Managed Prometheus.
- GKE version 1.18.6-gke.3504 or above to support all available cloud GPU types.
- NVIDIA Datacenter GPU Manager requires NVIDIA Driver R450+.
Deploy a Cluster with NVIDIA GPUs
1. Follow the instructions at Run GPUs in GKE Standard node pools to create a GKE cluster with NVIDIA GPUs.
Here is an example to deploy a cluster with two A2 VMs with 2 x NVIDIA A100 GPUs each. For a list of available GPU platforms by region, see GPU regions and zones.
gcloud beta container clusters create CLUSTER_NAME \
--zone us-central1-f \
--machine-type=a2-highgpu-2g \
--num-nodes=2 \
--enable-managed-prometheus
gcloud beta container clusters update CLUSTER_NAME \
--zone ZONE \
--enable-managed-prometheus
gcloud container clusters get-credentials CLUSTER_NAME \
--zone us-central1-f
kubectl apply -f \
https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
kubectl get pods -n kube-system | grep nvidia-gpu-device-plugin
Download GPU Monitoring System Manifests
Download the Kubernetes manifest files and dashboards used later in this guide.
git clone https://github.com/suffiank/dcgm-on-gke && cd dcgm-on-gke
Configure GPU Monitoring System
Before we deploy the NVIDIA Data Center GPU manager and related assets, we need to select which GPU metrics we want to emit from the cluster. We also want to set the period at which we sample those GPU metrics. Note that all these steps are optional. You can choose to keep the defaults that we provide.
1. View and edit the ConfigMap section of quickstart/dcgm_quickstart.yml to select which GPU metrics to emit:
apiVersion: v1
kind: ConfigMap
metadata:
name: nvidia-dcgm-exporter-metrics
…
data:
counters.csv: |
# Utilization (the sample period varies depending on the product),,
DCGM_FI_DEV_GPU_UTIL, gauge, GPU utilization (in %).
DCGM_FI_DEV_MEM_COPY_UTIL, gauge, Memory utilization (in %).
# Utilization of IP blocks,,
DCGM_FI_PROF_SM_ACTIVE, gauge,
DCGM_FI_PROF_SM_OCCUPANCY, gauge,
DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge,
DCGM_FI_PROF_PIPE_FP64_ACTIVE, gauge,
DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge,
DCGM_FI_PROF_PIPE_FP16_ACTIVE, gauge,
# Memory usage,,
DCGM_FI_DEV_FB_FREE, gauge,
DCGM_FI_DEV_FB_USED, gauge,
DCGM_FI_DEV_FB_TOTAL, gauge,
# PCIE,,
DCGM_FI_PROF_PCIE_TX_BYTES, gauge,
DCGM_FI_PROF_PCIE_RX_BYTES, gauge,
# NVLink,,
DCGM_FI_PROF_NVLINK_TX_BYTES, gauge,
DCGM_FI_PROF_NVLINK_RX_BYTES, gauge,
The FP64, FP32, and FP16 activity (e.g. “DCGM_FI_PROF_PIPE_FP64_ACTIVE”) indicates to what extent your workload is exercising the GPU engines targeting a specific precision. A scientific application might skew to FP64 calculations and an ML/AI workload might skew to FP16 calculations.
The GPU NVLink activity (e.g. “DCGM_FI_PROF_NVLINK_TX_BYTES”) indicates the bandwidth (in bytes/sec) of traffic transmitted directly from one GPU to another over high-bandwidth NVLink connections. This can indicate whether the workload requires communicating GPUs; and, if so, what fraction of the time the workload is spending on collective communication.
The GPU PCIe activity (e.g. “DCGM_FI_PROF_PCIE_TX_BYTES“) indicates the bandwidth (in bytes/sec) of traffic transmitted to or from the host system.
All the fields with “_PROF_” in the DCGM field identifier are “profiling metrics.” For a detailed technical description of their meaning take a look at NVIDIA DCGM Profiling Metrics. Note that these do have some limitations for NVIDIA hardware before H100. In particular they cannot be used concurrently with profiling tools like NVIDIA Nsight. You can read more about these limitations at DCGM Features, Profiling Sampling Rate.
2. (Optional:) By default we have configured the scrape interval at 20 sec. You can adjust the period at which NVIDIA DCGM exporter scrapes NVIDIA DCGM and likewise the interval at which GKE Managed Prometheus scrapes the NVIDIA DCGM exporter:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-dcgm-exporter
…
spec:
…
args:
- hostname $NODE_NAME; dcgm-exporter -k --remote-hostengine-info $(NODE_IP) --collectors /etc/dcgm-exporter/counters.csv --collect-interval 20000
…
apiVersion: monitoring.googleapis.com/v1alpha1
kind: PodMonitoring
metadata:
name: nvidia-dcgm-exporter-gmp-monitor
…
spec:
…
endpoints:
- port: metrics
interval: 20s
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-dcgm
…
spec:
…
containers:
- image: "nvcr.io/nvidia/cloud-native/dcgm:2.3.5-1-ubuntu20.04"
…
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-dcgm-exporter
…
spec:
…
containers:
- name: nvidia-dcgm-exporter
image: nvcr.io/nvidia/k8s/dcgm-exporter:2.3.5-2.6.5-ubuntu20.04
Deploying GPU Monitoring System
1. Deploy NVIDIA DCGM + NVIDIA DCGM exporter + Managed Prometheus configuration.
kubectl create namespace gpu-monitoring-system
kubectl apply -f quickstart/dcgm_quickstart.yml
Set up a Cloud Monitoring Dashboard
1. Import a custom dashboard to view DCGM metrics emitted to Managed Prometheus
gcloud monitoring dashboards create \
--config-from-file quickstart/gke-dcgm-dashboard.yml
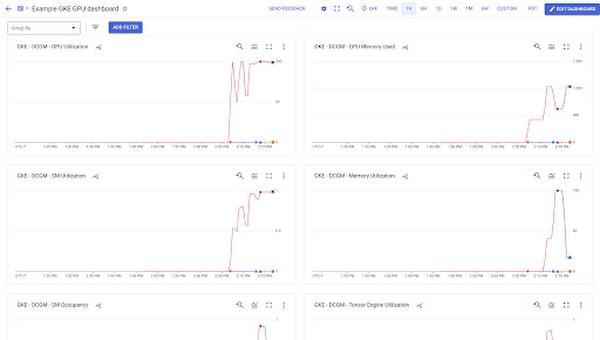
“cluster” (GKE cluster name)
“instance” (GKE node name)
“gpu” (GPU index on the GKE node)
“modelName” (whether NVIDIA T4, V100, A100 etc.)
“exported container” (container that has mapped this GPU)
“exported namespace” (namespace of the container that has mapped this GPU)Because Managed Prometheus monitors the GPU workload through NVIDIA DCGM exporter, it is important to keep in mind that that the container name and namespace are on the labels “exported container” and “exported namespace”
Stress Test your GPUs for Monitoring
We have provided an artificial load so you can observe your GPU metrics in action. Or feel free to deploy your own GPU workloads.
1. Apply an artificial load tester for the NVIDIA GPU metrics.
kubectl apply -f quickstart/dcgm_loadtest.yml
Set up a Grafana Dashboard
1. Deploy the Prometheus UI frontend, Grafana, and inverse proxy configuration.
cd grafana
sed 's/\$PROJECT_ID/<YOUR PROJECT ID>/' grafana.yml | kubectl apply -f -
kubectl get configmap inverse-proxy-config -o jsonpath="{.data}" -n gpu-monitoring-system{
…
"Hostname":
"7b530ae5746e0134-dot-us-central1.pipelines.googleusercontent.com",
…
}
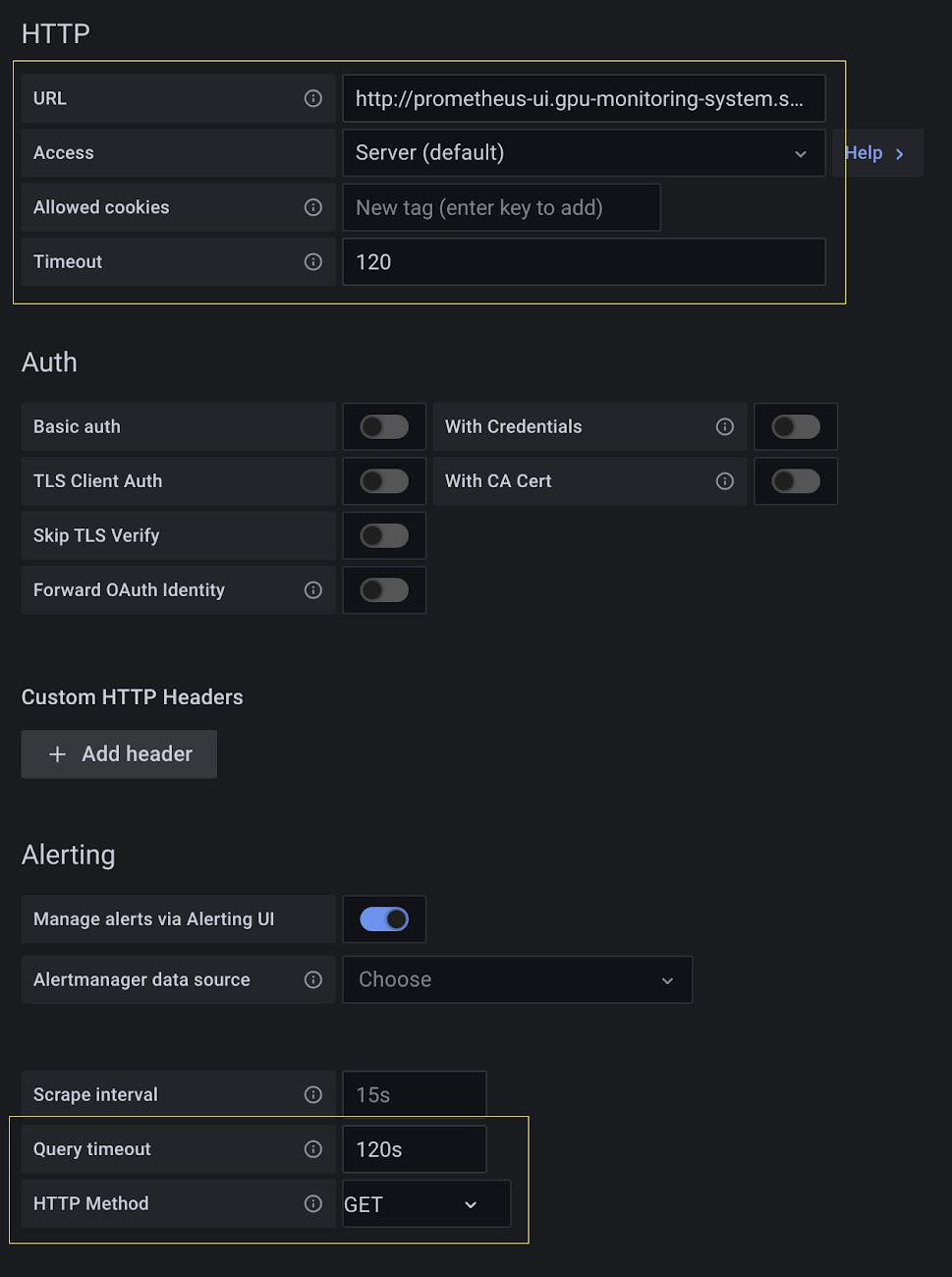
”http://prometheus-ui.gpu-monitoring-system.svc:9090”Select “Save and test” at bottom. You should see “Data source is working.”3. Import the Grafana dashboard by selecting the “Import” from the “+ Create” widget panel on the left-hand side of the Grafana page.
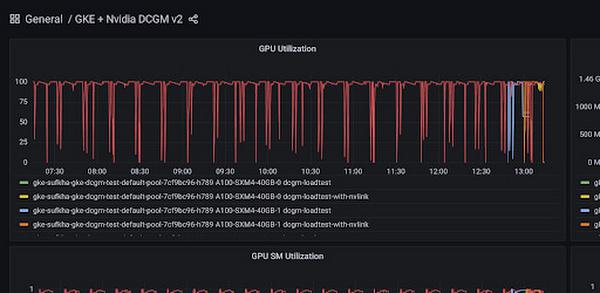
Then select the local JSON file “grafana/gke-dcgm-grafana-dashboard.json.”
You should see the GPU utilization and all other metrics for the fake workload you deployed earlier. Note that the dashboard is configured to only display metrics whose container label is not the empty string. Therefore it does not display metrics for idle GPUs with no attached containers.
Conclusion
In this blog you were able to deploy a GKE cluster with NVIDIA GPUs and emit GPU utilization metrics by workload to Cloud Monitoring. We also set up a Cloud Monitoring dashboard to view GPU utilization by workload.
This GPU monitoring system leveraged the NVIDIA Data Center GPU Manager. All of the available NVIDIA DCGM metrics are accessible for monitoring. We also discussed the available GPU metrics and their meaning in the context of application workloads.
Finally we provided a means to deploy an in-cluster Grafana GPU utilization dashboard accessible from a Google hosted endpoint for users with access to the corresponding Google Cloud project.
By: Suffian Khan (Senior Software Engineer, AI+Accelerators Experience) and Tao He (Senior Software Engineer, Google Kubernetes Engine)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!

