It’s common to have a separate database for each service in microservices-based architectures. This pattern ensures that the independently designed and deployed microservices remain independent in the data layer as well. But it also introduces a new problem: How do you implement transactions (single units of work, usually made up of multiple operations) that span multiple microservices each with their own local database?
In a traditional monolith architecture, you can rely on ACID transactions (atomicity, consistency, isolation, durability) against a single database. In a microservices architecture, ensuring data consistency across multiple service-specific databases becomes more challenging. You cannot simply rely on local transactions. You need a cross-service transaction strategy. That’s where the saga pattern comes into play.
From our partners:
What is the saga pattern?
A saga is a sequence of local transactions. Each local transaction updates the database and triggers the next local transaction. If a local transaction fails, the saga executes a series of compensating transactions that undo the changes that were made by the preceding local transactions. Check out the blog series by Chris Richardson for a much more in-depth explanation of the saga pattern both in choreography and orchestration scenarios.
Let’s take Chris’ example and apply the saga pattern in the context of Workflows. Imagine, you’re building an ecommerce application. You need to receive orders and make sure customers have enough credit before processing or rejecting the order.
Naive implementation
In a naive implementation, you might have you have two services, OrderService to receive orders and CustomerService to manage customer credit:
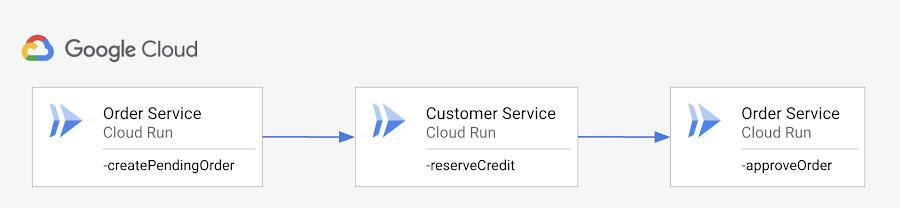
You can then chain these operations easily with a workflow (ordering-v1.yaml):
- create_pending_order:call: http.postargs:url: ${url_order_service}body:customerId: "customer123"description: "My order"result: pending_order- reserve_credit:call: http.postargs:url: ${url_customer_service}body:customerId: ${pending_order.body.customerId}amount: 10.50result: the_credit- approve_pending_order:call: http.putargs:url: ${url_order_service+"/approve/"+pending_order.body.id}result: approved_order
This works if none of the services ever fail, but we know this is not always true. Notice the lack of error handling or retries around any steps. Any failure in any step will also cause the entire workflow to fail—far from ideal.
Apply retries
If CustomerService becomes unavailable once in a while (e.g. due to HTTP 503), one easy solution is to retry the call to CustomerService one or more times:
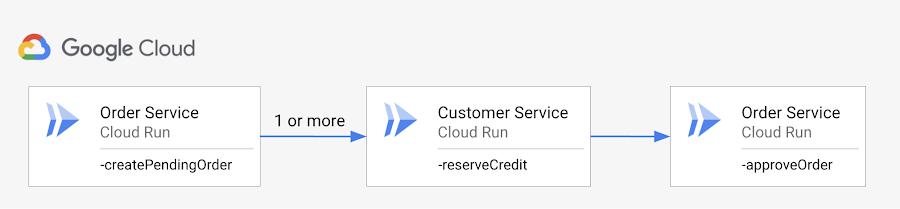
You could implement this retry logic in each service. However, Workflows makes this easier by providing try/retry primitives and giving you the ability to apply a consistent retry policy without having to change the services.
In the reserve_credit step, you can wrap the HTTP call with a retry policy (ordering-v2.yaml):
- reserve_credit:try:call: http.postargs:url: ${url_customer_service}body:customerId: ${pending_order.body.customerId}amount: 10.50result: the_credit# Retries with max_retries of 5 on HTTP 503 (Service unavailable) (along# with HTTP 429, 502, 503, 504) to recover from transient error.retry: ${http.default_retry}
The default Workflows HTTP retry policy retries certain HTTP failures for a maximum of five times. This is enough to recover from most transient failures but retry policy is also fully configurable.
This works for transient failures, but what if the failure is due to an unrecoverable error like the customer not actually having credit or the service being down permanently?
Apply the saga pattern
When the failure in CustomerService is unrecoverable, you need to apply a rollback step and reject the order:
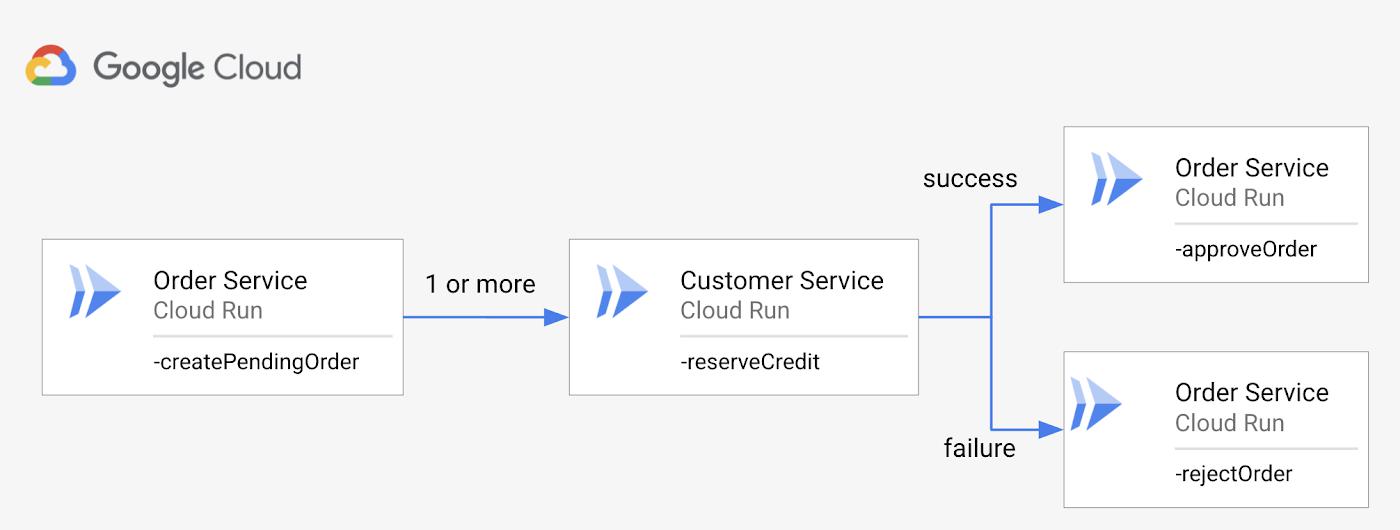
This is the saga pattern, in which a failed call down the chain triggers a compensation call up the chain.
In the reserve_credit step, we now check for unrecoverable errors and route them to the reject_pending_order step (ordering-v3.yaml):
- reserve_credit:try:call: http.postargs:url: ${url_customer_service}body:customerId: ${pending_order.body.customerId}amount: 10.50result: the_credit# Retries with max_retries of 5 on HTTP 503 (Service unavailable) (along# with HTTP 429, 502, 503, 504) to recover from transient error.retry: ${http.default_retry}except:as: esteps:- check_nonrecoverable_error:switch:# HTTP 500 (Internal Server Error) indicates the credit# cannot be reserved. Apply the compensation step to reject# the order.- condition: ${e.code == 500}next: reject_pending_order- raiseError:raise: ${e}
The reject_pending_order step makes the compensation call to the OrderService:
- reject_pending_order:call: http.putargs:url: ${url_order_service+"/reject/"+pending_order.body.id}result: order
With these changes, transient failures are handled by the retry policy and unrecoverable errors are handled by the compensation step. The workflow is much more resilient now!
Chaining compensation steps
You’ve seen how to apply retries and the saga pattern in a simple workflow involving two services. In multiservice and multistep workflows, it gets more complicated. You might need to apply multiple compensation steps after a failed step. In such cases, it’s a good idea to define the rollback steps in subworkflows, so they can be reused in except clauses as needed.
For example, if step 4 fails, you can rollback steps 1, 2, and 3 by calling the subworkflows:
step4:call: ...except:as: esteps:- undo3:call: undoStep3- undo2:call: undoStep2- undo1:call: undoStep1
When chaining microservices, it’s important to design for failures. Thankfully, Workflows provides primitives to enable flexible retry policies and more sophisticated error handling such as the saga pattern. Check out our retries and the saga pattern in Workflows tutorial on GitHub for more details. As always, feel free to reach out to me on Twitter @meteatamel for any questions or feedback.
By: Mete Atamel (Developer Advocate)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!