SQL is great, but sometimes you may need something else.
By and large, the prevalent type of data that data engineers deal with on a regular basis is relational. Tables in a data warehouse, transactional data in Online Transactional Processing (OLTP) databases — they can all be queried and accessed using SQL. But does it mean that NoSQL is irrelevant for data engineering? In this article, we’ll investigate use cases for which data engineers may need to interact with NoSQL data stores.
From our partners:
The reasons behind NoSQL
These days, data is stored at such a velocity, volume, and variety (in short: Big Data) that many relational database systems can’t keep up. Historically, this was the main reason why large tech companies developed their own NoSQL solutions to mitigate those issues. In 2006, Google published their Bigtable paper which laid the foundations for the open-source HBase NoSQL data store and GCP’s Cloud Bigtable. In 2007, Amazon offered their alternative solution with Dynamo paper.
From that time on, other NoSQL distributed database systems kept emerging. All of them have been mainly trying to mitigate the issue of scale (data volume) that is hard to achieve with the traditional vertically-scalable RDBMS. Instead of scaling vertically (buying more RAM and CPU for your single server), they operate on horizontally-scalable distributed clusters allowing them to increase the capacity by simply adding more nodes to the cluster.
Apart from scalability and addressing the sheer data volume, many distributed NoSQL database systems address the challenge of data coming in many different formats (highly nested JSON-like structure, XML, time-series, images, videos, audio…), i.e., variety, which is difficult to achieve in relational databases. I’ve seen many creative solutions in my career when people tried to serialize and blob non-relational data to a relational database. Still, such self-built systems tend to be hard to operate and manage at scale. Document databases with schema-on-read such as MongoDB allow much more flexibility in that regard.
Finally, with the velocity of data, continuously streaming in real-time, many NoSQL databases help address that issue. For instance, Amazon Timestream handles data streaming from a variety of IoT devices in a very intuitive and easy way.
Why do I need to know NoSQL data stores as a data engineer?
One of a data engineer responsibilities is integrating and consolidating data from various sources and providing it to data consumers consistently and reliably so that this data can be used for analytics and building data products. This means building data pipelines that pull data from (among others) NoSQL databases and store it in a data lake or data warehouse. Due to the above-mentioned data variety, data lakes are particularly useful for storing data from NoSQL data stores.
NoSQL use cases for data engineering
Now that we know why NoSQL is important for data engineering let’s look at the typical use cases that we may encounter.
1. Analysis of log streams
These days, many applications are sending logs to Elasticsearch and can be analyzed and visualized using Kibana. Thanks to the dynamic schema and indexing, Elaticsearch is a handy NoSQL data store in your data engineering toolbox, especially for container monitoring and log analytics.
2. Extracting time-series data from IoT devices and real-time applications
Relational database systems are usually not intended to be used with thousands of open connections used simultaneously. Imagine that you manage a large fleet of servers or IoT devices that keep streaming metrics such as CPU utilization to some centralized data store so that this information can be used for a real-time dashboard (showing the health of the system) and for anomaly detection analysis. If you would use a relational database for that, you would likely encounter connection issues (leading to some data loss) since RDBMS is not designed for thousands of short-lived connections. In contrast, NoSQL distributed data stores such as AWS Timestream can handle that easily.
3. Extracting data from NoSQL backend systems
NoSQL databases are used as a backend data store for so many applications, ranging from e-commerce, content management platforms (blogs), mobile apps, websites, web analytics, clickstream, shopping carts, and many more. All of this data can be used for analytics once you established data pipelines that extract or stream this data into your data lake or data warehouse.
4. Caching data for fast retrieval
If you’ve ever built a dashboard with some BI tools such as Tableau, you probably preferred working with extracts rather than with live data, provided that the dataset was fairly large. Making connections to relational databases and waiting till they process and retrieve the data is often too slow to build really performant dashboards (that don’t hang when you apply a filter). For this purpose, in-memory NoSQL data stores such as Redis are great. If you use those to cache recent data that you need for your dashboards, you can make sure that you experience no lag and provide a good user experience.
Demo: extracting data from NoSQL
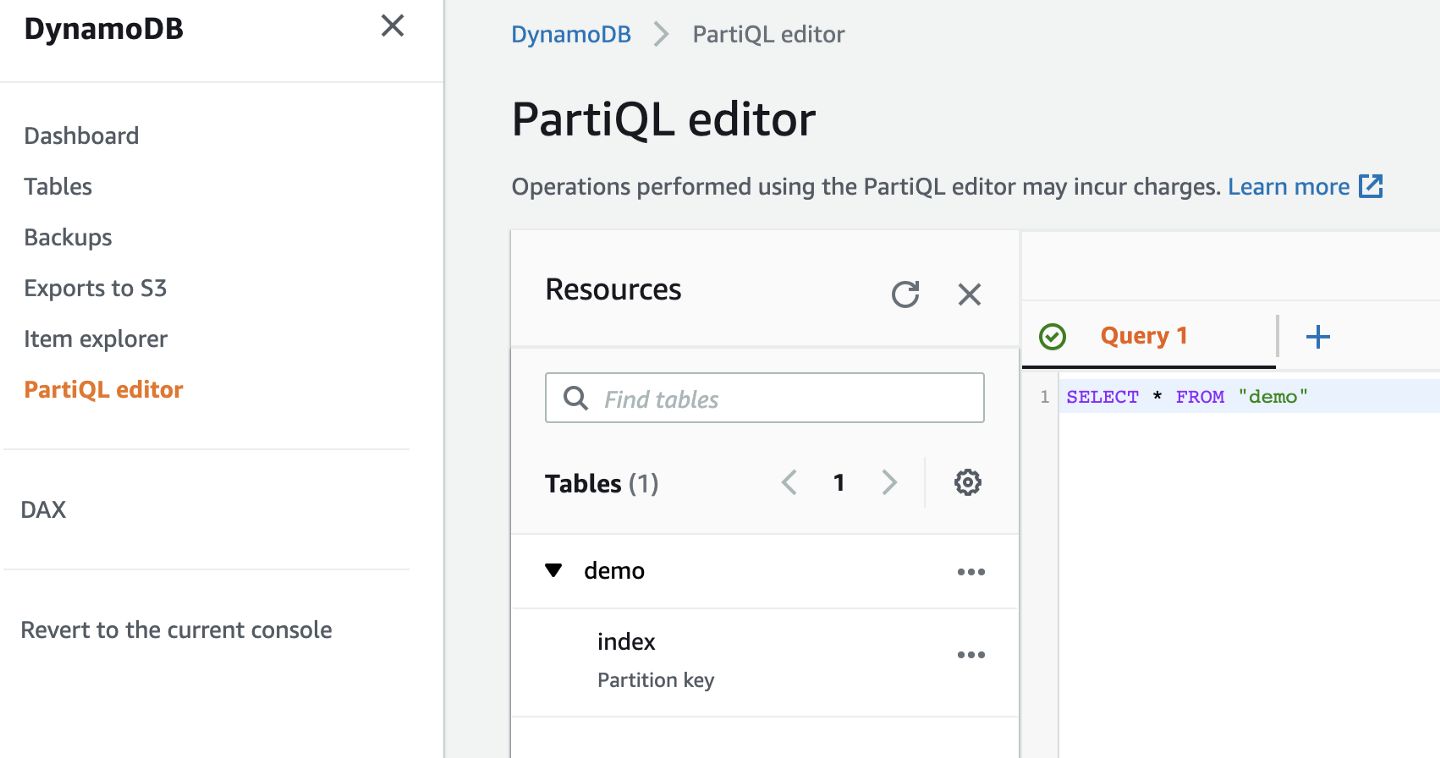
Let’s demonstrate how we can extract data from DynamoDB, one of the most popular (serverless) NoSQL data stores on AWS. I created a table called demo with partition key index. This index will be equivalent to my Pandas dataframe’s index.

Now we can use a combination of boto3 and awswrangler to load a sample dataset. Then, starting from line 34, we build a simple ETL to retrieve data that has been inserted since yesterday.

Additionally, we could use the PartiQL query editor in the management console to validate that our ETL returns correct data.
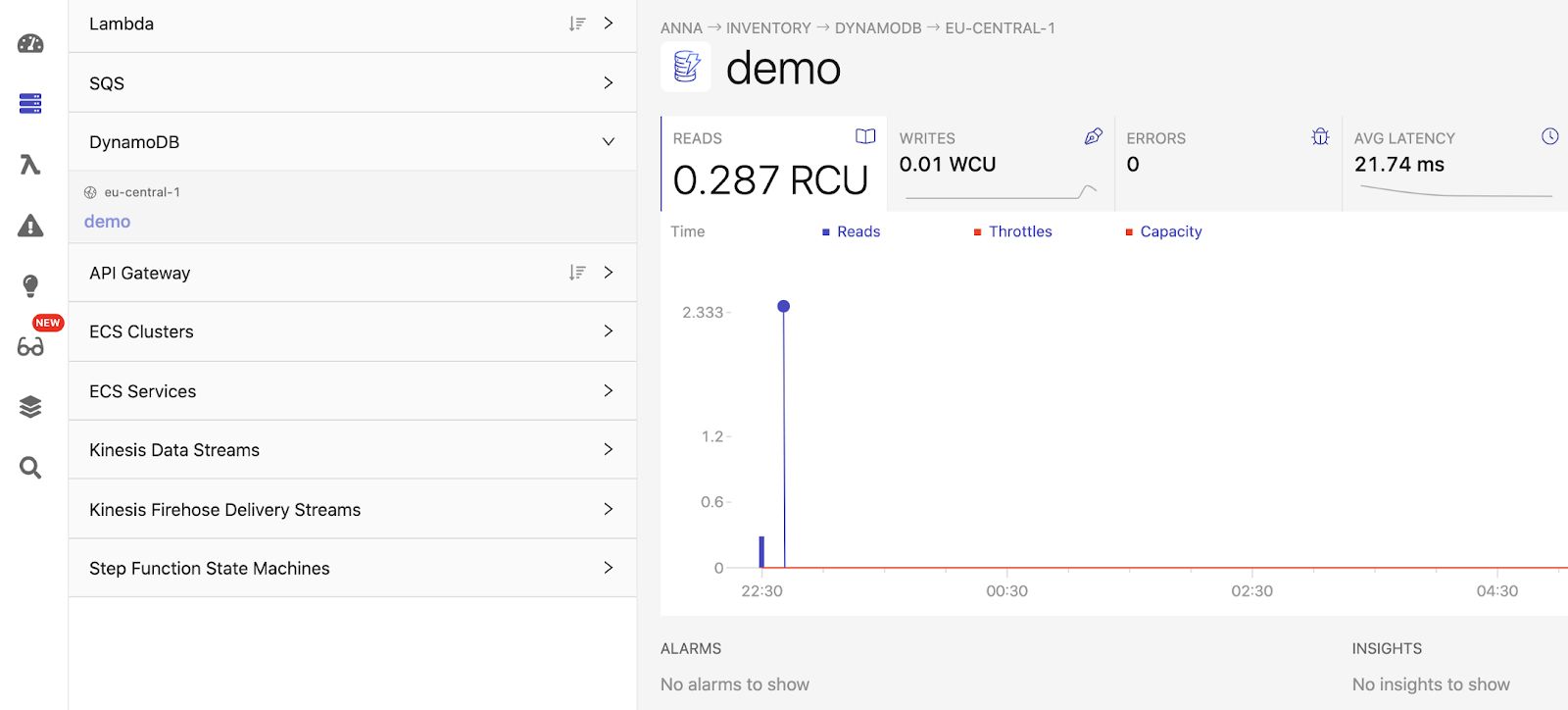
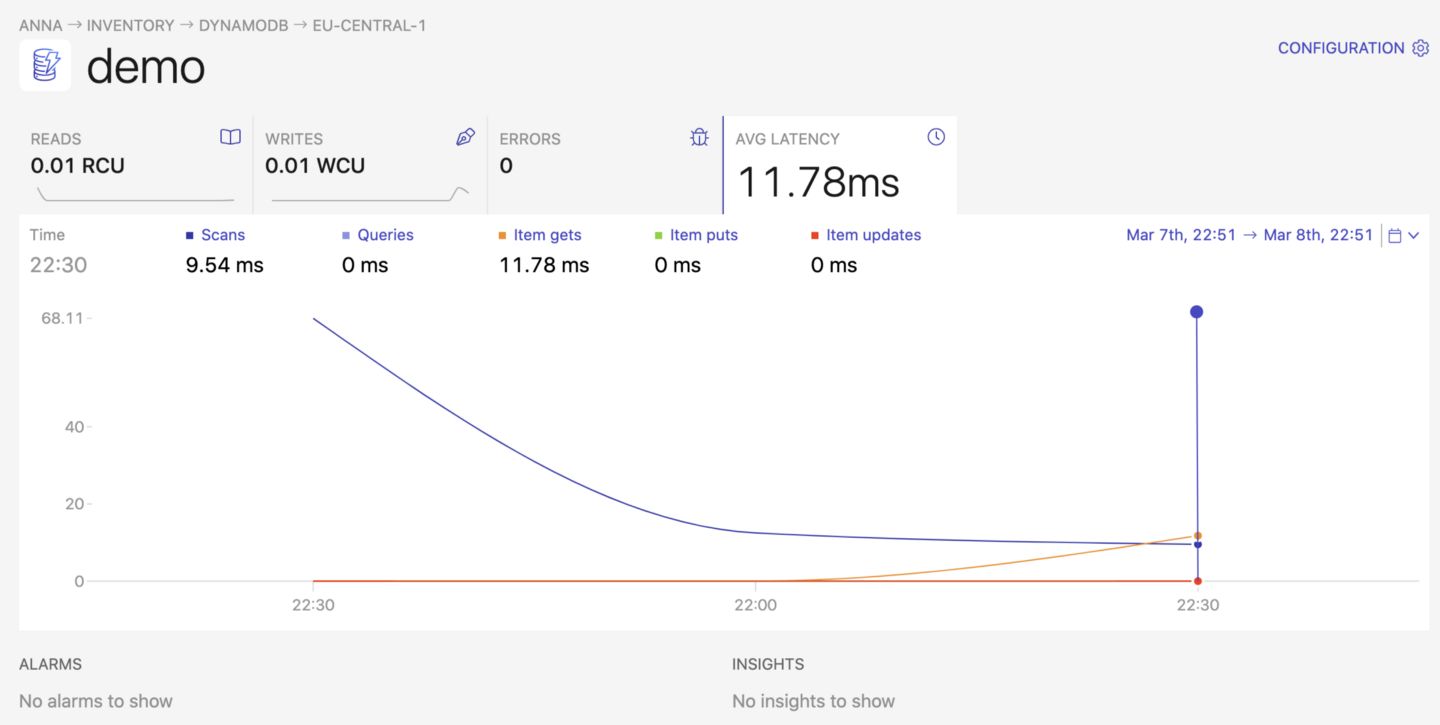
How to keep an eye on your DynamoDB resources?
To monitor the read and write capacity units used by our table, it’s helpful to make use of an observability platform that provides you more details about your infrastructure and your applications’ health. For example, with Dashbird you can track any errors that occurred when reading or writing your data, the average latency of your read and write operations, whether a continuous backup is enabled for a quick point-in-time recovery,, and how many read (RCU) and write capacity units (WCU) are consumed by your resources.
Drawbacks of NoSQL databases
The previous sections demonstrated the use cases where NoSQL data stores shine in data engineering. But now to the drawbacks.
The major drawback of NoSQL data stores is that without a full-fledged SQL interface, the developers need to learn (again) some proprietary vocabulary, API, or interface to access data. Timescale DB put it nicely on their blog:
“SQL is back. Not just because writing glue code to kludge together NoSQL tools is annoying. Not just because retraining workforces to learn a myriad of new languages is hard. Not just because standards can be a good thing. But also because the world is filled with data. […] Either we can live in a world of brittle systems and a million interfaces. Or we can continue to embrace SQL.” — Source
Even though many NoSQL data stores offer SQL interfaces on top, they will never be as powerful as a full-fledged relational database where you can create complex queries (not that complex queries are always a good thing).
So purely from a data engineering perspective, it’s best to work with those NoSQL systems rather than against them. Use them when there is a use case that clearly justifies the need for NoSQL’s scale and flexibility coming from schema-on-read.
If data comes in a format that is not suitable to be stored in a data warehouse, we can always extract it, store it in a data lake (ELT-approach), and provide it for analytics in its native raw format. These days, many tools allow us to make sense of data stored in a data lake. When leveraging serverless SQL query engines such as Presto (or AWS version: Amazon Athena) or BigQuery, you can analyze even semi-structured nested data.
Conclusion
To answer the question from the title: yes, NoSQL data stores are important for data engineering. Even though they often lack a friendly SQL-like interface to retrieve the information you need, there are still very beneficial in various use cases. Given that more and more vendors realize the need for a SQL interface for data retrieval (such as PartiQL from AWS, the “good old” Hive, Spark SQL, CQL in Cassandra, SQL queries in Timestream), we should expect that the trend will continue. It’s possible that one day, we may be able to write SQL queries to retrieve data the same way regardless of the backend data store under the hood. In fact, if we look at federated queries with Presto, this future may not be that far away.
This article is republished from hackernoon.com
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!