Guest post by Yan Xun, Senior Engineer from Alibaba Cloud EDAS team, Andy Shi, Developer Advocator from Alibaba Cloud, Tom Kerkhove, Containerization Practitioner Lead & Azure Architect at Codit, KEDA maintainer, CNCF Ambassador
When scaling Kubernetes there are a few areas that come to mind, but if you are new to Kubernetes this can be a bit overwhelming.
From our partners:
In this blog post; we will briefly explain the areas that need to be considered, how KEDA aims to make application auto-scaling simple, and why Alibaba Cloud’s Enterprise Distributed Application Service (EDAS) has fully standardized on KEDA.
An introduction to scaling Kubernetes
When managing Kubernetes clusters & applications, you need to carefully monitor a variety of things such as :
- Cluster capacity – Do we have enough resources available to run our workloads?
- App Workload – Does the application have enough resources available? Can it keep up with the pending work (ie. queue depth)
In order to automate this, you’d typically set up alerts to get notified or even use auto-scaling. Kubernetes is a great platform and helps you with this out-of-the-box.
Scaling your cluster can be easily done by using the Cluster Autoscaler component that will monitor your cluster for pods that are unable to be scheduled due to resource starvation and start adding/removing nodes accordingly.
Since Cluster Autoscaler only kicks in when your pods are over-scheduled, you may have a time gap during which your workloads are not up and running.
Virtual Kubelet, a CNCF sandbox project, is a tremendous help that allows you to add a “virtual node” to your Kubernetes cluster on which pods can be scheduled.
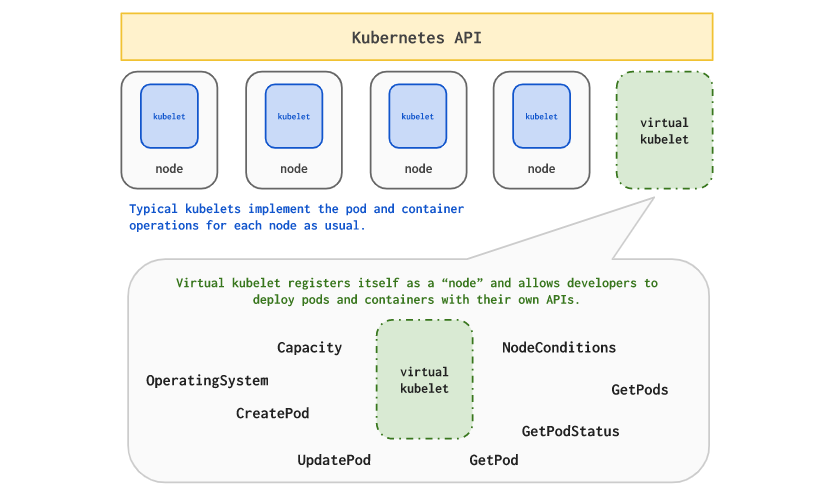
By doing this, platform providers (such as Alibaba, Azure, HashiCorp and others) allow you to overflow your pending pods outside of your cluster until it provides the required cluster capacity to mitigate this issue.
In addition to scaling the cluster, Kubernetes allows you to easily scale your application:
- Horizontal Pod Autoscaler (HPA) allows you to add/remove more pods to your workloads to scale in/out (adding or removing replicas)
- Vertical Pod Autoscaler (VPA) allows you to add/remove resources to your pods to scale up/down (adding or removing CPU or memoru)
All of this combined gives you a very good starting point to scale your application.
The limitations of Horizontal Pod Autoscaler (HPA)
While the HPA is a great place to start, it is mainly focussed on metrics of the pods themselves allowing you to scale it based on CPU & memory. That said, you can fully configure how it should be autoscaled which makes it powerful.
While that is ideal for some workloads, you’d typically want to scale on metrics that are available somewhere else such as Prometheus, Kafka, a cloud provider, or other events.
Thanks to the external metric support, users can install metric adapters that serve a variety of metrics from external services and make them available to autoscale on by using a metric server.
There is one caveat, though, you can only run one metric server inside your cluster which means that you’ll have to choose where your custom metrics come from.
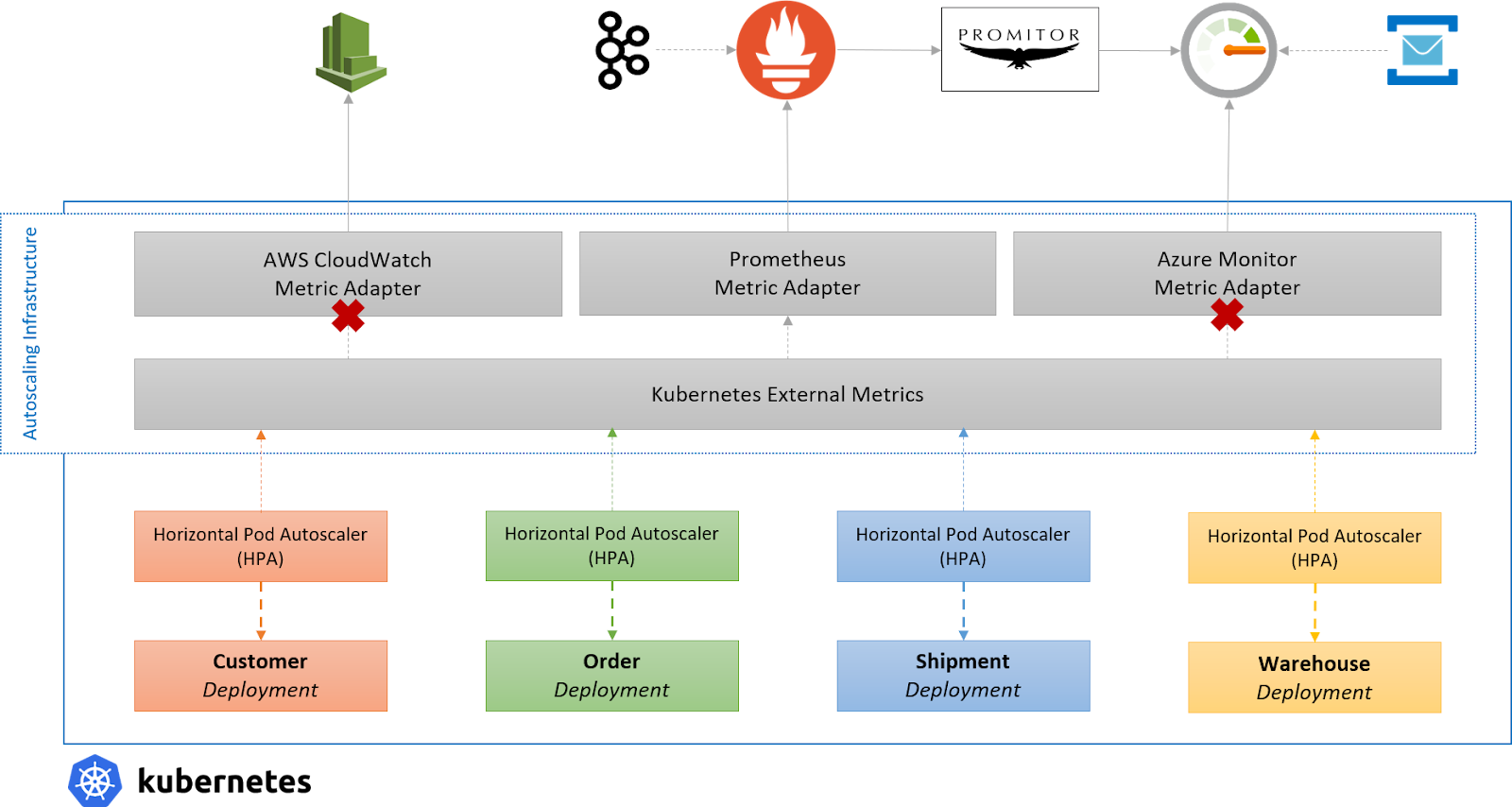
You could use Prometheus and use tools, such as Promitor, to bring your metrics from other providers and use that as a single-source-of-truth to scale on but that requires a lot of plumbing and work to scale.
There must be a simpler way… Yes, use Kubernetes Event-Driven Autoscaling (KEDA)!
What is Kubernetes Event-Driven Autoscaling (KEDA)?
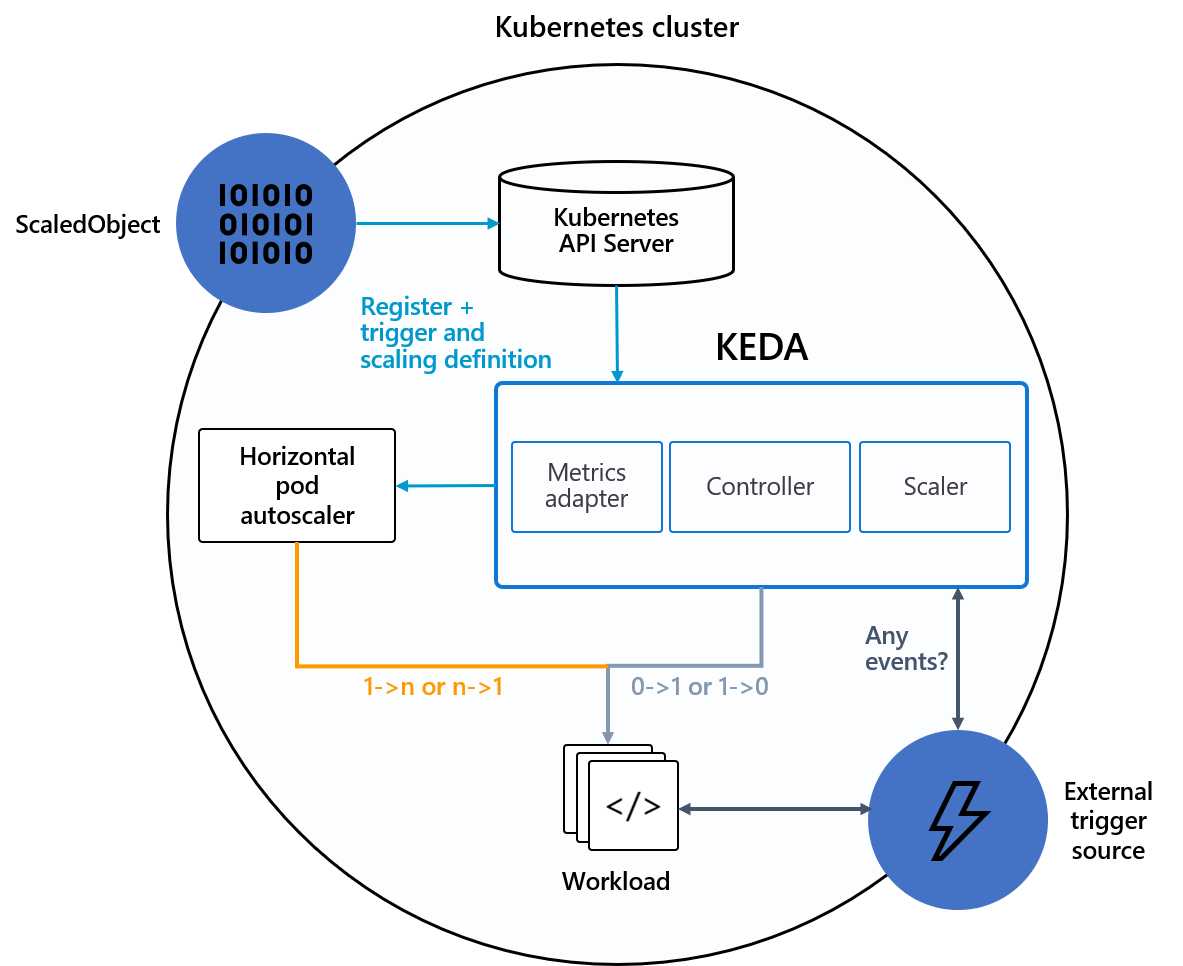
Kubernetes Event-Driven Autoscaling (KEDA) is a single-purpose event-driven autoscaler for Kubernetes that can be easily added to your Kubernetes cluster to scale your applications.
It aims to make application auto-scaling dead-simple and optimize for cost by supporting scale-to-zero.
KEDA takes away all the scaling infrastructure and manages everything for you, allowing you to scale on 30+ systems or extend it with your own scalers.
Users only need to create a ScaledObject or ScaledJob that defines what you want to scale and what triggers you want to use; KEDA will handle all the rest!
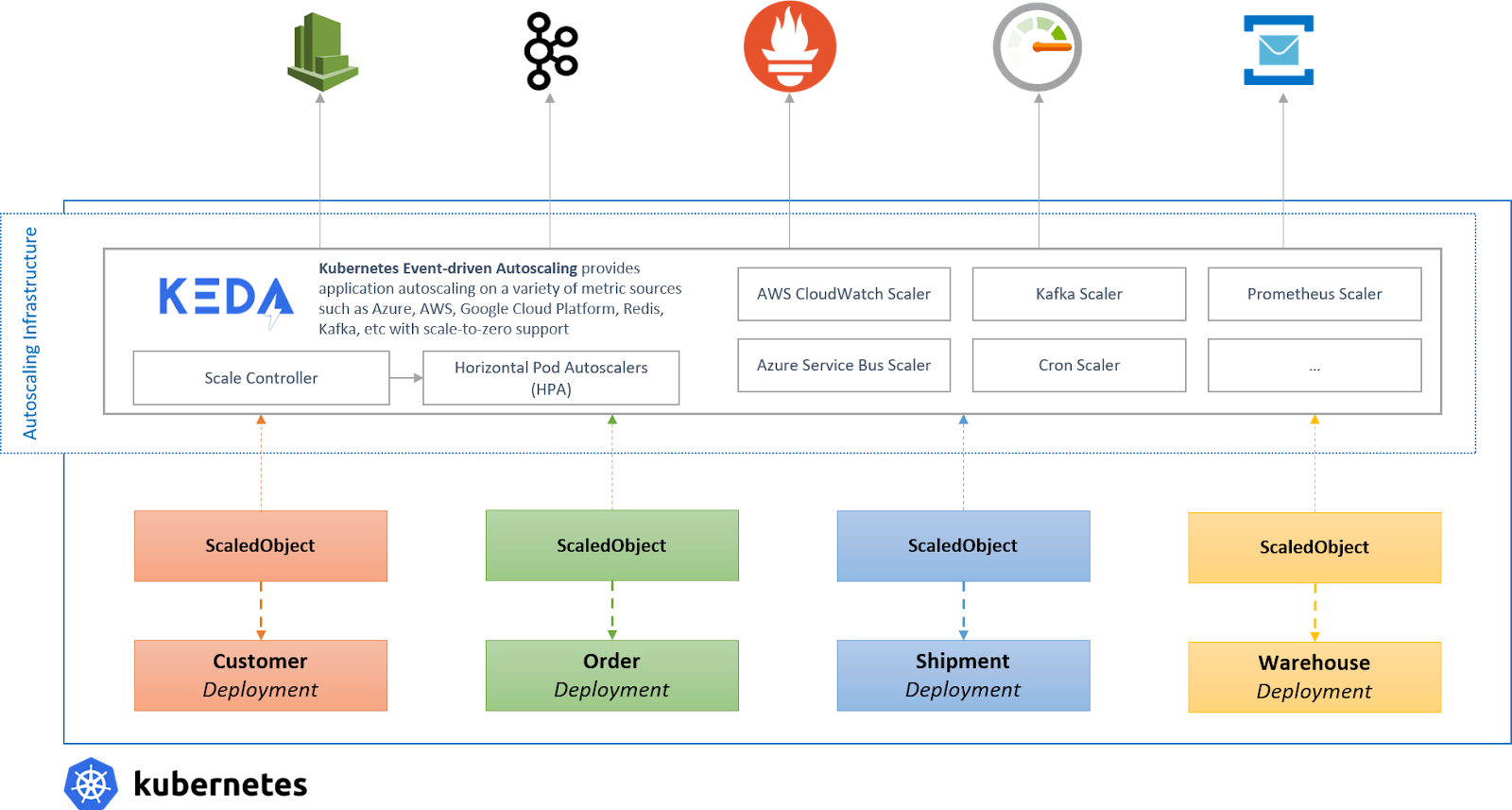
And you can literally scale anything; even if it’s a CRD from another tool you are using, as long as it implements /scale subresource.
So, does KEDA reinvent the wheel? No! Instead, it extends Kubernetes by using HPAs under the hood that use our external metrics which are served from our own metrics adapter that replaces all the other adapters.
Last year, KEDA joined the CNCF as CNCF Sandbox project and is planning to propose to graduate to Incubation later this year.
Introduce Alibaba’s practice based on OAM/KubeVela and KEDA
As the major enterprise PaaS offering on Alibaba Cloud, Enterprise Distributed Application Service (EDAS) has been serving countless developers on the public cloud with massive scale for years. From an architectural perspective, EDAS is built with the KubeVela project. Its overall architecture is like the below.

In production, EDAS integrated ARMS monitoring service on Alibaba Cloud to provide monitoring and fine-grained metrics of the application. EDAS team added an ARMS Scaler to the KEDA project to perform autoscaling. They also added a couple of features and fixed some bugs in the KEDA v1 release. Including:
- When there are multiple Triggers, the values will be summed up rather than leaving them as individual values.
- When creating KEDA HPA, the length of the name will be limited to 63 characters to avoid triggering DNS complaints.
- Triggers can not be disabled and this might cause trouble in production.
EDAS team is actively working on sending these fixes to KEDA upstream, though some of them have already been added to the V2 release.
Why Alibaba Cloud standardized on KEDA as their application autoscaler
When it comes to auto-scaling features, EDAS originally used the upstream Kubernetes HPA with the CPU and Memory as the two metrics in the beginning. However, as the user base grows and requirement diversifies, the EDAS team soon found the limitations of the upstream HPA:
- Limited support for customized metrics, especially for application-level fine-grained metrics
The upstream HPA focuses on the container level metrics, such as CPU and Memory, which is too coarse for the applications. Metrics that reflect the application loads, such as RT and QPS are not supported out of the box. Yes, HPA can be extended. However, that capability is limited when it comes to application-level metrics. EDAS team was often forced to fork code when trying to introduce fine-grained application-level metrics. - No support for scale-to-zero
Many users have the requirement of Scale to Zero when their microservices are not being consumed. This requirement is not limited just to FaaS/Serverless workloads. It saves costs and resources for all users. Currently, upstream HPA doesn’t support this feature. - No support for scheduled scaling
Another strong requirement from the EDAS users is the scheduled scaling capability. Again, upstream HPA doesn’t provide this feature, and the EDAS team needs to look for non-vendor lock alternatives.
Based on those requirements, the EDAS team started planning the new version of EDAS auto-scaling feature. In the meantime, EDAS went through an overhaul of its underlying core components by introducing OAM at the beginning of 2020. OAM gives EDAS the standardized, pluggable application definition to replace its in-house Kubernetes Application CRD. And the extensibility of this model makes it possible for EDAS to integrate with any new capability from the Kubernetes community with ease. In that context, the EDAS team tried to align the need for new auto-scaling features for EDAS with looking for a standard implementation for OAM’s autoscaling trait.
Base on the use cases, the EDAS team summarized three criteria:
- The auto-scaling feature should present itself as a simple atomic capability without attachment to any complex solutions.
- The metrics should be pluggable, so the EDAS team can customize it and build on top of it to support various requirements.
- It should support Scale to Zero out of the box.
After detailed evaluation, the EDAS team picked the project KEDA, which was open-sourced by Microsoft & Red Hat and has been donated to CNCF. KEDA has several useful Scalers that come by default and supports Scale to Zero out of the box. It provides fine-grained auto scaling for applications. It has the concept of Scalar and Metrics adapter, which enables powerful plugin architecture while providing a unified API layer. Most importantly, the design of KEDA focuses on autoscaling only so it can be integrated as an OAM trait at ease. Overall, KEDA is a good fit for EDAS.
Looking Ahead
As the next step, Alibaba is actively working on making KEDA trait driven by AIOps, with the goal to bring intelligent decision making to its autoscaling behavior. This will essentially enable autoscaling decisions based on expert system and historical data analysis with leverage of newly implemented application QoS trigger and database metrics trigger etc in Alibaba’s KEDA components. Thus, we will expect a more powerful, intelligent, and stable KEDA based auto-scaling capability will be shipped in KEDA soon.
Source CNCF
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!