Guest post by Akash Bakshi at MSys Technologies
AWS is known to be a high-performance, scalable computing infrastructure, which more and more organizations are adapting to modernize their IT. However, one must be aware that no system is secure enough to ensure business continuity! Hence, you must have some kind of plan in place for your disaster recovery. With this article, we aim to discuss the top three Disaster Recovery scenarios that show the use of AWS:
From our partners:
- Backup and Restore
- Pilot Light for Simple Recovery into AWS
- Multi-site Solution
Amazon Web Services (AWS) enables you to operate each of these three examples of DR strategies, and that too cost-effectively. However, it’s also essential to note that these are only examples of the potential approaches, but variations and combinations of these are also possible.
Backup and Restore
In most of the common environments, the data is usually backed up to tape and sent off-site on a regular basis. Also, using this method, the recovery time will be the longest. Amazon S3 is the perfect destination for backup data. It is designed to offer nearly 99.999999999% (11 9s) durability of objects over a year. Transferring data across Amazon S3 is mainly done through the network to make it accessible from any location. Numerous commercial and open-source backup solutions provide backup to Amazon S3. In addition, the AWS Import/Export service allows the transfer of vast data sets by just shipping storage devices directly to AWS.
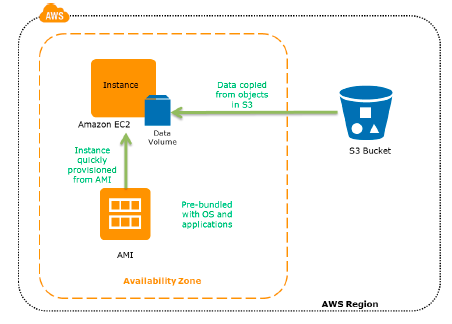
The AWS Storage Gateway service facilitates snapshots of on-premise data volumes to be copied transparently into Amazon S3 for backup. You can consequently create local volumes or AWS EBS volumes from these snapshots.
For the systems that are operating on AWS, clients can also back up into Amazon S3. For example, snapshots of Elastic Block Store (EBS) volumes and backups of Amazon RDS are stored in Amazon S3. Also, you can copy the files straight into Amazon S3 or choose to create backup files and copy them to Amazon S3. Numerous backup solutions store your backup data in Amazon S3, and these can also be used from Amazon EC2 systems.

However, backing up the data is just half the story. The recovery of the data in a disaster scenario needs to be tested and achieved quickly and reliably. Clients must make sure that their systems are configured to appropriate retention of data, security of data, and have tested their data recovery processes.
Here are some essential steps for backup and restore:
- Pick a suitable tool or approach to back up your data into AWS.
- Make sure that you have a proper retention policy in place for this data.
- Make sure that suitable security measures are taken for this data, involving encryption and access policies.
- Constantly test the recovery of this data and restoration of your system.
Pilot Light for Faster Recovery into AWS
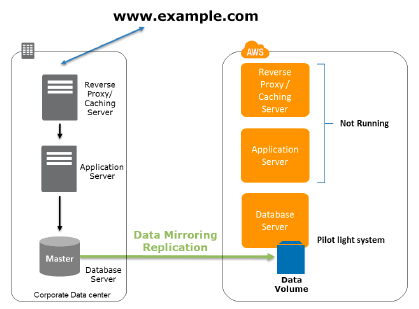
The word “Pilot light” came into picture from a “gas heater.” Imagine, a gas heater is a small idle flame that’s always on, which can instantly ignite the furnace to heat up a house as and when required. The backup and restore scenario is similar to this gas heater scenario. However, you must also make sure that the most critical core elements of your system are already configured and operating in AWS (the pilot light).
Infrastructure components for the pilot light usually involve database servers, which can replicate data to Amazon EC2. Depending on the system, other crucial data outside the database must be replicated to AWS. This is the decisive core of the system (the pilot light) around which all other infrastructure elements in AWS can instantly be provisioned (the rest of the furnace) to restore the entire system.
The ‘Pilot Light’ approach gives a quicker ‘Recovery Time’ than the “Backup and Restore” scenario mentioned above because the core sections of the system are already operating and are continuously kept up to date. However, there are still some installation and configuration tasks to recover the applications completely. AWS allows you to automate the provisioning and configuration of the infrastructure resources, which can be an essential benefit to save time and improve protection against human errors.
Preparation Phase
Here are some essential points to remember during preparation phase:
- Set up your EC2 instances to mirror or replicate data.
- Make sure that all supporting customized software packages are available in AWS.
- Creating and Maintaining Amazon Machine Images (AMI) of key servers where faster recovery is needed.
- Continuously run these servers, test them, and implement any software updates and configuration modifications.
- Automate the provisioning of AWS resources.
Recovery Phase
In the recovery phase of the Pilot light scenario, key points for recovery:
- Begin application EC2 instances from customized AMIs.
- Resize and/or scale any database/data store instances, where required.
- Modify DNS to point at the EC2 servers.
- Install and configure any non-AMI-driven systems, typically in an automated fashion.
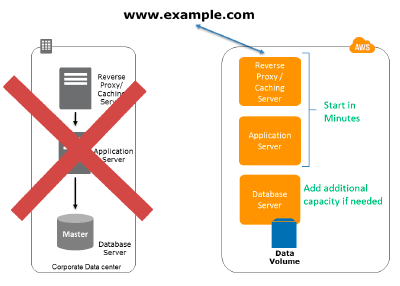
Figure 4: The recovery phase of the Pilot light.
Multi-Site Solution deployed on AWS and on-Site
A multi-site solution operates in AWS and on existing on-site infrastructure in an active-active configuration. The data replication approach that you should employ can be defined by the selected recovery point (RPO). Like Amazon Route 53, a weighted DNS service is employed to route production traffic to different sites. A portion of traffic will go to the infrastructure in AWS, and the rest goes to the on-site infrastructure.
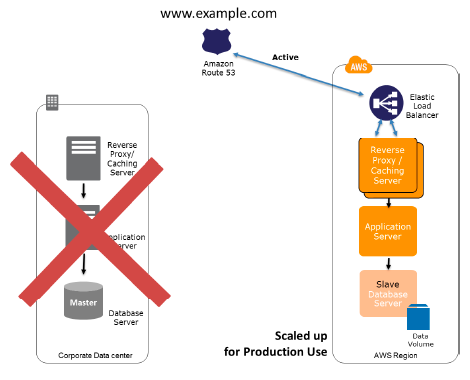
In case of an on-site disaster, you can modify the DNS weighting and send all traffic to the AWS servers. Thus, the capacity of the AWS service can be rapidly expanded to maintain the entire production load. EC2 Auto Scaling can be employed to automate this process. You might require some application logic to identify the failure of the primary database services and cut over to the parallel database services operating in AWS.
The expense of this scenario is defined by the production traffic, which is handled by AWS in regular operation. In the recovery phase, you need to only pay for what you use in addition and for the duration that the Disaster Recovery environment is utilized at full scale. You can considerably reduce costs by purchasing Reserved Instances for “always on” AWS servers.
Preparation Phase:
Here are some key points for preparation:
- Setting up AWS environment to replicate the production environment.
- Setting up DNS weighting or related technology to distribute incoming requests to both sites.
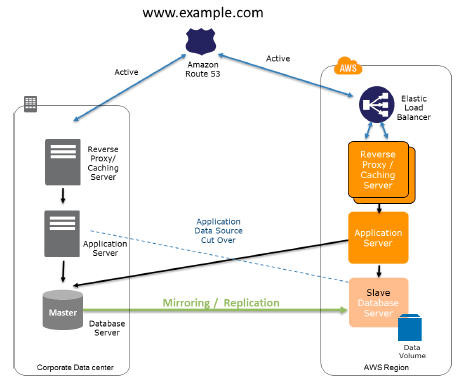
Recovery Phase:
Some key points for recovery in Multi-site solution:
- Modify the DNS weighting, so that all requests are transferred to the AWS site.
- Have application logic for failover to make use of the local AWS database servers.
- Consider employing Auto scaling to automatically right-size the AWS fleet.
You can also further enhance the availability of the multi-site solution by devising Multi-AZ architectures.
Conclusion
Several possibilities and variations for DR do exist, and this article highlights some of the most popular patterns, ranging from simple backup and restore to fault-tolerant multi-site solutions. AWS offers a fine-grained control and several building blocks to develop the fitting DR solution, given your DR goals (RTO and RPO) and budget. In addition, the AWS services are available on-demand, where you pay only for what you use. This is a crucial advantage for DR, where significant infrastructure is required instantly, but only in case of a disaster. This article has shown how AWS offers flexible, cost-effective infrastructure solutions, allowing you to have a more effective DR plan in place.
About MSys Technologies (named to the 2021 Global Outsourcing 100 List): We are a Kubernetes Certified Service Provider and CNCF Silver member. We architect, develop, and manage modern distributed systems leveraging open-source, cloud-native, and containerized technologies with a Kubernetes-centric focus.
Author
Akash Bakshi is a Bangalore-based writer and lifelong learner with an ongoing curiosity to learn new things. He uses that curiosity, combined with his near a decade of experience as a technology writer who writes about subjects valuable to the tech industry with technologies/practices such as Cloud computing, AI, ML, SRE, DevOps, among others. Currently, he works with MSys Technologies as a Lead Content Writer.
By Akash Bakshi
Source CNCF
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!