
We are pleased to announce the general availability of Customer Managed Encryption Keys (CMEK) integration for Cloud Data Fusion. CMEK enables encryption of both user data and metadata at rest with a key that you can control through Cloud Key Management Service (KMS). This capability will help meet the security, privacy and compliance requirements of CDF customers (particularly in regulated industries) for mission-critical workloads.
Data Fusion already supported encrypting all user data generated on popular Google Cloud services such as Cloud Storage, BigQuery, Cloud Spanner with CMEK. This release takes it a step further by allowing customers to use their own keys for encrypting Data Fusion metadata at rest. In particular, this latest CMEK integration provides users control over encryption keys for the data written to Google internal resources in tenant projects and data written by Cloud Data Fusion pipelines, including:
From our partners:
- Pipeline logs and metadata
- Dataproc cluster metadata
- Various Cloud Storage, BigQuery, Pub/Sub, and Cloud Spanner data sinks, actions, and sources
Getting started with CMEK for Cloud Data Fusion
1. Protecting Data Fusion metadata at rest using CMEK
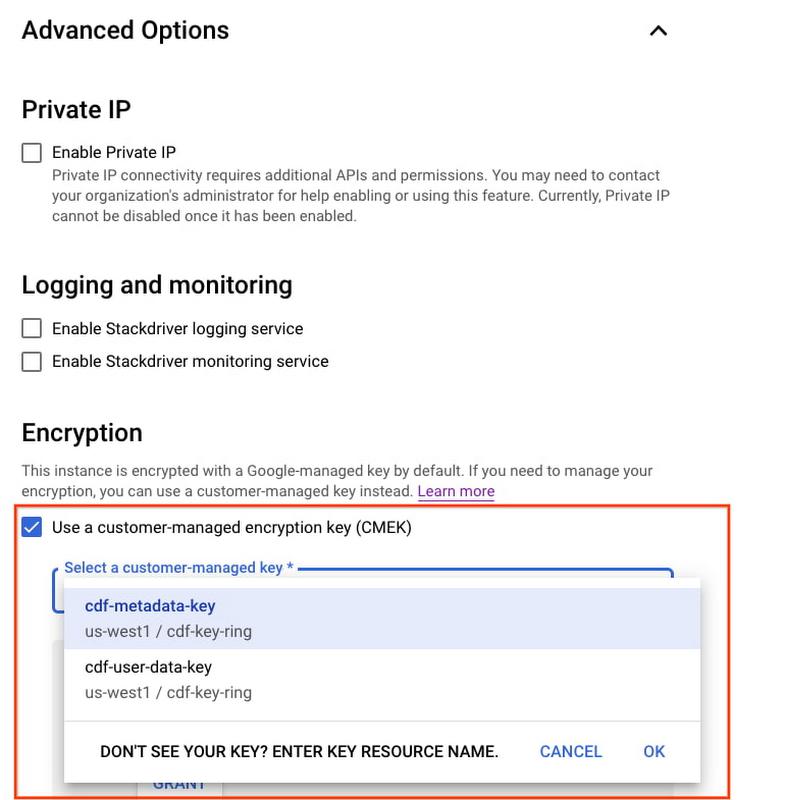
When you create, run and manage data pipelines using Data Fusion, various types of metadata such as pipeline specifications, pipeline artifacts, run history, logs and metrics, as well as lineage and discovery metadata are stored in Data Fusion’s metadata repository in a tenant project. This metadata can now be easily encrypted using CMEK by simply providing the full CMEK resource name while creating the Data Fusion instance, as shown in the picture below. Note that the encryption mechanism of an instance cannot be changed after creation. In order to specify the CMEK resource, follow the steps below, while creating a Data Fusion instance:
- Open the Advanced section of the instance creation form
- Select the “Use a customer-managed encryption key (CMEK)” option in the Encryption section.
- Choose from a list of Customer Managed Encryption Keys, or specify a key manually by entering its full resource name (in the format
projects/project-name/locations/global/keyRings/my-keyring/cryptoKeys/my-key)
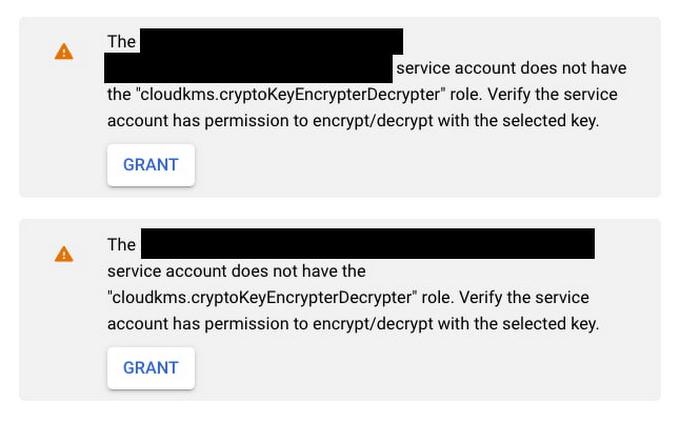
Once you’ve selected or specified a key, you may also need to additionally provide both the Data Fusion service account and the default compute engine service account (used for running pipelines on Dataproc clusters by default) permissions to encrypt and decrypt keys. This can be done by granting the cloudkms.cryptoKeyEncrypterDecrypter role to these service accounts, and can be done right in the same UI by clicking the GRANT button.
2. Protecting user data at rest using CMEK in Data Fusion pipelines
In addition to protecting metadata at rest, you can also protect any newly created resources in supported Google Cloud services such as Cloud Storage, BigQuery, Cloud Spanner, Pub/Sub, and more using CMEK. In order to protect your newly created data using CMEK in Data Fusion pipelines, you have a couple of options:
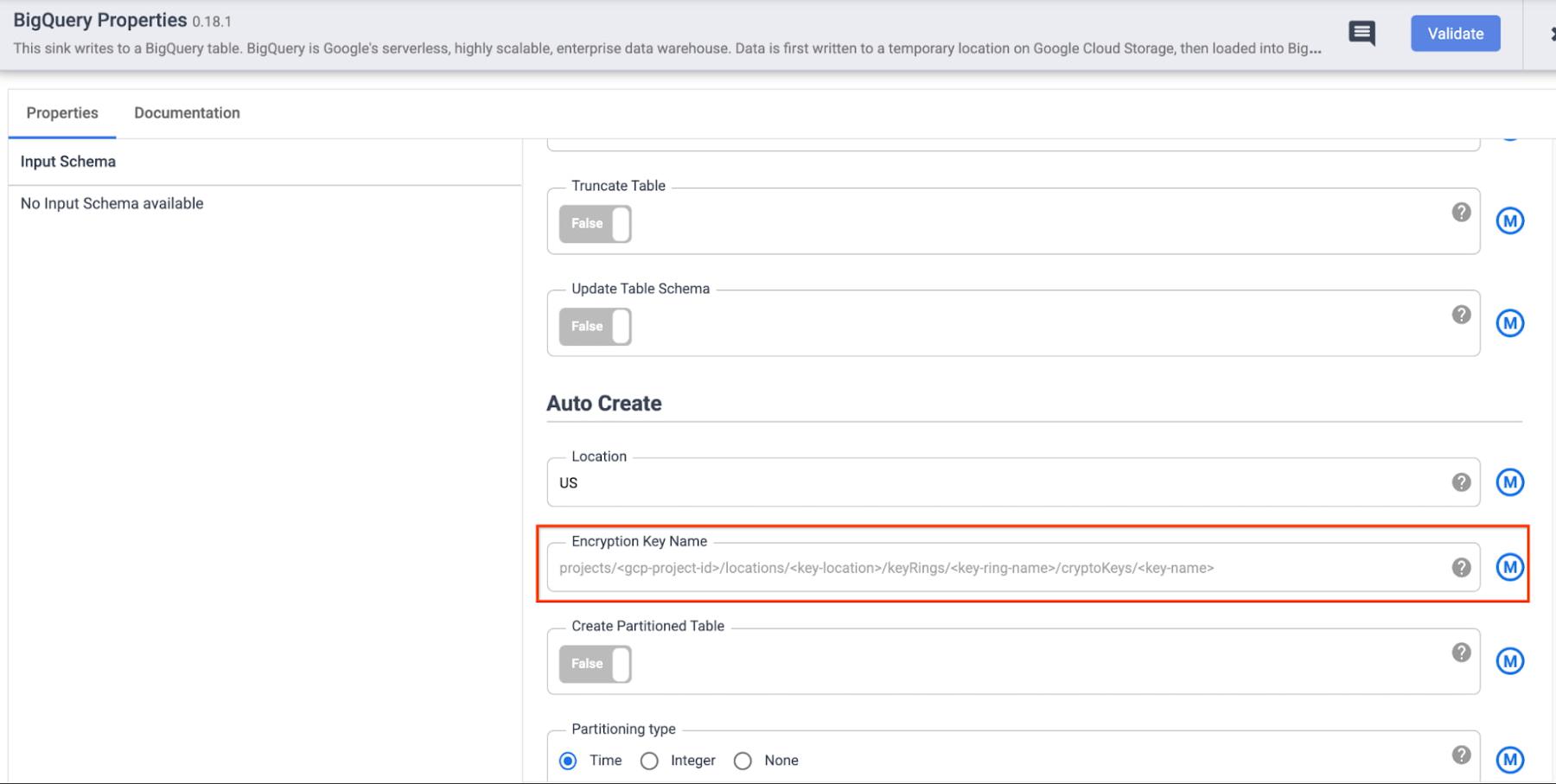
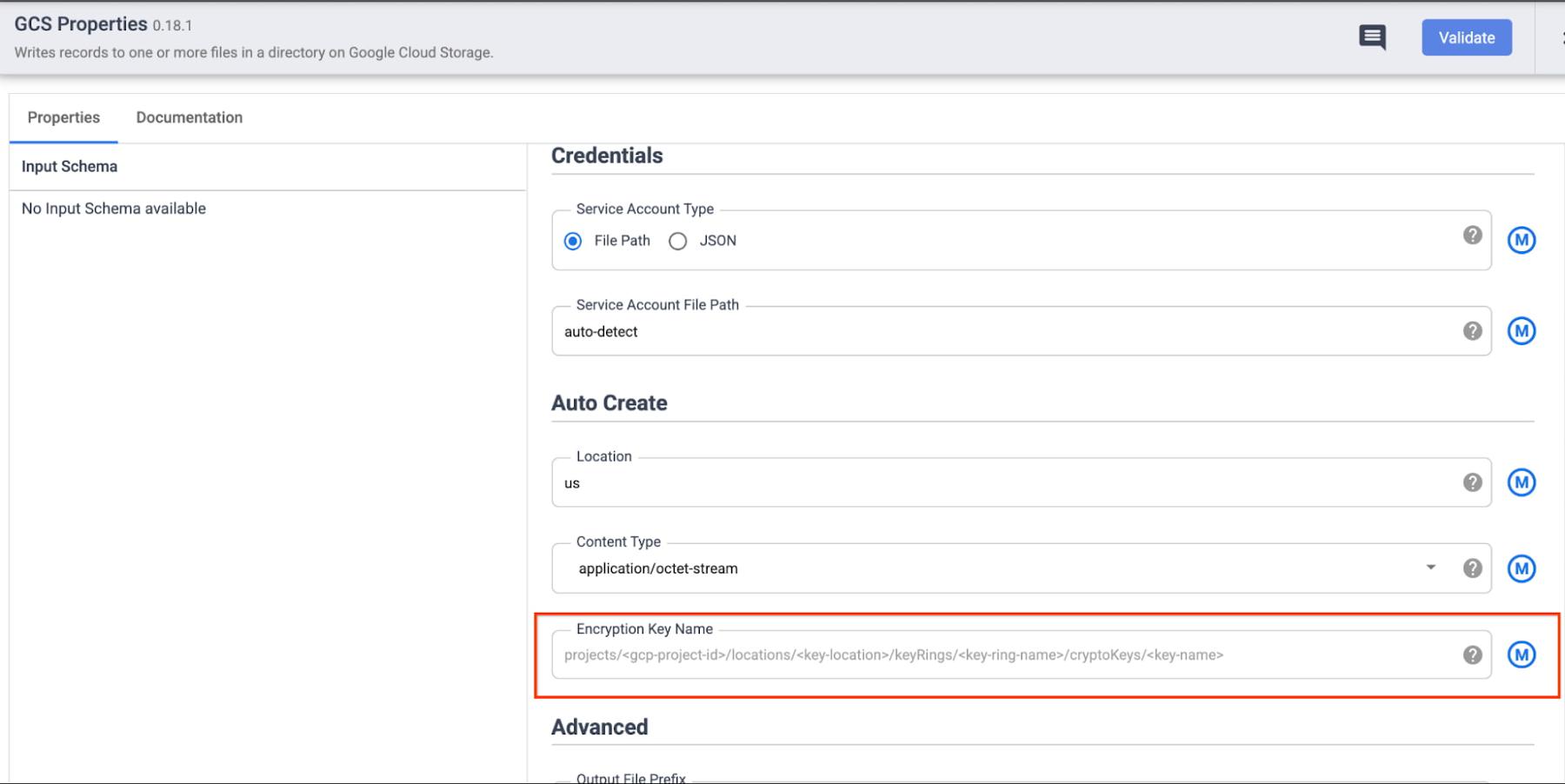
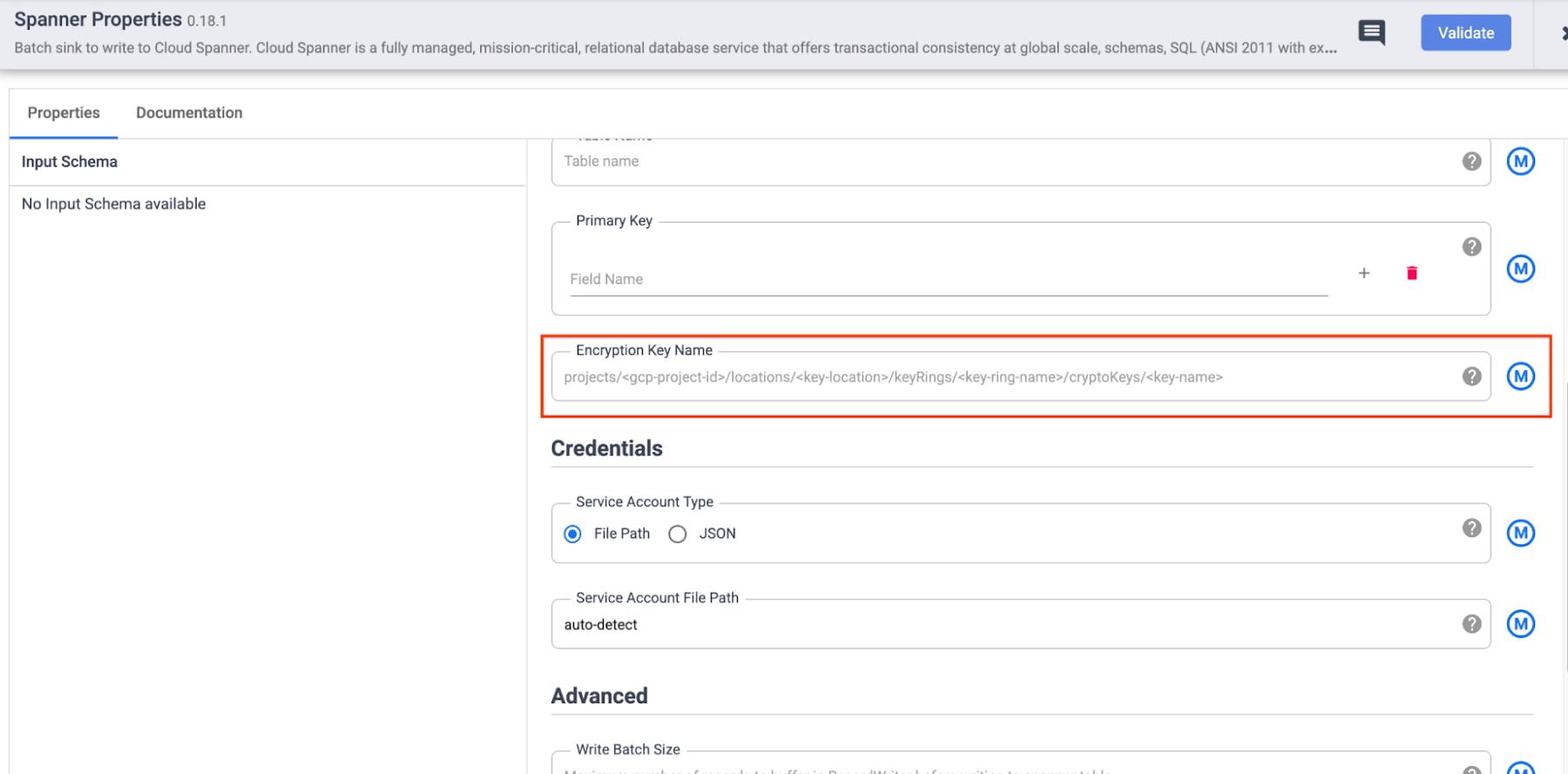
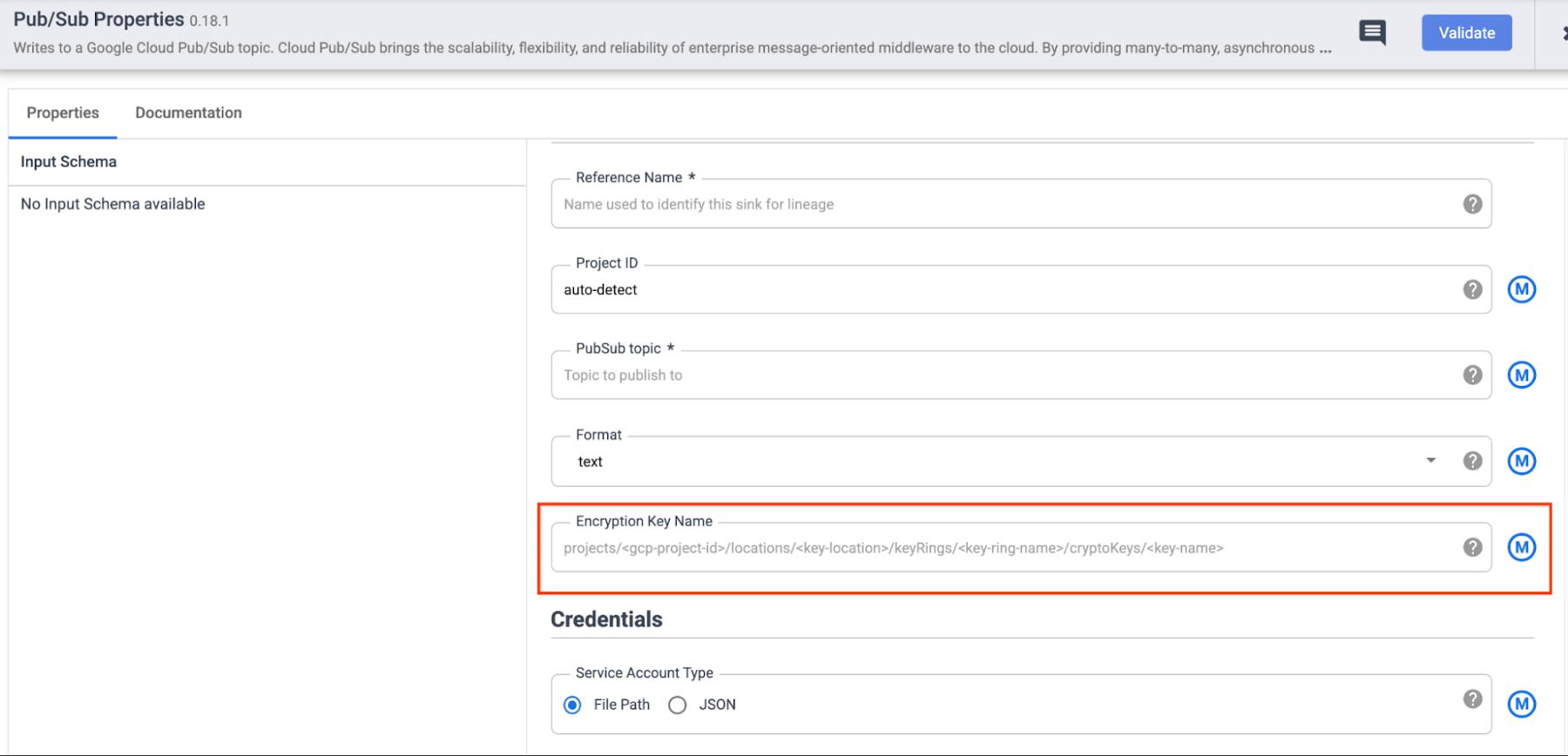
a. Specify the full CMEK resource name in the configuration of the respective sink. This is useful when you want to (potentially) protect the data in each sink with a different key. Some examples of CMEK being used to protect data written through Data Fusion sinks are below:
- BigQuery Sink:
- GCS Sink:
- Cloud Spanner Sink:
- Pub/Sub Sink:
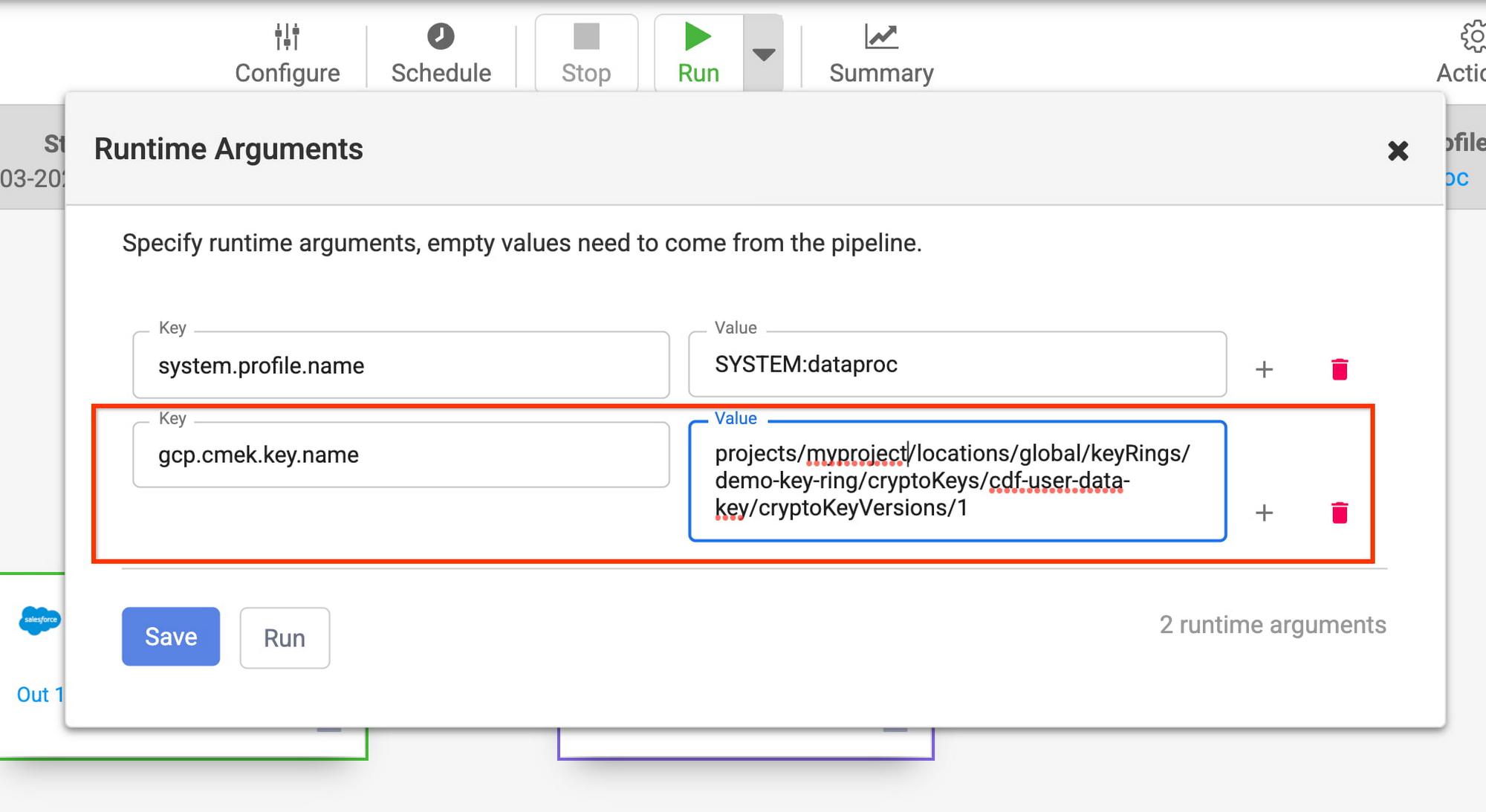
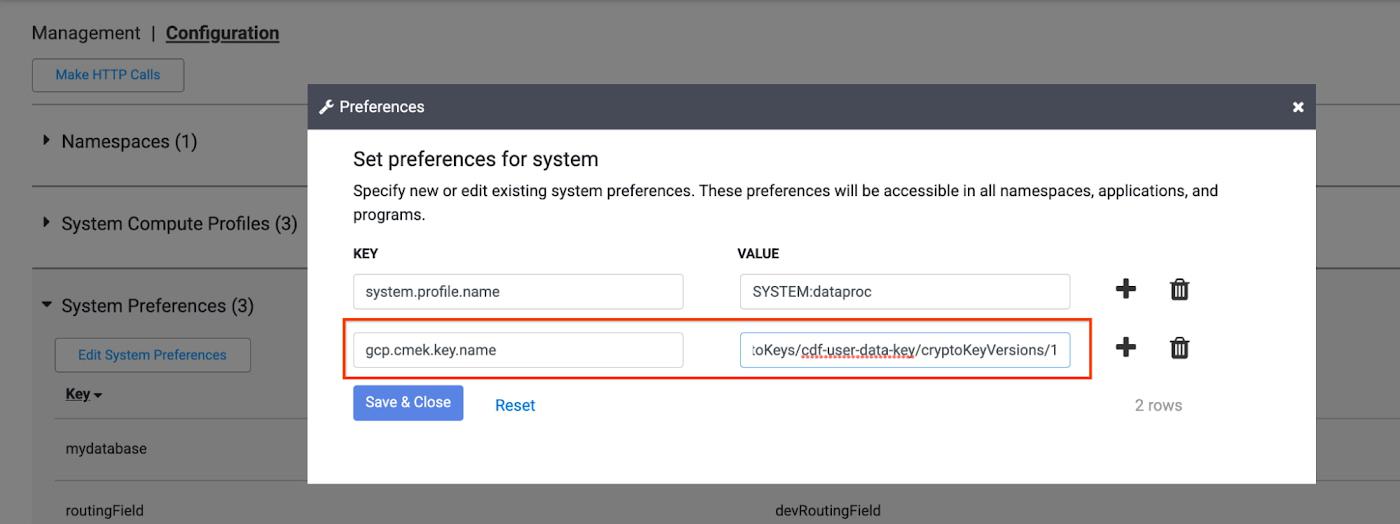
b. Specify the full CMEK resource name as a preference. This is useful when you want to use the same CMEK to protect newly created data in all sinks in a given pipeline, namespace or instance. In order to do so, specify the full CMEK resource name as the preference key gcp.cmek.key.name at the pipeline, namespace or instance level.
- Pipeline level: At the pipeline level, the CMEK key can be set either as a runtime argument (if you only want to set it for a particular run) or as a pipeline level preference (if you want to set it for all pipeline runs)/
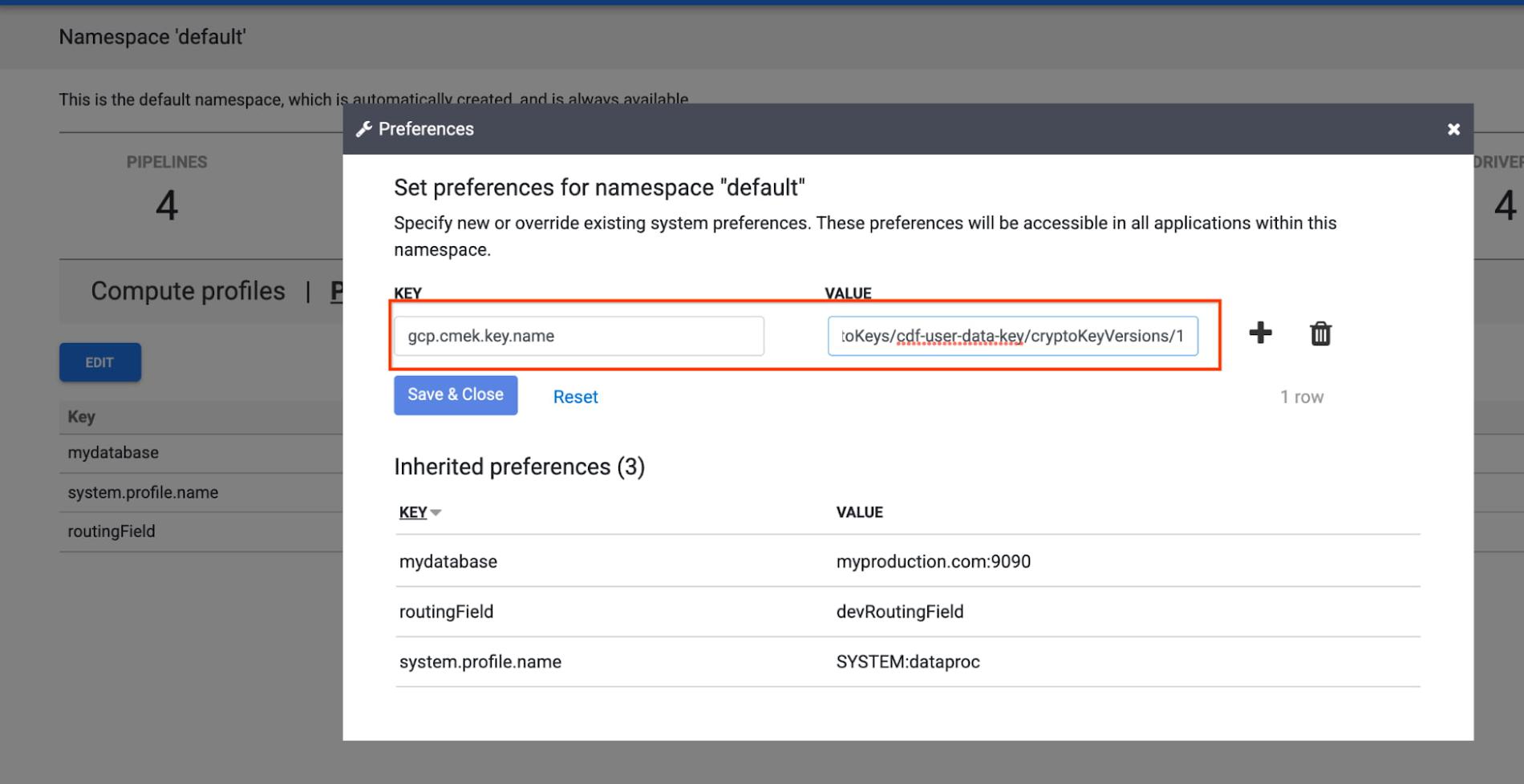
- Namespace level: At the namespace level, the CMEK key can be set as a preference on the namespace details page. All CMEK-supported sinks in such a namespace will use this key unless a key is explicitly provided either at the pipeline level or in the specific sink’s plugin configuration.
- Instance level: At the instance level, the CMEK key can be set as a preference on the System Admin page. All CMEK-supported sinks on the instance will use this key unless a key is explicitly provided either at the namespace level, the pipeline level or in the specific sink’s plugin configuration.
Priority order for CMEK for user data
Another key feature to note with CMEK for user data in Data Fusion is the priority order in which the key is chosen. As we have already seen in the previous section, CMEK can be specified at various levels in Data Fusion. These configurations follow the priority order below:
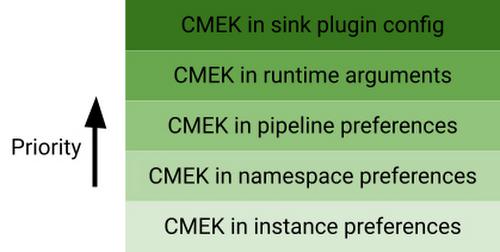
As you can see, CMEK in instance preferences has the lowest precedence, while CMEK in the sink plugin config has the highest precedence. You can use this powerful capability to appropriately set CMEK in your Data Fusion pipelines.
We are excited to roll out this critical feature to Data Fusion customers. For more information about using CMEK with Data Fusion, please refer to the documentation. For a list of Cloud Data Fusion plugins that support CMEK, see the supported plugins. We are committed to provide a secure and compliant cloud data integration service in Cloud Data Fusion. Stay tuned for more updates in this area in future.
By: Bhooshan Mogal (Product Manager)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







