
Cloud Spanner is Google Cloud’s fully managed relational database that offers unlimited scale, strong consistency across regions, and high availability up to 99.999%. Spanner handles more than two billion requests per second. Spanner is trusted by customers in financial services, retail, gaming and many other industries. We are excited to announce that Spanner has doubled the storage capacity for all Cloud Spanner instances to help customers optimize the compute cost of storage intensive workloads. For example, Cloud Spanner instances with 1 node (1,000 processing units) can now have 4TB storage capacity instead of 2TB (8TB per 2 nodes, 12TB for 3 nodes, and so on)
Customers building applications such as transactional ledger or inventory management on Spanner have higher storage requirements in comparison to compute requirements. As they scale storage, they end up over-provisioning compute to support the storage, incurring additional cost. We have increased the storage per node so that customers can better align their costs with their usage.
From our partners:
With this launch, current users are automatically upgraded to the increased storage capacity without the need to opt-in or create new instances. This feature does not change storage pricing or the way storage is billed in Spanner. Users still pay for the actual storage their database uses, regardless of the storage capacity Spanner provisions. To view the storage capacity available for your Spanner instance, visit Cloud Console, select Spanner and click on any instance. You should now see the upgraded capacity of 4TB per node.
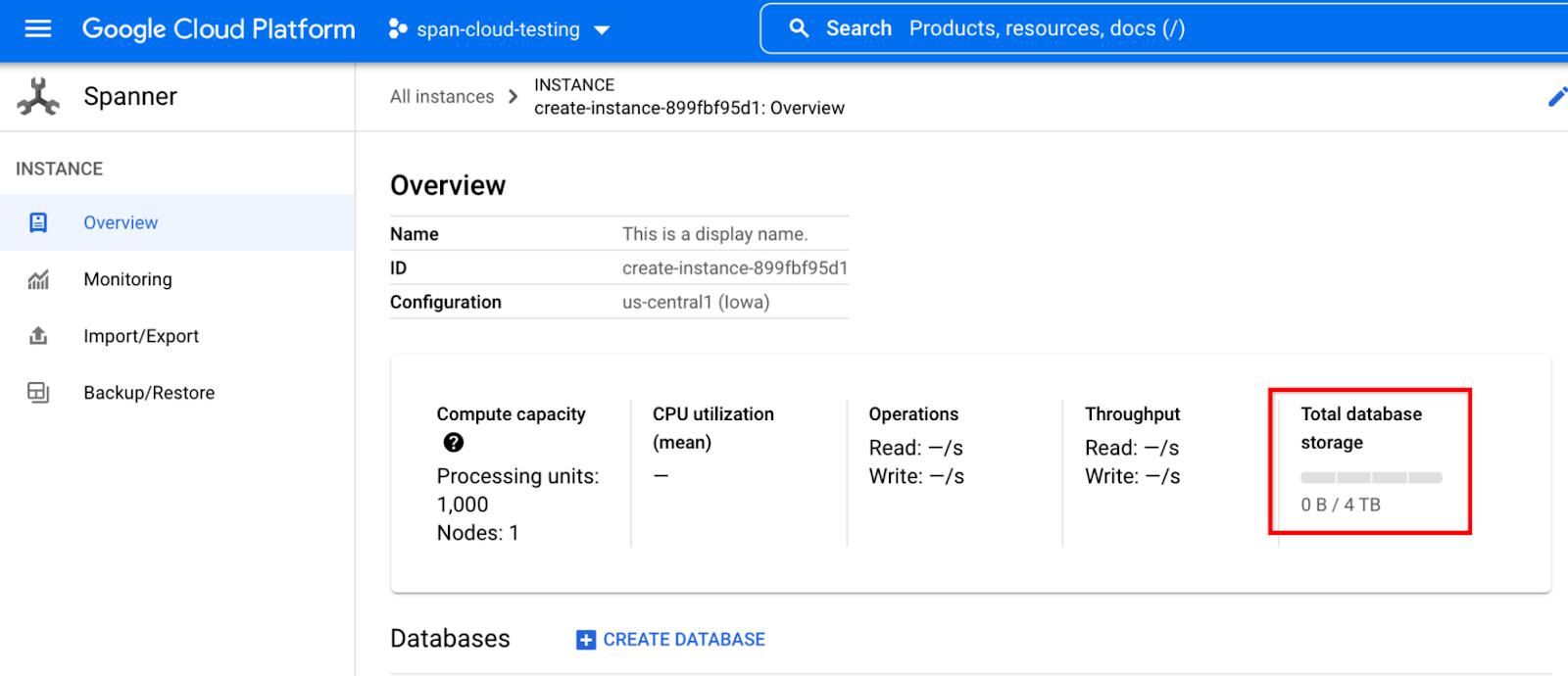
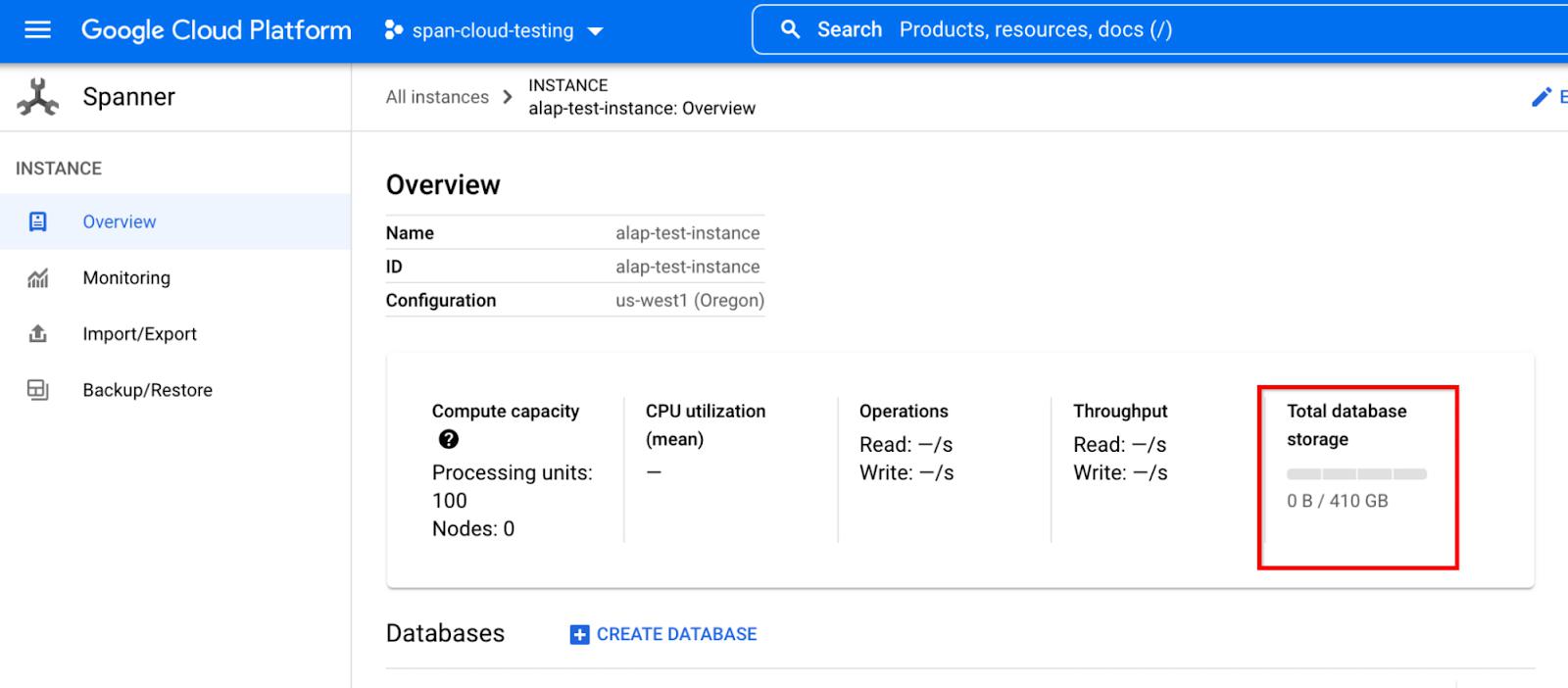
We’ve doubled the storage capacity for users who are using granular instance sizing (less than 1000 processing unit instances, or 1 node) as well. Each 100 processing units of compute capacity can support 410 GB of storage.

Previously if you had a storage-intensive workload, you had to over-provision compute (e.g. you had to provision at least 50 nodes of compute capacity to get a storage capacity of 100TB). Now, you can get more storage capacity without unnecessary compute (e.g. you can get 100TB of storage capacity with just 25 nodes). This provides an excellent opportunity to reduce your compute costs up to 50% for storage-intensive workloads. However, be careful not to under-provision compute as per the below guidelines.
To gauge compute requirements, CPU utilization metrics can be used to monitor the present workload. Cloud Spanner uses CPU to serve read-write data requests as well as process background system tasks such as compaction and splitting. We recommend that you leave some head room for system tasks and unexpected bursts in data requests. When scaling down, we recommend you to monitor high priority CPU utilization to make sure it stays within the recommended limits for single or multi-region instances so that the CPU headroom can help in databases continuing to serve data requests even in case of zonal or regional failures. For single region instances, we recommend a high priority CPU utilization threshold of 65% and for multi-region instances, we recommend a high priority CPU utilization threshold of 45%. With the new storage capacity, if you are reducing the number of nodes, reduce it only up to the extent that these CPU utilization thresholds are not exceeded.
For example, with previous capacity, let us say you had 50 nodes and 100TB storage in your single region Spanner instance with 40% high CPU utilization. With the new limit, if you reduce the number of nodes to 25 from 50, high priority CPU utilization will rise to around 80% (above the recommended threshold of 65%). So, in this case, you can reduce the number of nodes to 31 instead of reducing to 25, so that the CPU utilization is still below 65%. Please note that it’s recommended to scale down in stages to avoid performance impact.
In summary, Spanner has doubled the storage capacity for all instances from 2TB storage per node to 4TB storage per node to help reduce the compute cost of storage intensive workloads. For more information on Cloud Spanner, watch this youtube video or visit the Cloud Spanner documentation.
By: Matthew Mucklo (Staff Software Engineer) and Shambhu Hegde (Product Manager, Google Cloud)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







