
If you’re trying to learn a new database, you’ll want to kick the tires by loading in some data and maybe doing a query or two. Cloud Bigtable is a powerful database service for scale and throughput, and it is quite flexible in how you store data because of its NoSQL nature. Because Bigtable works at scale, the tools that you use to read and write to it tend to be great for large datasets, but not so much for just trying it out for half an hour. A few years ago, I tried to tackle this by putting together a tutorial on importing CSV files using a Dataflow job, but that requires spinning up several VMs, which can take some time.
Here on the Bigtable team, we saw that the CSV import tutorial was a really popular example despite the need to create VMs, and we heard feedback from people wanting a faster way to dive in. So now we are excited to launch a CSV importer for Bigtable in the cbt CLI tool. The new importer takes a local file and then uses the Go client library to quickly import the data without the need to spin up any VMs or build any code.
From our partners:
Installation
If you already have the gcloud with the cbt tool installed, you just need to ensure it is up to date by running gcloud components upgrade. Otherwise, you can install gcloud which includes the cbt tool.
If you’re unable to install the tools on your machine, you can also access them via the cloud shell in the Google Cloud console.
Importing data
I have a csv file with some time series data in the public Bigtable bucket, so I’ll use that for the example. Feel free to download it yourself to try out the tool too. Note that these steps assume that you have created a Google Cloud project and a Cloud Bigtable instance.
gsutil cp gs://cloud-bigtable-public-datasets/csv-import-blog-data.csv .
You need to have a table ready for the import, so use this command to create one:
cbt createtable mobile-time-series families="cell_data"
Then, to import the data use the new cbt import command:
cbt import mobile-time-series csv-import-blog-data.csv column-family=cell_data
You will see some output indicating that the data is being imported. After it’s done you can use cbt to read a few rows from your table:
cbt read mobile-time-series
If you were following along, be sure to delete the table once you’re done with it.
cbt deletetable mobile-time-series
CSV format
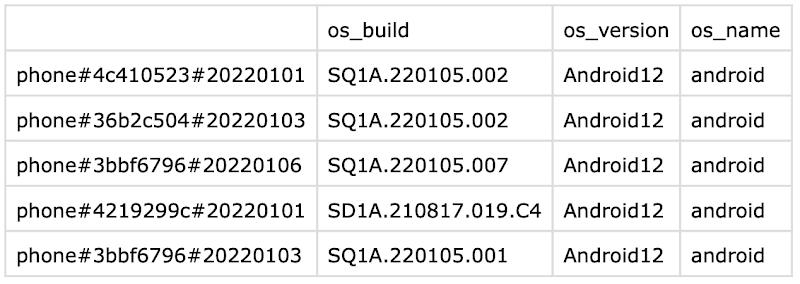

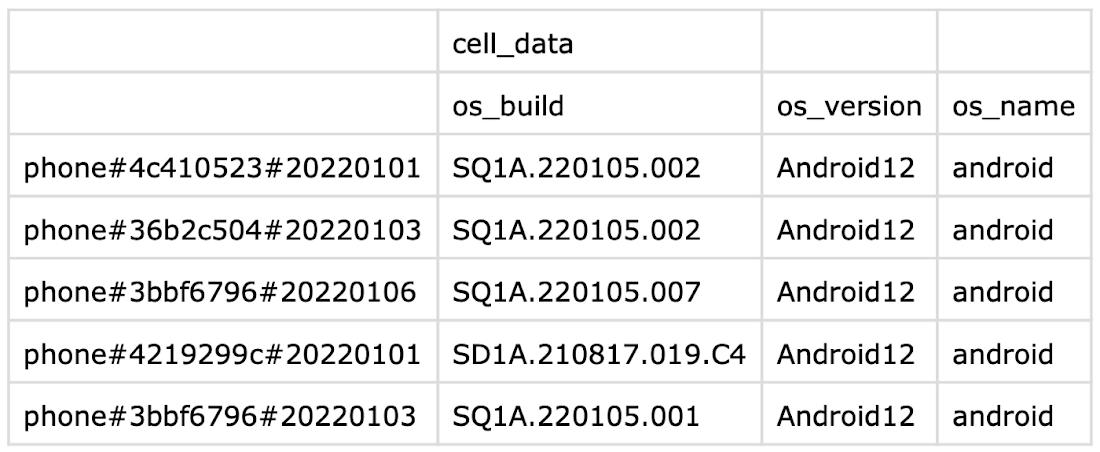

The CSV file uses one row of headers specifying the column qualifiers and a blank for the rowkey. You can add an additional row of headers for the column families and then remove the column-family argument from the import command.
I hope this tool helps you get comfortable with Bigtable and can let you experiment with it more easily. Get started with Bigtable and the cbt command line with the Quickstart guide.
By: Billy Jacobson (Developer Advocate, Cloud Bigtable)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







