
The Securities Technology Analysis Center (STAC®), an organization that improves technology discovery and assessment in the finance industry through dialog and research, recently audited the STAC-M3™ benchmark suite on Google Cloud (SUT ID KDB211210). These enterprise tick-analytics benchmarks assess the ability of a solution stack such as database software, servers, and storage, to perform a variety of I/O-intensive and compute-intensive operations on historical market data.
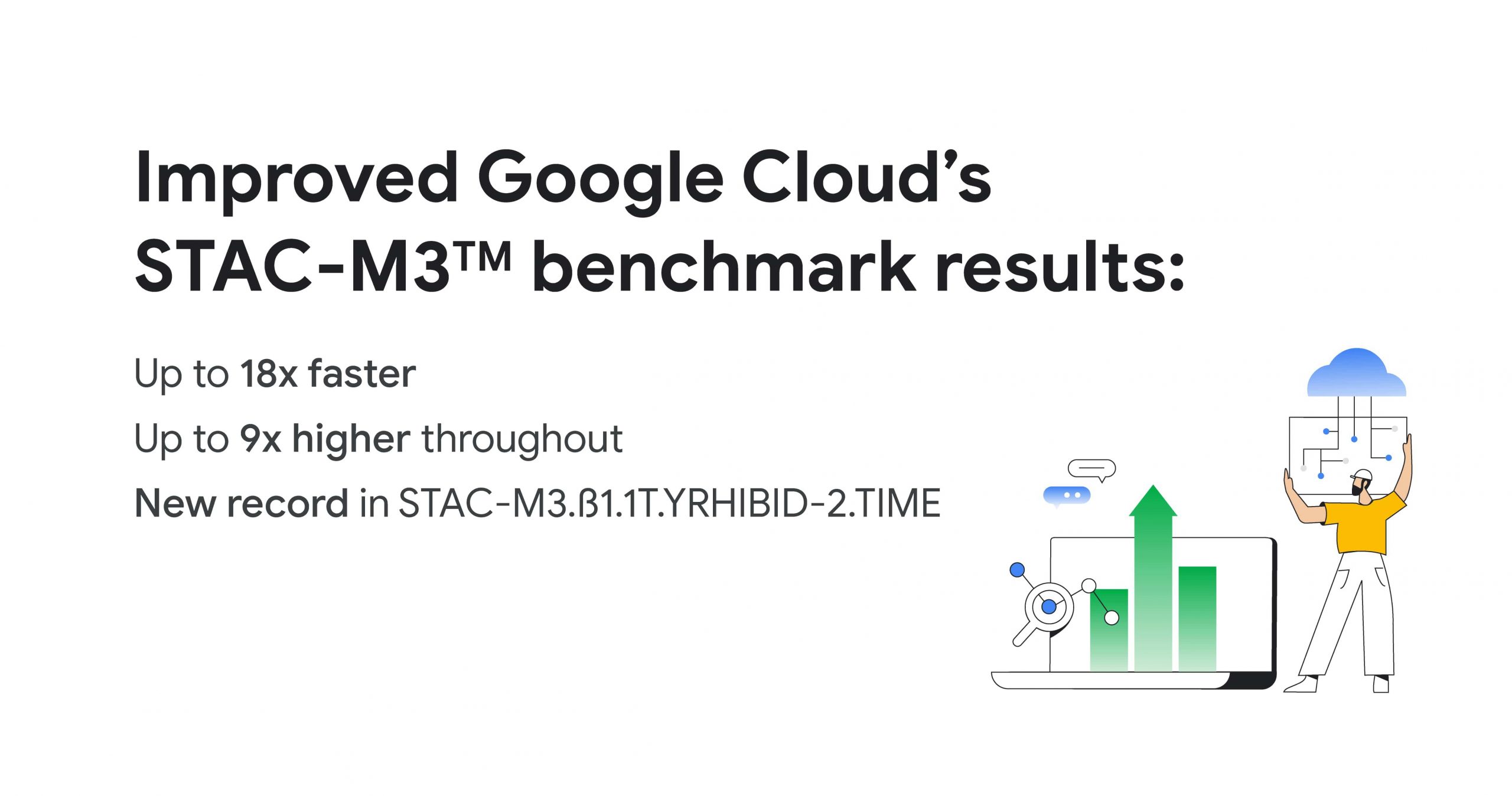
Following up on our previous STAC-M3 benchmark audit (SUT ID KDB181001), a redesigned Google Cloud architecture leveraged the most recent version of kdb+ 4.0, the time-series database from KX, and achieved significant improvements: 35 out of 41 benchmarks ran faster in the new cluster – by up to 18x faster than Google Cloud’s prior results. Key highlights include the following:
From our partners:
- Compared to the previous STAC-M3 Antuco suite results on Google Cloud:
- Was faster in 13 of 17 mean response-time benchmarks
- Was 18x faster – a 94% reduction in run time – in the version of Year-High Bid that allows caching (STAC-M3.ß1.1T.YRHIBID-2.TIME), which also set an overall record for all published results
- Had 9x higher throughput in Year-High Bid (STAC-M3.ß1.1T.YRHIBID.MBPS)
- Compared to the previous STAC-M3 Kanaga suite results on Google Cloud:
- Was faster in 22 of 24 mean response-time benchmarks
- Was over 10x faster in all four Market Snapshot workloads (STAC-M3.ß1.10T.YR[2,3,4,5]-MKTSNAP.TIME)
- Had 5x the throughput in Year-High Bid involving 2 years of data (STAC-M3.ß1.1T.2YRHIBID.MBPS)

“The STAC-M3 standard was designed by financial firms to reveal the performance of tick analytics stacks. Generational improvements like those exhibited by Google Cloud’s most recent STAC-M3 audit, are important data points for firms evaluating new architectures for performance and scale,” said Peter Nabicht, President of STAC.
These performance results may translate to real-world advantages that may be difficult for investment firms to achieve in static and costly on-premises environments: immediate answers in high data velocity markets, more thoroughly explored research theories by adding data or new quantitative approaches, and reduced costs by releasing cloud resources more quickly.
STAC-M3: High-speed tick analytics
Designing for record-breaking results
In our STAC-M3 audit, the stack under test (SUT) was designed to take advantage of horizontal scalability in the cloud by sharding data across independent compute nodes. The cluster of 12 Google Compute Engine N2 instances was powered by Intel Cascade Lake, with each node using 32 vCPUs, 160GiB of memory, and 9TiB of local NVMe SSDs. The full STAC-M3 Antuco and Kanaga data set was split across the cluster and kdb+ scripts distributed queries between nodes.
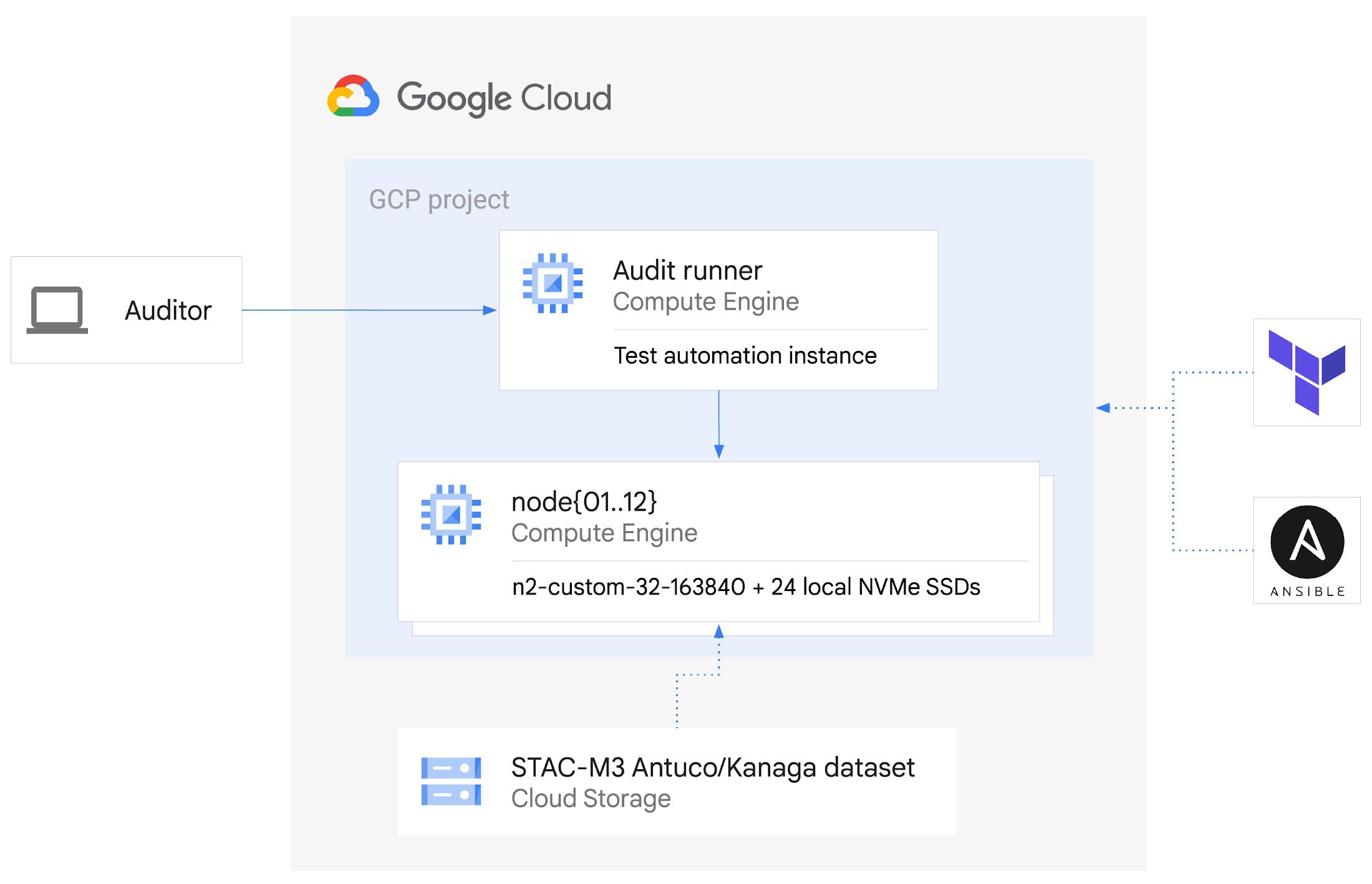

This configuration was the sweet spot for this particular workload, but this architecture does not need to be limited to 12 nodes for other workloads – the data sharding algorithm could scale to any number of nodes as required by workload demands. Since scaling out the cluster in this manner increases the total pool of available storage, this architecture can continue scaling out to petabytes of storage across hundreds of nodes.
The ability to spawn large clusters with hundreds of thousands of processors on demand at low cost, and to delete the resources when jobs complete, not only changes the economics of running computations on large financial data sets, it also opens up opportunities to explore solutions to new types of problems that were previously overlooked due to the constraints of fixed hardware on-premises. You can check the pricing of this VM configuration using the Google Cloud Pricing Calculator. The costs can be reduced even further by using preemptible VMs.
While the new cluster used a similar number of nodes, cores, and total memory as the previously-audited cluster, the redesigned architecture allowed us to harness the low latency and high throughput of Local NVMe SSDs.
Resources on demand
The cluster was created on demand using Terraform and Ansible during testing and auditing. The use of infrastructure as code (IaC) techniques ensured that the cluster, fully loaded with the STAC-M3 data set, could be created when needed and then removed when benchmarking was complete. It also meant that the cluster configuration was enforced by code on each deployment, eliminating configuration variance and drift. The full IaC definition to create the cluster can be retrieved from the report in the STAC Vault.
Each time the cluster was created, data was streamed to Local SSDs from Google Cloud Storage, our reliable and secure object storage, at up to the line rate of 32Gbps per node. The entire 57TiB STAC-M3 Antuco and Kanaga data was replicated from Cloud Storage to local storage in approximately 20 minutes.
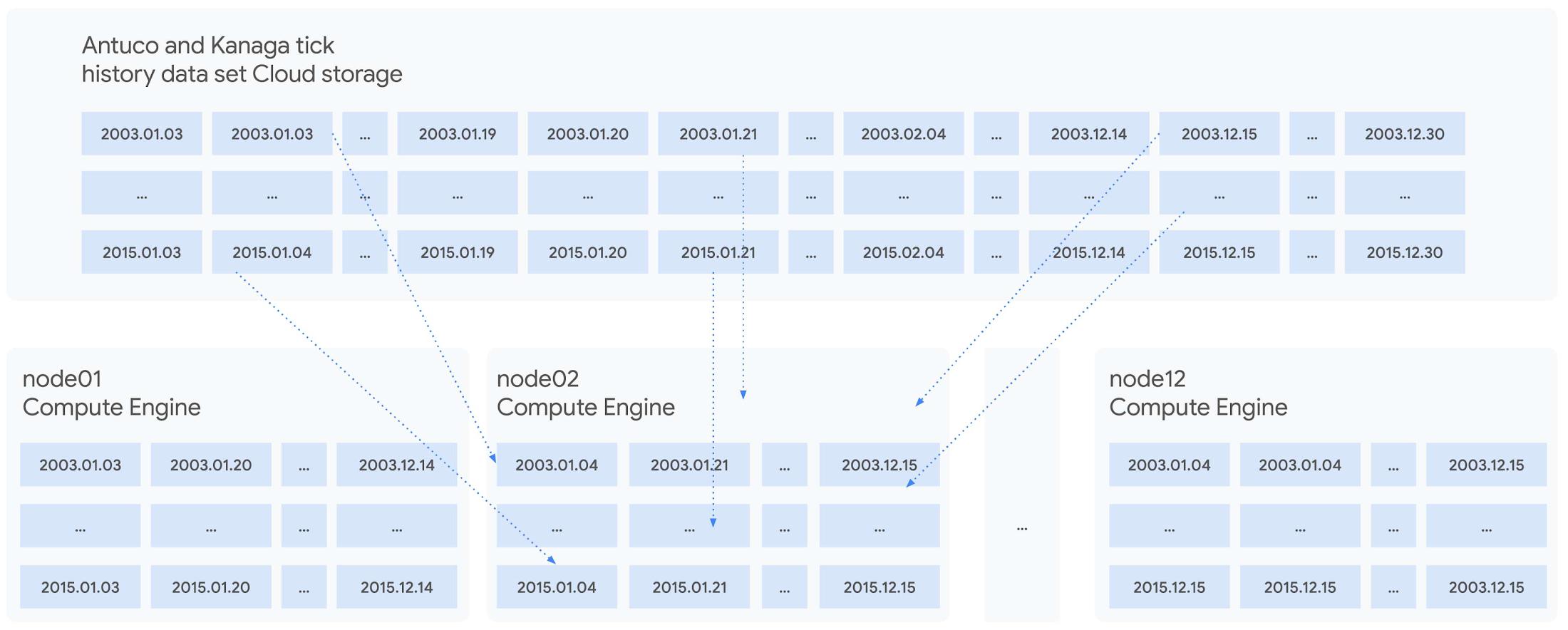

Since each node was independent and responsible for its own shard of data, doubling the cluster size would cut the synchronization time in half, or copy twice as much data in the same amount of time. Using higher bandwidth options of up to 100Gbps would triple the possible throughput for a relatively small incremental cost, trading an approximately 11%-23% price increase at current list prices for a 200% data synchronization performance increase. Taking advantage of fast networking to cache sharded data in parallel to a large cluster makes storing bulk data in Cloud Storage viable for even the largest workloads.
For quants working on vast data sets in sprawling compute clusters, the ability to fully describe infrastructure as declarative code, create elastic resources on demand, cache data quickly from cheap bulk storage, and turn resources off when computations complete is a dramatic change compared to waiting months to grow on-premises clusters – and a compelling reason to use cloud infrastructure.
To see how we designed and optimized the cluster for API-driven cloud resources, read our new whitepaper.
STAC-A2™: Calculating derivatives risk
In 2018, we showed that cloud instances can outperform bare metal when analyzing large tick history data sets in the demanding suite of STAC-M3 benchmarks. Last year, Google Cloud’s partner Appsbroker showed that the same was true for calculating derivatives risk in STAC-A2 on Google Cloud. You can read about how Appsbroker built its record-breaking STAC-A2 compute cluster on Google Cloud in its blog post, or access the STAC Report directly. Here are the highlights:
- Compared to all other publicly reported solutions, this solution, based on a cluster of 10 virtual machines, had:
- The highest throughput (STAC-A2.β2.HPORTFOLIO.SPEED)
- The fastest cold time in the large problem size (STAC-A2.β2.GREEKS.10-100k-1260.TIME.COLD)
- Compared to a solution involving an 8-node, on-premises cluster (SUT ID INTC181012), this 10-node, cloud-based solution:
- Had 5 times the maximum paths (STAC-A2.β2.GREEKS.MAX_PATHS)
- Had 10% greater throughput (STAC-A2.β2.HPORTFOLIO.SPEED)
- Was 18% faster in cold runs of the large problem size (STAC-A2.β2.GREEKS.10-100k-1260.TIME)
- Was 9% faster in cold runs of the baseline problem size (STAC-A2.β2.GREEKS.TIME.COLD)
Finding market advantages with Google Cloud
Across the investment management industry, every firm is seeking many of the same competitive advantages. However, finding unique opportunities and managing larger and larger data sets is becoming a major strain. Cloud is fundamentally changing how quants tackle the problem while empowering them to manage risk and generate higher returns.
Building on-premises computing clusters with tens or hundreds of thousands of cores and petabytes of storage requires huge up-front investments and lead time measured in months or years. Google Cloud makes the same scale available to its customers, provisioned on demand and paid per use. More importantly, the elasticity of cloud resources enables agility that is simply not available in a fixed data center cluster – the agility to explore, experiment, iterate, and respond to markets faster than before.
Scaling out to tens of thousands of cores in minutes and then removing the resources immediately not only changes the speed at which questions can be answered; it encourages different and more frequent questions, asked simultaneously on many independent clusters, free from the constraints of fixed on-premises hardware.
It is this flexibility and power that enables financial services firms to leverage larger data sets and get results, backtest, research, and analyze large amounts of data, faster and whenever they need it.
Download our whitepaper to learn more about our latest STAC-M3 tick history analytics benchmark results and how to optimize cloud infrastructure for high-speed market data analysis.
By: Paul Mibus (Technical Solutions Consultant, Google Cloud)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







