
Geospatial data has many uses outside of traditional mapping, such as site selection and land intelligence. Accordingly, many businesses are finding ways to incorporate geospatial data into their data warehouses and analytics. Google Earth Engine and BigQuery are both tools on Google Cloud Platform that allow you to interpret, analyze, and visualize geospatial data. For example, you can combine crop classifications based on satellite data from Google Earth Engine with weather data in BigQuery to predict crop yield.
Although there is crossover in the functionality of these two products, they are different and are designed for different use cases, as summarized in the following table. In this blog, we demonstrate how geospatial data can be moved from Google Earth Engine to BigQuery, and the changes in data format that are required.
From our partners:
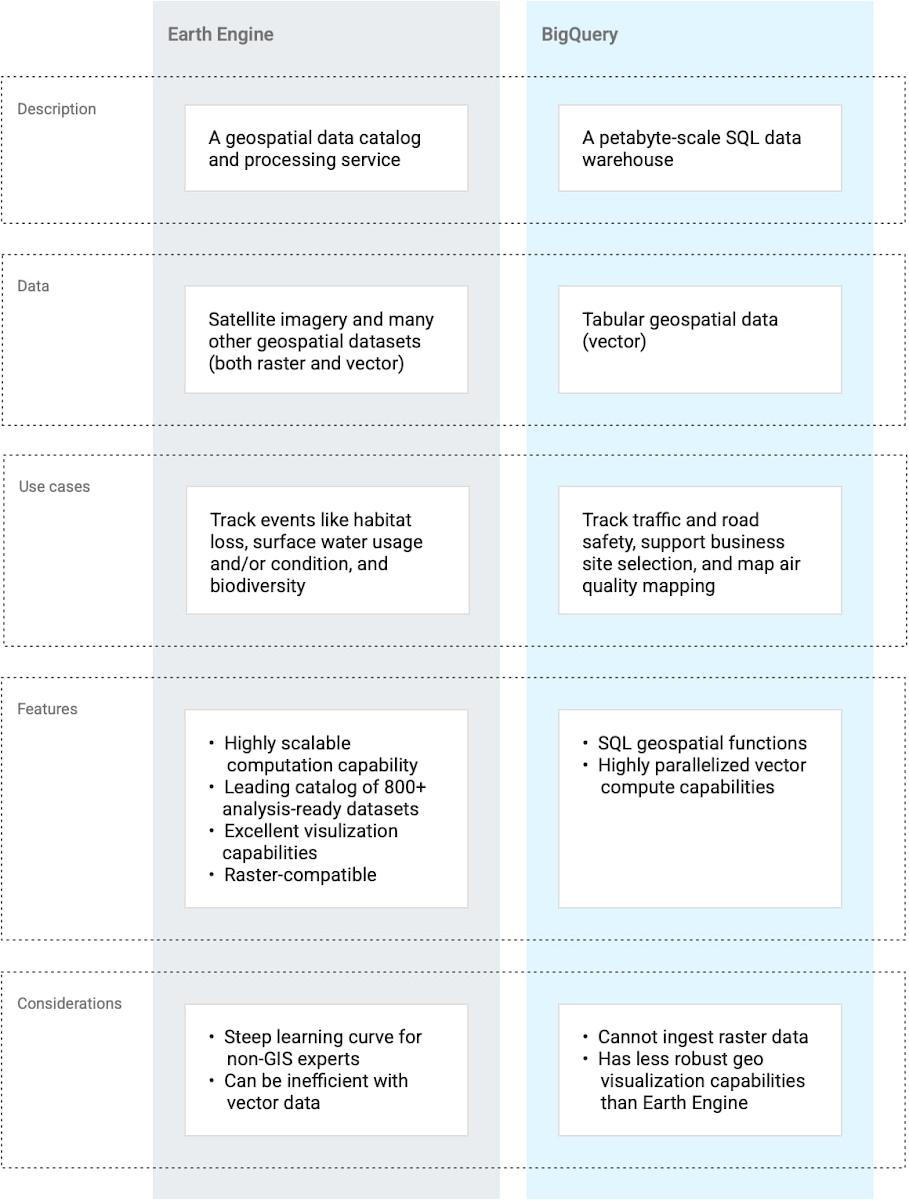

Earth Engine’s robust visualization capabilities and data catalog make it an important part of the discovery/development stage of a geospatial solution, and more. BigQuery’s status as a complete data warehouse makes it great for solutions involving non-geospatial datasets. For many use cases, you’ll want to use both tools. This raises a question: how can you move data from Earth Engine to BigQuery?
Using Geobeam to move data from Earth Engine to BigQuery
Geospatial data comes in many forms, file formats, and projections, so moving data between tools is not simple. However, a relatively new open source library named Geobeam can help bridge the gap between Earth Engine and BigQuery.
Geobeam is a Python library that extends Apache Beam and enables you to ingest and analyze massive amounts of geospatial data in parallel using Dataflow. Geobeam provides a set of FileBasedSource classes and Apache Beam transforms that make it easy to read, process, and write geospatial data.
In this blog, we will walk through a tutorial that uses Geobeam to ingest a raster dataset in GeoTIFF format from Earth Engine into BigQuery as a vector data table.
Handling geospatial data
Before launching into the code, it’s important to understand how each product we use handles geospatial data. Earth Engine has a huge data catalog of maps and assets that are available to its users. You can also import and export CSV files and Shapefiles (for vector data), or GeoTIFFs and TFrecords (for raster data) in Earth Engine. BigQuery has a smaller catalog of publicly available geospatial datasets. It accepts data in CSV format, in WKT format, or in properly formatted GeoJSON format.
Raster files (that is, images) are a unique kind of file that are not supported natively in BigQuery. Therefore, they must be transformed before they are ingested into BigQuery. You can use Geobeam for this transformation, as summarized in the following diagram:
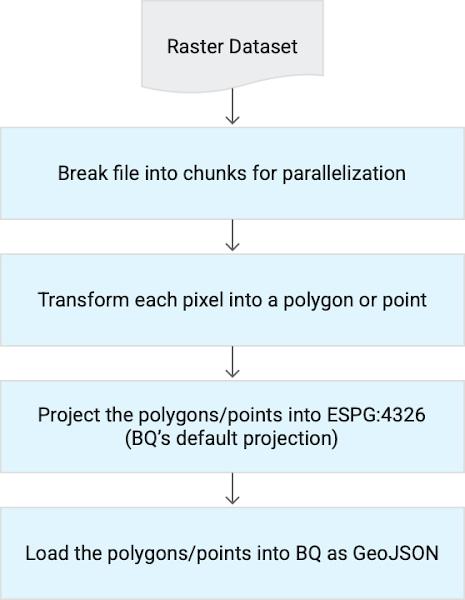

Currently, Geobeam has only been tested using BigQuery as a destination, but it could be extended to other sinks, such as MySQL. Geobeam primarily uses rasterio, shapely, and GDAL for Python to make the necessary transformations. You can build your own transformations in Apache Beam by forking the Geobeam GitHub repository.
Tutorial
If you’d like to follow along, you need to have an Earth Engine account (sign up for free), and a Google Cloud account (sign up for free trial). All the code for this tutorial can be found in the associated GitHub repository. We assume the audience for this blog has some familiarity with Google Cloud Platform.
The tutorial takes the following steps:
- Visualize the USDA Cropland data in Earth Engine.
- Export the dataset as a GeoTIFF.
- Run a Dataflow job, which uses Geobeam to do the following:
- Convert the raster GeoTIFF into vector format.
- Ingest the data into BigQuery.
- Confirm that the data was correctly loaded into BigQuery.
Visualizing the dataset
The dataset we used is the USDA Cropland Data Layer. This is an image collection in the Earth Engine catalog that contains crop type data for the continental United States. The following image shows what the full dataset looks like in the Earth Engine console.
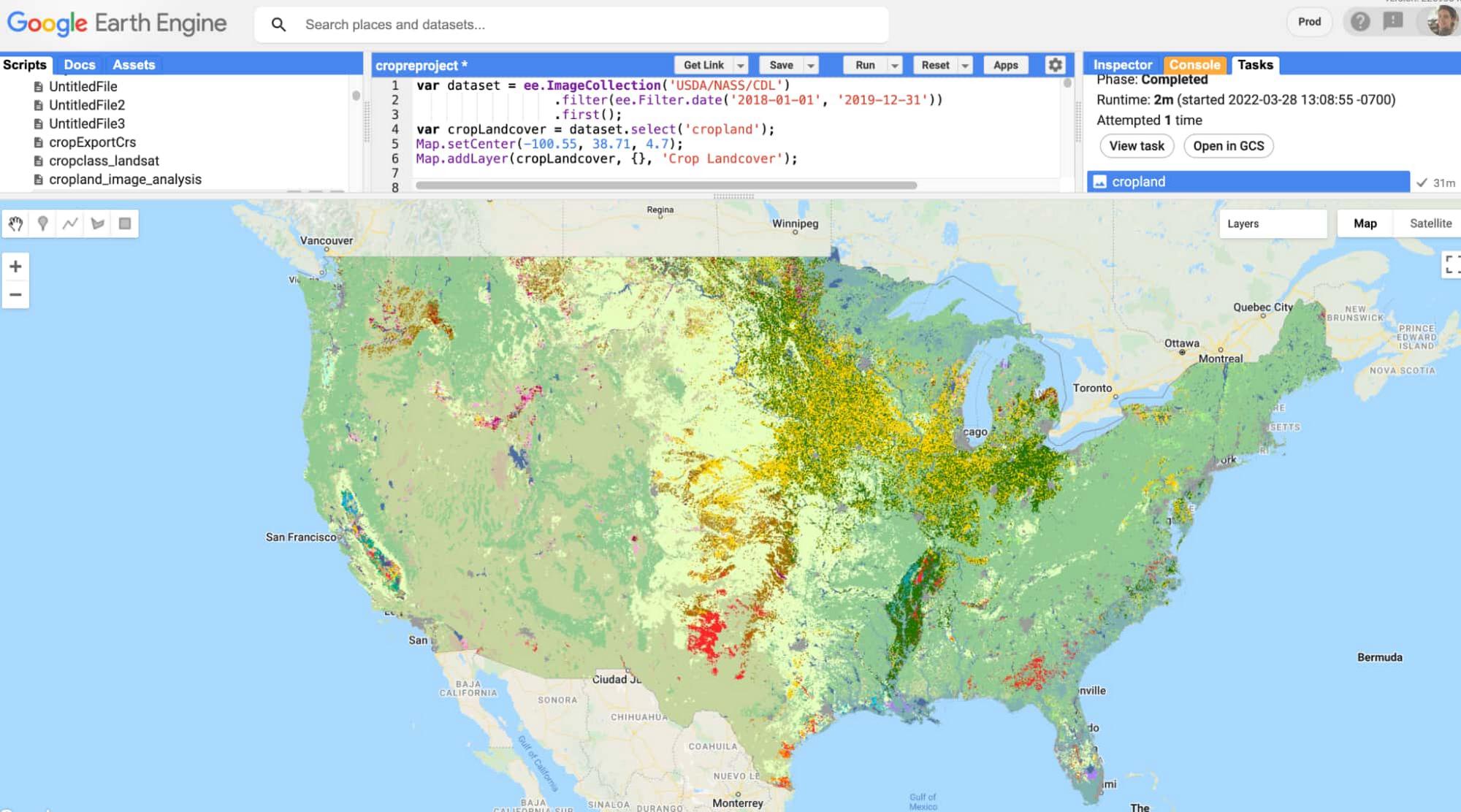

Exporting data from Earth Engine
To export data from Earth Engine, you can use the Earth Engine console, which utilizes JavaScript. For this example, we submitted commands to Earth Engine using the Earth Engine Python API (when we built this tutorial, we used a Jupyter notebook in the Vertex AI Workbench environment).
We exported the dataset to a Cloud Storage bucket by using the following script:
# define a regioncolorado = ee.Geometry.Rectangle([-104, 37, -102, 38]);# Select the first (and only) image from the Cropland image collection for the year 2019, and the cropland band, which gives us the crop type. Currently, Geobeam will only ingest a single band from a GeoTIFF at time.image = ee.ImageCollection('USDA/NASS/CDL').filter(ee.Filter.date('2019-01-01', '2019-01-02')).first();cropland = image.select('cultivated');task_config = { 'description': 'cropland','crs': 'EPSG:4326', # specify this projection to ensure BigQuery can ingest it properly'scale': 30, # also necessary to specify scale when reprojecting (30m is the original dataset scale)'bucket': BUCKET_NAME,'fileNamePrefix': 'croplandExport_co1','region': colorado,'maxPixels': 1e12 #increase max pixels limit for exports}task = ee.batch.Export.image.toCloudStorage(cropland, **task_config)task.start()
This dataset is updated annually, so filtering to a single day provides the crop types for that whole year. The code uses the first() method to select the first image from the collection, though in this case, there is only one image for that date range. By using the first() method, Earth Engine treats the output as type Image and not as type ImageCollection, which is what we wanted for export.
In the export statement, we reprojected the image as EPSG:4326, which is the projection that BigQuery uses for its geospatial data. Geobeam is designed to reproject input data into EPSG:4326, and you can provide the original projection of the input data by using the in_epsg parameter. The cropland dataset uses an atypical projection (Albers Conical Equal Area Map) by default, so we specified a more typical projection on export, rather than leaving it to Geobeam to reproject the data. It’s important to specify a scale value and a crs (Coordinate Reference System) value when you reproject in Earth Engine.
Note that for the sake of example, we exported a small region (a portion of Colorado) in order to reduce the export and ingest time. If we had exported the entire United States, it would have taken around 30 minutes to export and around 30 minutes to run the Geobeam ingestion job.
Exporting large regions of high-resolution raster data from Google Earth Engine into BigQuery is not a recommended or efficient practice in general, but is possible to do if necessary. In this tutorial, we exported a single band as a 2.4 MB GeoTIFF file that translated to 2 million rows in BigQuery. Larger, more complex datasets will take prohibitively long (or exceed memory limits) to export, plus BigQuery isn’t the right tool for visualizing satellite imagery. Instead, we recommend that you do your analysis of image collections in Earth Engine. When you have a relevant subset of data, then consider moving that data into BigQuery.
Using Geobeam to ingest the data into BigQuery
After exporting the raster GeoTIFF to a Cloud Storage bucket, we were ready to run a Dataflow job to ingest the GeoTIFF into BigQuery as vector (tabular) data. The pipeline code, which can be found in the Geobeam Github examples, uses the Geobeam GeotiffSource class and the format_record method to transform the input file into a format that can be ingested by BigQuery.
Using Apache Beam in Dataflow, you can write practically any kind of data transformation you can think of. In this case, all we did was directly read in the band values (crop type) as integers and read the pixels as points.
We ran the job in Dataflow by using the following command:
python -m geobeam.examples.crop_geotiff \--runner DataflowRunner \--worker_harness_container_image gcr.io/dataflow-geobeam/example \--experiment use_runner_v2 \--project ${PROJECT_ID} \--temp_location gs://${GEOBEAM_BUCKET}/ \--region ${BQ_DATASET_REGION} \--gcs_url gs://${IMAGES_BUCKET}/croplandExport.tif \--dataset ${BQ_DATASET} \--table ${BQ_TABLE} \--band_column croptype \--max_num_workers 4 \--machine_type c2-standard-4 \--merge_blocks 10 \--centroid_only true
By setting the centroid_only parameter to true, we had Geobeam compute the center of each pixel to produce a point, as opposed to producing a polygon that encompassed the entire pixel (or pixels if they have the same band value).
The merge_blocks parameter affects how Geobeam merges pixels during read. You can use this parameter to tune the ingestion time—generally, increasing the merge_blocks value increases the ingestion time.
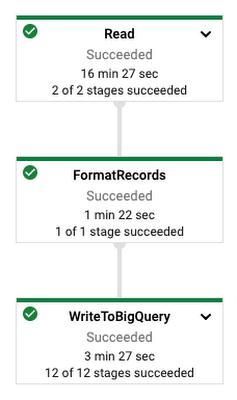
You can monitor the Dataflow job in the Cloud Console. For this example, the job took about 11 minutes and looked like the following:

View the table in BigQuery
When the job is complete, the resulting table is found in BigQuery via the Explorer panel, by navigating to the project > dataset > table that was ingested. The preview of the table showed the following:
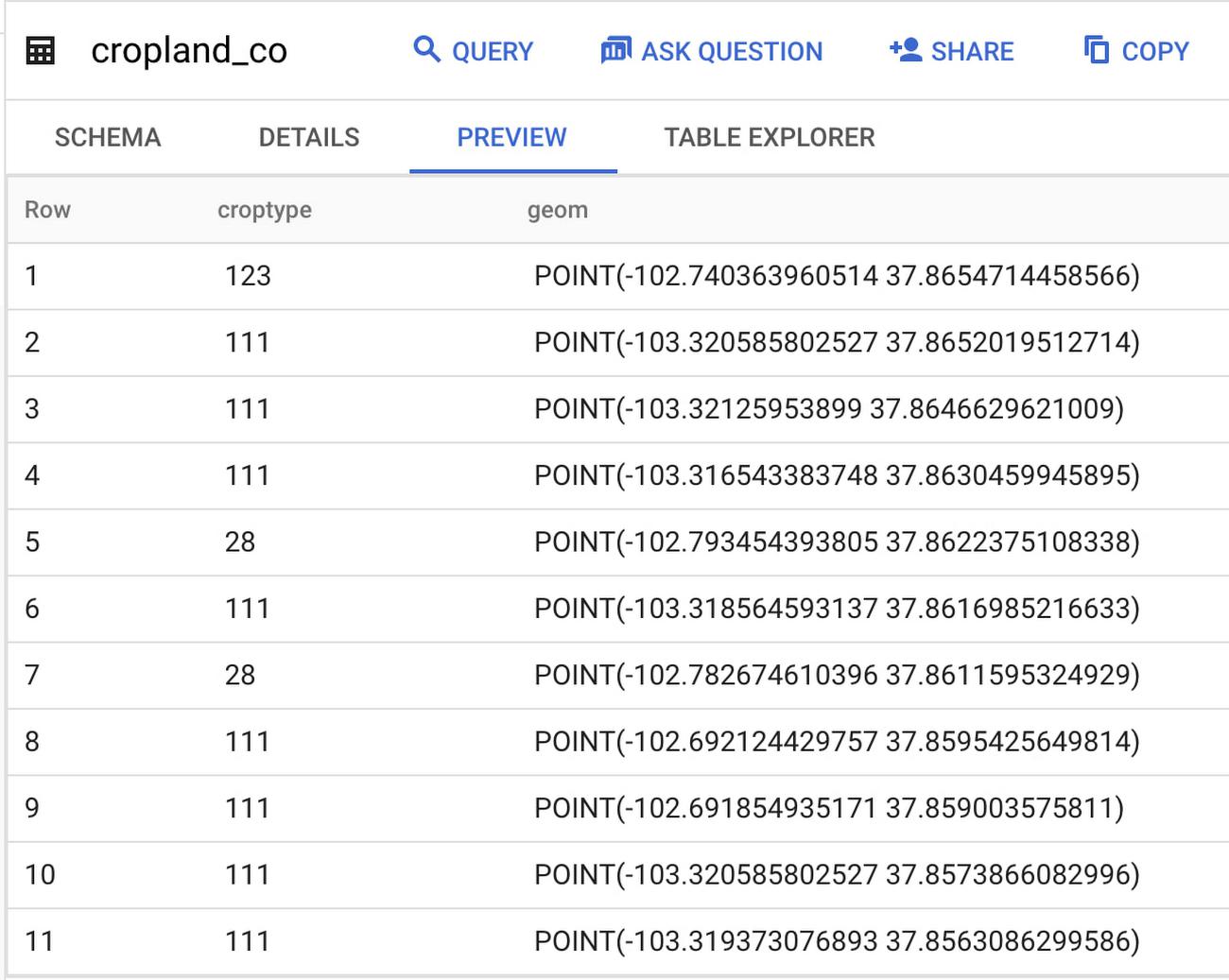

As you can see, the data that were once pixels in Earth Engine are now points in BigQuery. The data has been transformed from raster to vector. You can visualize the points on a map using BigQuery Geo Viz tool.
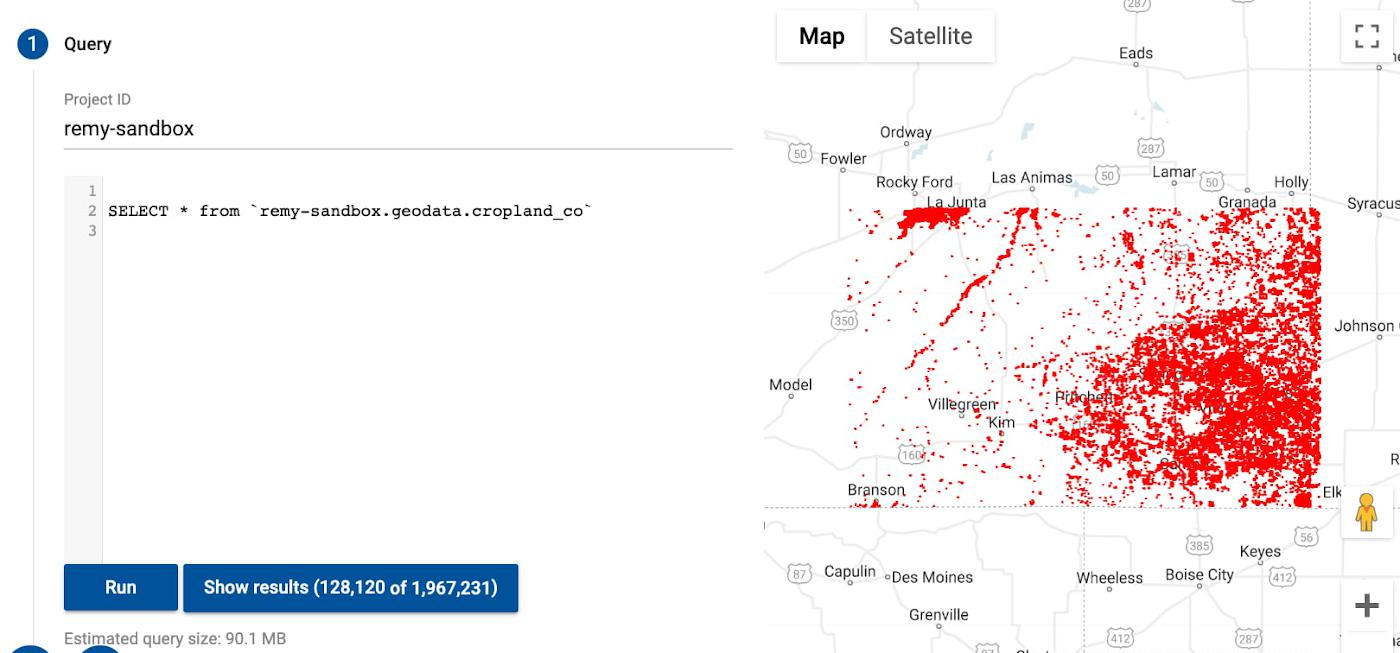

Analyzing the Data
In this blog, you have seen raster data from Earth Engine transformed and ingested into BigQuery as vector data using Geobeam. This does not mean you can, or should, use Geobeam to reproduce entire satellite imagery datasets in BigQuery. BigQuery is not built to process images, so you will quickly find yourself frustrated if you try to ingest and analyze the entire Sentinel-2 dataset in BigQuery. A better practice is to identify particular bands, properties, and regions that are of interest to you in a geospatial dataset, and use Geobeam to bring those to BigQuery, where they can be easily combined with other tabular data, and where you can use them to build models or do other analyses.
Now that we have ingested the crop classification data in BigQuery, we could spatially join it to another dataset that has weather information, and use those as features in a BQML predictive model. For example, we could look at the average distance between soy fields, and a company’s stores that sell soy-based products.
Although it can be difficult to understand initially, geospatial data opens up an entirely new dimension in the data world. Earth Engine, BigQuery, and Geobeam can help you put your analyses on the map.
Acknowledgments: Thanks to Travis Webb, Rajesh Thallam, Donna Schut and Mike Pope for their help with this post
By: Remy Welch (Customer Engineer) and Kannappan Sirchabesan (Data Engineer)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







