
Indonesia’s largest hyperlocal company, Gojek has evolved from a motorcycle ride-hailing service into an on-demand mobile platform, providing a range of services that include transportation, logistics, food delivery, and payments. A total of 2 million driver-partners collectively cover an average distance of 16.5 million kilometers each day, making Gojek Indonesia’s de-facto transportation partner.
To continue supporting this growth, Gojek runs hundreds of microservices that communicate across multiple data centers. Applications are based on an event-driven architecture and produce billions of events every day. To empower data-driven decision-making, Gojek uses these events across products and services for analytics, machine learning, and more.
From our partners:
Data warehouse ingestion challenges
To make sense of large amounts of data — and to better understand customers for the purpose of app development, customer support, growth, and marketing purposes — data must first be ingested into a data warehouse. Gojek uses BigQuery as its primary data warehouse. But ingesting events at Gojek’s scale, with rapid changes, poses the following challenges:
- With multiple products and microservices offered, Gojek releases new Kafka topics almost every day and they need to be ingested for analytical purposes. This can quickly result in significant operational overhead for the data engineering team that is deploying new jobs to load data into BigQuery and Cloud Storage.
- Frequent schema changes in Kafka topics require consumers of those topics to load the new schema to avoid data loss and capture more recent changes.
- Data volumes can vary and grow exponentially as people start building new products and logging new activities on top of a new topic. Each topic can also have a different load during peak business hours. Customers need to handle the rising volume of data to quickly scale per their business needs.
Firehose and Google Cloud to the rescue
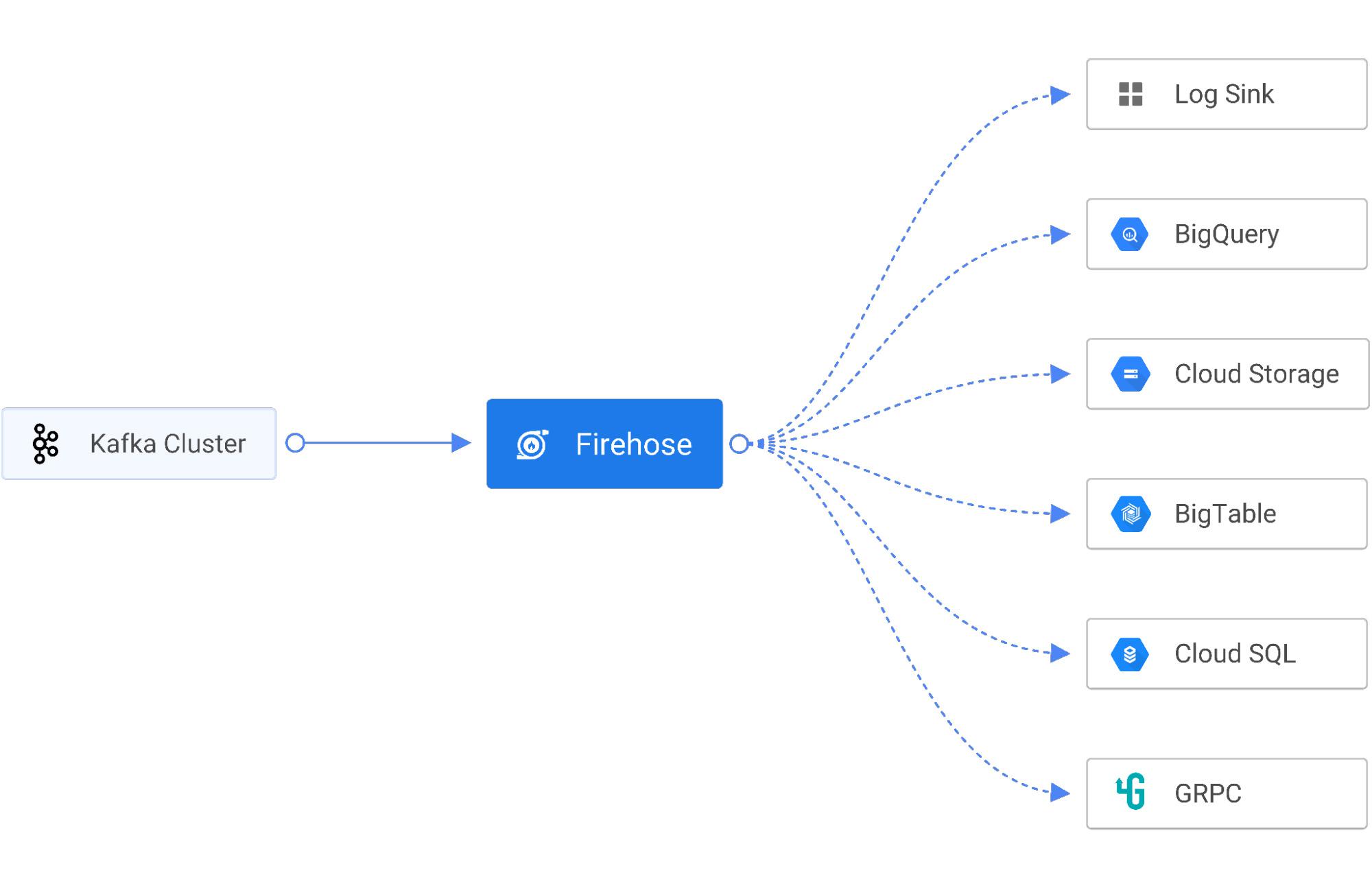
To solve these challenges, Gojek uses Firehose, a cloud-native service to deliver real-time streaming data to destinations like service endpoints, managed databases, data lakes, and data warehouses like Cloud Storage and BigQuery. Firehose is part of the Open Data Ops Foundation (ODPF), and is fully open source. Gojek is one of the major contributors to ODPF.
Here are Firehose’s key features:
- Sinks – Firehose supports sinking stream data to the log console, HTTP, GRPC, PostgresDB (JDBC), InfluxDB, Elastic Search, Redis, Prometheus, MongoDB, GCS, and BigQuery.
- Extensibility – Firehose allows users to add a custom sink with a clearly defined interface, or choose from existing sinks.
- Scale – Firehose scales in an instant, both vertically and horizontally, for a high-performance streaming sink with zero data drops.
- Runtime – Firehose can run inside containers or VMs in a fully-managed runtime environment like Kubernetes.
- Metrics – Firehose always lets you know what’s going on with your deployment, with built-in monitoring of throughput, response times, errors, and more.
Key advantages
Using Firehose for ingesting data in BigQuery and Cloud Storage has multiple advantages.
Reliability
Firehose is battle-tested for large-scale data ingestion. At Gojek, Firehose streams 600 Kafka topics in BigQuery and 700 Kafka topics in Cloud Storage. On average, 6 billion events are ingested daily in BigQuery, resulting in more than 10 terabytes of daily data ingestion.
Streaming ingestion
A single Kafka topic can produce up to billions of records in a day. Depending on the nature of the business, scalability and data freshness are key to ensuring the usability of that data, regardless of the load. Firehose uses BigQuery streaming ingestion to load data in near-real-time. This allows analysts to query data within five minutes of it being produced.
Schema evolution
With multiple products and microservices offered, new Kafka topics are released almost every day, and the schema of Kafka topics constantly evolves as new data is produced. A common challenge is ensuring that as these topics evolve, their schema changes are adjusted in BigQuery tables and Cloud Storage. Firehose tracks schema changes by integrating with Stencil, a cloud-native schema registry, and automatically updates the schema of BigQuery tables without human intervention. This reduces data errors and saves developers hundreds of hours.
Elastic infrastructure
Firehose can be deployed on Kubernetes and runs as a stateless service. This allows Firehose to scale horizontally as data volumes vary.
Organizing data in cloud storage
Firehose GCS Sink provides capabilities to store data based on specific timestamp information, allowing users to customize how their data is partitioned in Cloud Storage.
Supporting a wide range of open source software
Built for flexibility and reliability, Google Cloud products like BigQuery and Cloud Storage are made to support a multi-cloud architecture. Open source software like Firehose is just one of many examples that can help developers and engineers optimize productivity. Taken together, these tools can deliver a seamless data ingestion process, with less maintenance and better automation.
How you can contribute
Development of Firehose happens in the open on GitHub, and we are grateful to the community for contributing bug fixes and improvements. We would love to hear your feedback via GitHub discussions or Slack.
By: Ravi Suhag (VP, Engineering, Gojek)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







