
Application development teams are more agile and are shipping features faster than ever before. In addition to these rapid development cycles and the rise of microservices architectures, the end-to-end ownership of feature development (and performance monitoring) has moved to a shared responsibility model between advanced database administrators and full-stack developers. However, most developers don’t have the years of experience or the time needed to debug complex query performance issues and database administrators are now a scarce resource in most organizations. As a result, there is a dire need for tools for developers and DBAs alike to quickly diagnose performance issues.
Introducing Query Insights for Spanner
We are delighted to announce the launch of Query Insights for Spanner, a set of visualization tools that provide an easy way for developers and database administrators to quickly diagnose query performance issues on Spanner. Using Query Insights, users can now troubleshoot query performance in a self-serve way. We’ve designed Query Insights using familiar design patterns with world-class visualizations to provide an intuitive experience for anyone who is debugging issues with query performance on Spanner. Query Insights is available at no additional cost.
From our partners:
By using out-of-the-box visual dashboards and graphs, developers can visualize aberrant behavior like peaks and troughs in various performance metrics over a time-series and quickly identify problematic queries. Time series data provides significant value to organizations because it enables them to analyze important real-time and historical metrics. Data is valuable only if it’s easy to comprehend;. that’s where being able to view intuitive dashboards becomes a force multiplier for organizations looking to expose their time series data across teams.
Follow a visual journey with pre-built dashboards
With Query Insights, developers can seamlessly move from detection of database performance issues to diagnosis of problematic queries using a single interface. Query Insights will help identify query performance issues easily with pre-built dashboards.
The user could do this by following a simple journey where they can quickly confirm, identify and analyze query performance issues. Let’s walk through an example scenario.
Understand database performance
This journey will start by the user setting up an alert on Google Cloud Monitoring for CPU utilization going above a certain threshold. The alert could be configured in a way that if this threshold is crossed, the user will be notified with an email alert, with a link to the “Monitoring” dashboard.
Once the user receives this alert, they would click on the link in the email, and navigate to the “Monitoring” dashboard. If they observe high CPU Utilization and high read latencies, the possible root cause could be expensive queries. A spike in CPU Utilization could be a strong signal that the system is using more compute than it usually would, due to an inefficient query.
The next step is to identify which query might be the problem, this is where Query Insights comes in. The user can get to this tool by clicking on Query Insights in the left navigation of your Spanner Instance. Here, they can drill down into the CPU usage by query and observe that for a specific database, CPU Utilization (attributed to all queries) is spiking for a particular time window. This confirms that the CPU utilization is due to inefficient queries.
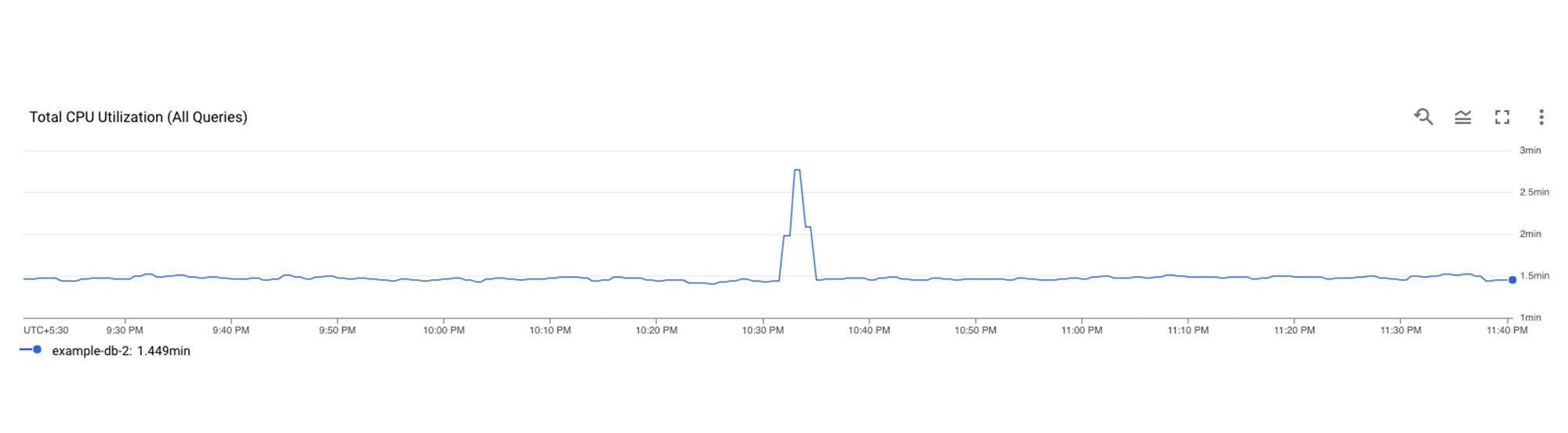
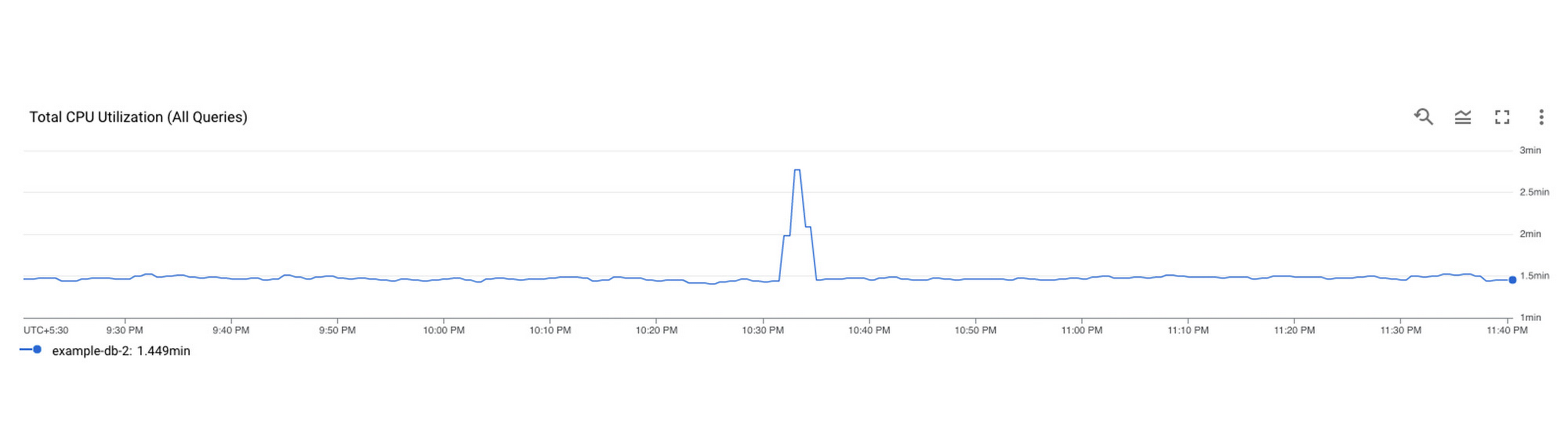
Identifying a problematic query
The user now observes the TopN (Top queries by CPU Utilization) query graph to see the TopN queries by CPU Utilization. From the graph, it is very easy to visualize and identify the top queries which could be causing the spike in CPU Utilization.
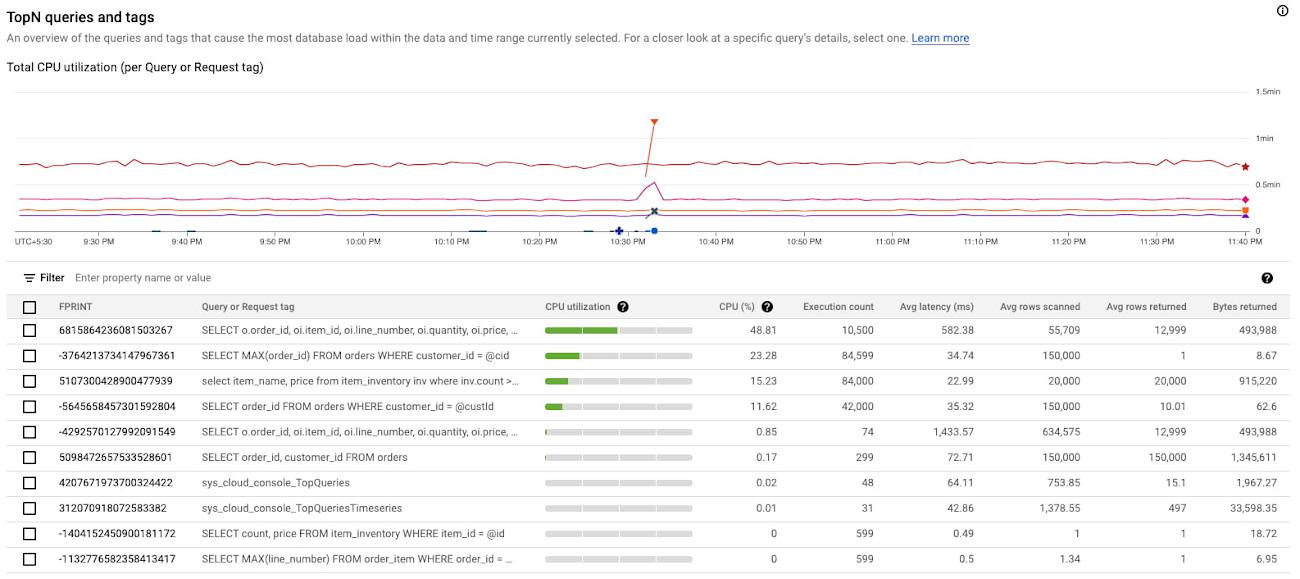
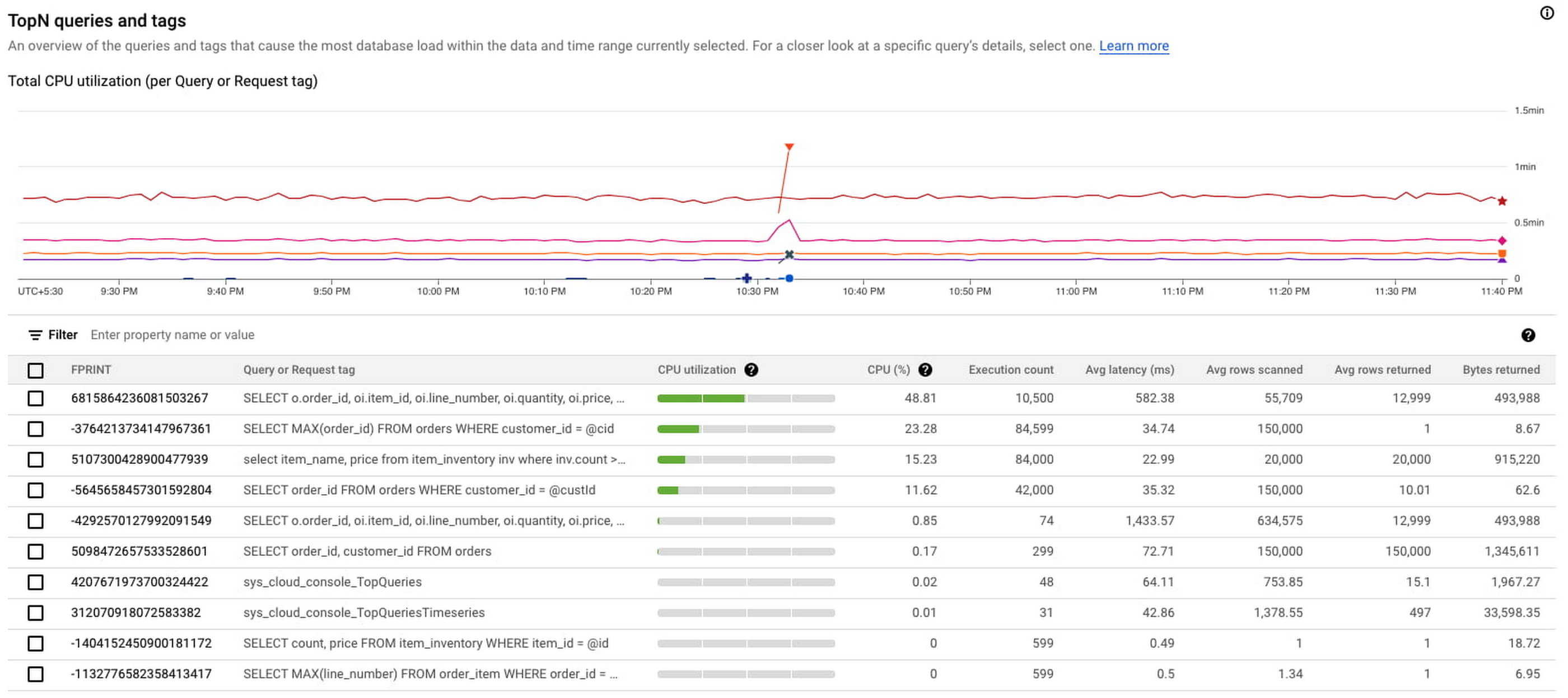
In the above screenshot, we can see that the first query in the table is showing a clear spike at 10:33 PM consuming 48.81% of total CPU. This is a clear indication that this query could be problematic, and the user should investigate further.
Analyzing the query performance
Once they have identified the problematic query, they can now drill down into this query shape to confirm, identify the root cause of the high CPU utilization.
They can do this by clicking on the Fingerprint ID for the specific query from the topN table, and navigating to the Query Details page where they will be able to see a list of metrics (Latency, CPU Utilization, Execution count, Rows Scanned / Rows Returned) over a time series for that specific query.
In this example, we notice that the average number of rows scanned for this specific query are very high (~ 600k rows scanned to return ~ 12k rows), which could point to a poor query design, resulting in an inefficient query. We can also observe that latency is high (1.4s) for this query.
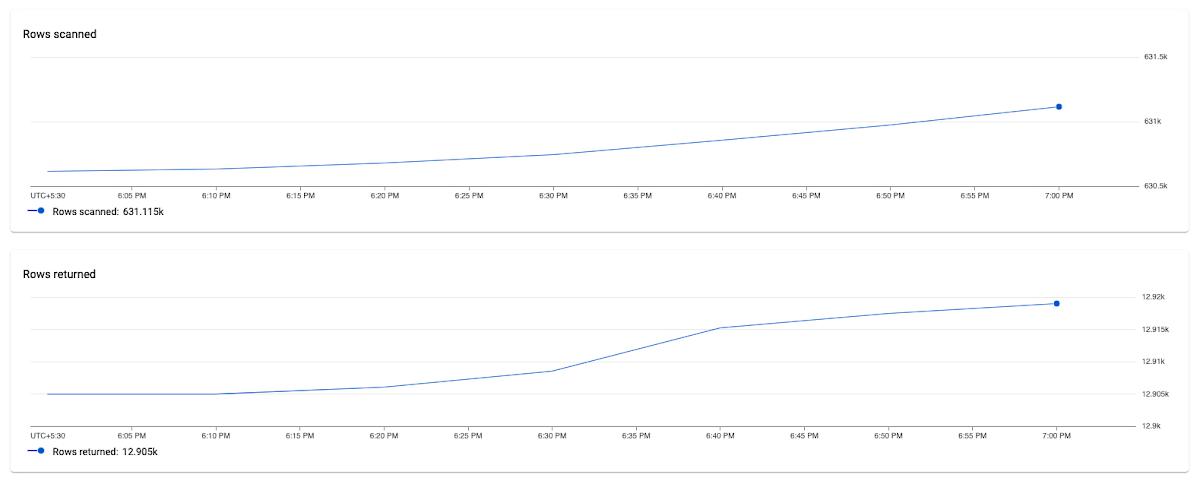
Fixing the issue
To fix the problem in this scenario, the user could optimize this query by specifying a secondary index in the query using a FORCE_INDEX query hint to provide an index directive. This would provide more consistent performance, make the query more efficient, and lower CPU utilization for this query.
In the screenshot below, you can see that after specifying the index in the query, the query performance dramatically increases in terms of CPU, rows scanned (54K vs 630k) and also in terms of query latency (536 ns vs 1.4 s).
Unoptimized Query:
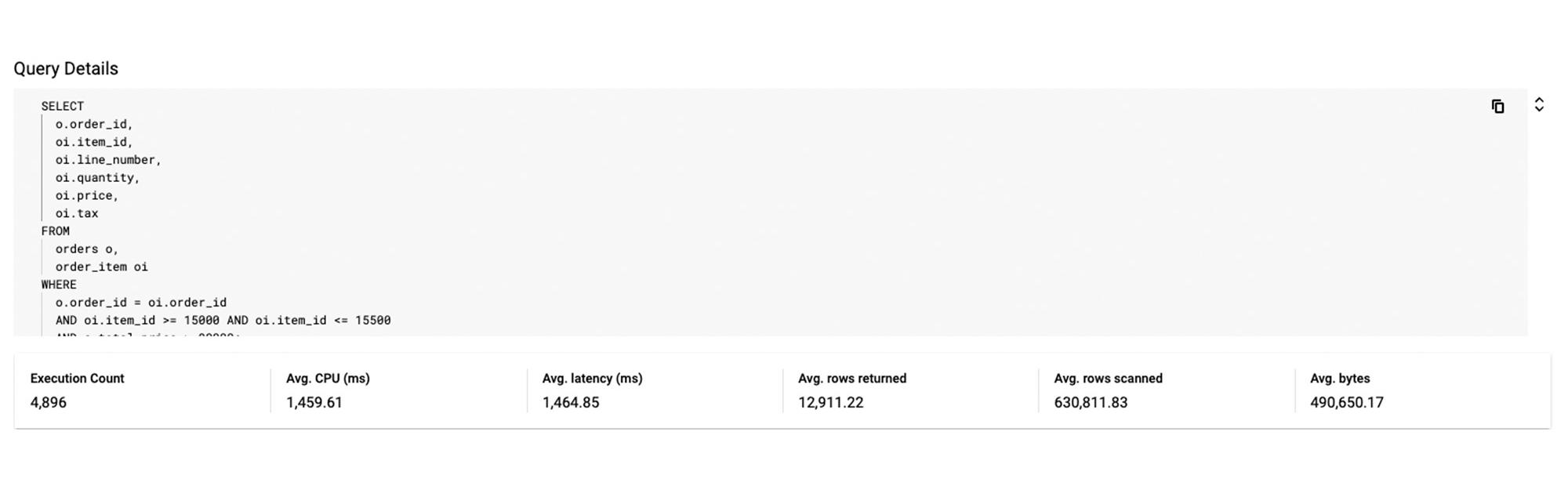
Optimized Query:
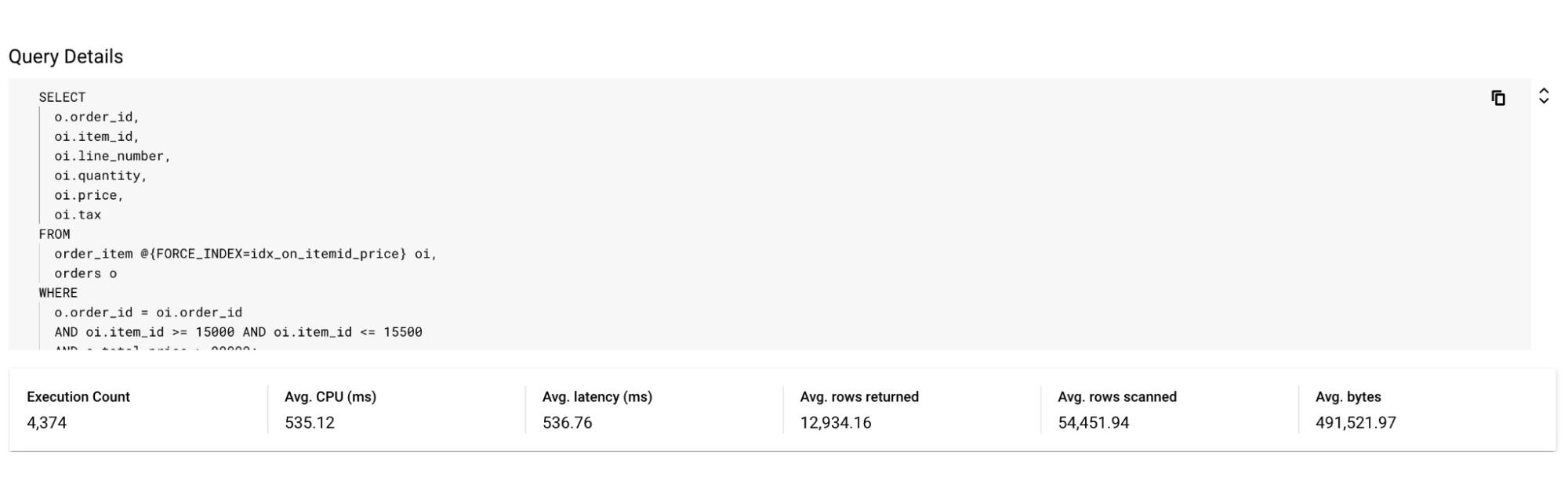
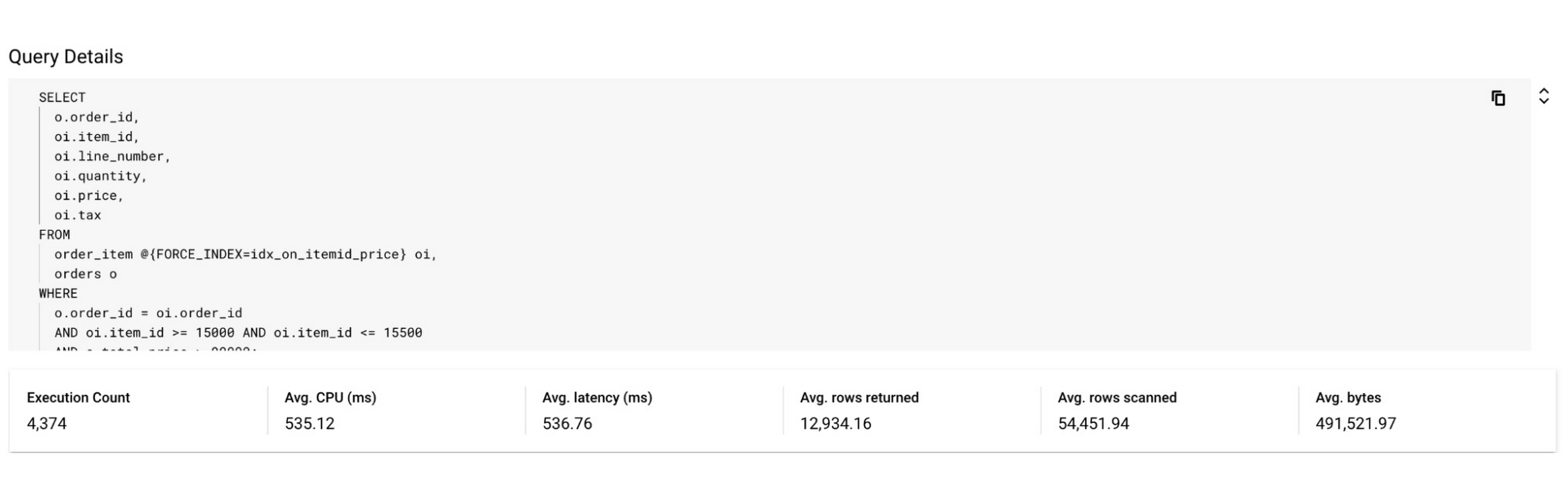
By following this simple visual journey, the user can easily detect, diagnose and debug inefficient queries on Spanner.
Get started with Query Insights today
To learn more about Query Insights, review the documentation here. Query Insights is enabled by default. In the Spanner console, you can click on Query Insights in the left navigation and start visualizing your query performance metrics!
New to Spanner? Get started in minutes with a new database.
By: Mohit Gulati (Product Manager)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







