Sensitive data can show up in unexpected places—for example, customers might inadvertently send you sensitive data in a customer support chat or file upload. And if you’re using data for analytics and machine learning, it’s imperative that sensitive data be handled appropriately to protect users’ privacy. It’s important to take a holistic look at where your data resides and how it’s being used since you could be held liable for that data, and then create processes to ensure it’s being handled appropriately. That’s where Cloud DLP comes in.
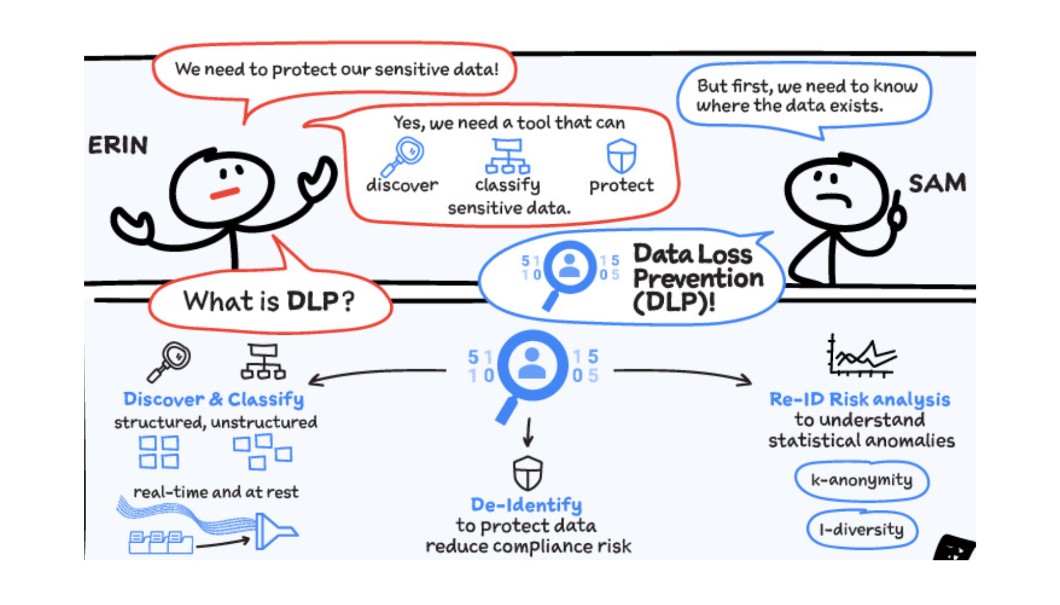
What is Cloud DLP?
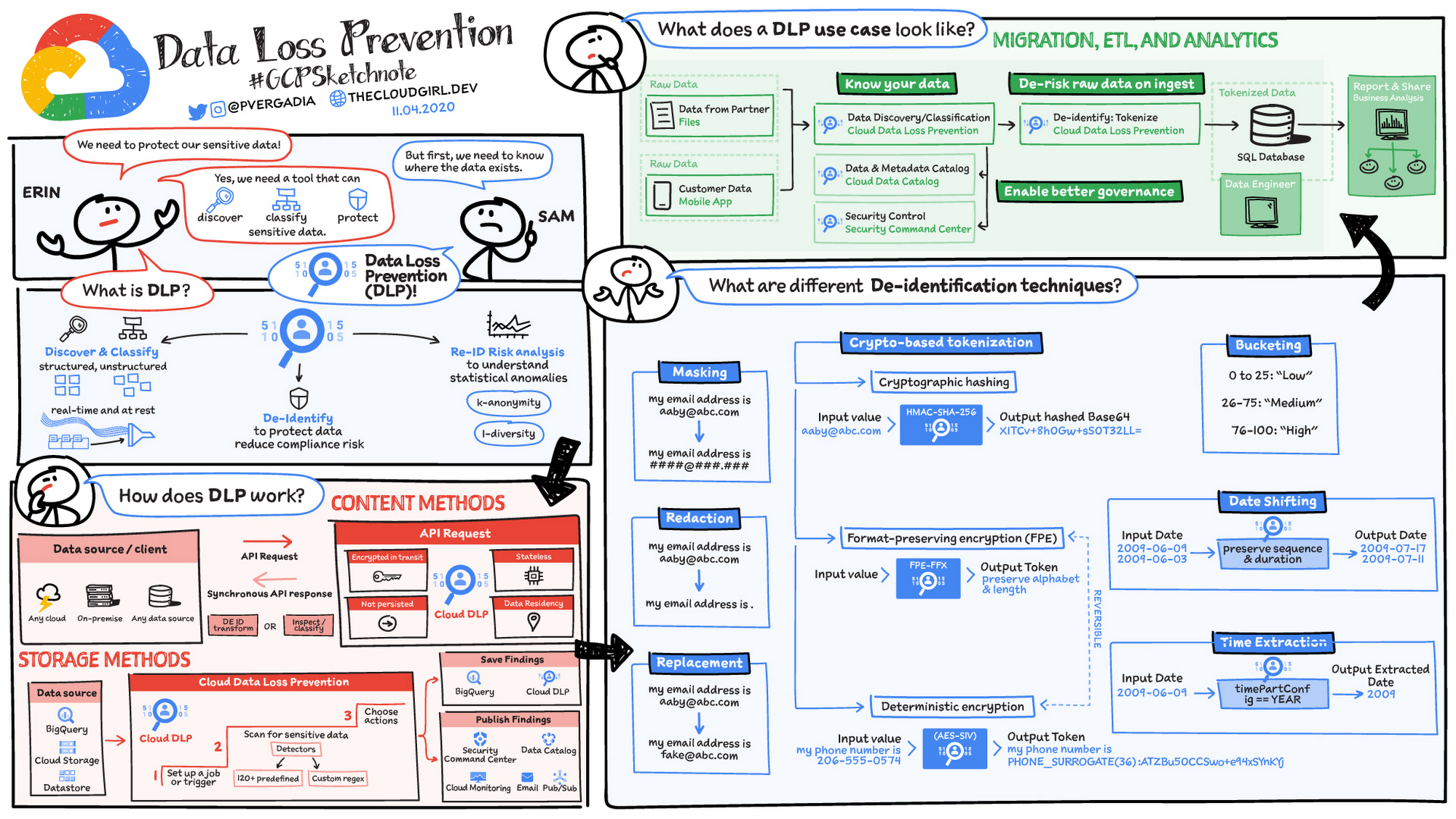
Cloud Data Loss Prevention (Cloud DLP) is a fully managed service designed to discover, classify, and protect your sensitive data, where it resides from databases, text-based content, or even images. It helps provide visibility and classify your sensitive data across your entire organization. Ultimately it can reduce data risk by inspecting and transforming structured and unstructured data using obfuscation and de-identification methods like masking and tokenization. Additionally, Cloud DLP can help you run re-identification analyses to enhance your understanding of data privacy risk. Re-identification risk analysis is the process of analyzing data to find properties that might increase the risk of subjects being identified. Consider, for example, a marketing dataset that includes demographic properties like age, job title, and zip code. On the surface these demographics may not seem identifying, but some combinations of age, job title, and zip code could uniquely map to a small group of individuals or a single person and thus increase the risk of that person being re-identified.
From our partners:
How does it work?
Cloud DLP offers multiple interfaces including an API for incorporating it into existing systems and a console UI for easy, code-free integration. Content API methods provide the ability for customers to inspect and transform data anywhere and allow for real-time interactions such as protecting live traffic. Storage methods for BigQuery, Cloud Storage, and Datastore have both UI and API interfaces for analysis and are good for scanning large amounts of data at rest. Automatic DLP for BigQuery, for example, can automate the discovery and classification of an entire GCP organization and run continuously to give visibility into data risk as new projects, datasets, and tables are created.
Inspection and classification is powered by Google Cloud’s Data Loss Prevention technology, which has detectors for over 150 built-in information types, provides a rich set of customization and detection rules, and supports a variety of formats including structured tables, unstructured text, and image data using OCR.
A variety of de-identification techniques
Cloud DLP offers several de-identification techniques that can help obscure sensitive information while preserving some utility:
- Masking – Masks a string either fully or partially by replacing a given number of characters with a specified fixed character. This technique can, for example, mask everything but the last four digits of an account number or Social Security number.
- Redaction – Redacts a value by removing it.
- Replacement – Replaces each input value with a given value.
- Pseudonymization with secure hash – Replaces input values with a secure one-way hash generated using a data encryption key.
- Pseudonymization with format-preserving token – Replaces an input value with a “token,” or surrogate value, of the same character set and length using format-preserving encryption (FPE). Preserving the format can help ensure compatibility with legacy systems that have restricted schema or format requirements.
- Generalization bucketing – Masks input values by replacing them with “buckets,” or ranges, within which the input value falls. For example, you can bucket specific ages into age ranges or distinct values into ranges like “low,” “medium,” and “high.”
- Date shifting – Shifts dates by a random number of days per user or entity. This helps obfuscate actual dates while still preserving the sequence and duration of a series of events or transactions.
- Time extraction – Extracts or preserves a portion of Date, Timestamp, and TimeOfDay values.
Cloud DLP’s de-identification methods can handle both structured and unstructured data obfuscation to help you add an additional layer of data protection and privacy to virtually any workload.
That was just a quick look at DLP; for a more in-depth exploration check out the documentation and video series.
For more #GCPSketchnote, follow the GitHub repo. For similar cloud content follow me on Twitter @pvergadia and keep an eye out on thecloudgirl.dev
By Priyanka Vergadia Lead Developer Advocate, Google
Source Google Cloud
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







