We launched session affinity for Cloud Run services this June (in preview). You can use session affinity to improve responsiveness of services that store client-specific state on container instances. In this blog, I’ll dive deeper into when session affinity is useful for you and I’ll show you how it works on Cloud Run.
With session affinity enabled, requests from the same client are routed to the same container instance (if it is available). Examples of services that are likely to benefit from session affinity include those that make heavy use of local caching on container instances and services that use long-running connections such as WebSockets.
From our partners:
If you’re already excited and want to try out session affinity right now, refer to setting session affinity in the Cloud Run documentation.
When trying to understand session affinity, you shouldn’t think of server-side sessions. Session affinity does not enable you to durably persist server-side session data directly on the container instance. If you do this, your customers will complain about occasionally having to log in again, or about losing the contents of their shopping cart. I’ll tell you more below in “Store server-side session data in a persistent store”.
What is Cloud Run?
First, a short introduction for those of you who aren’t familiar with Cloud Run. (If you are familiar, skip down to “Session affinity by example”.)
Cloud Run is a fully-managed compute platform that lets you run your code in a container directly on top of Google’s scalable infrastructure. We’ve intentionally designed Cloud Run to make developers more productive – you get to focus on writing your code and Cloud Run takes care of running it.
There are two ways to run your code on Cloud Run. Services are used to run code that responds to web requests or events, and jobs are used to run code that runs to completion. Session affinity only applies to services since it’s a request routing feature.
Session affinity by example
Cloud Run makes sure to handle all requests that come in by starting additional containers to distribute the load. Without session affinity (the default), requests from one client can be handled by any container instance, as shown here:
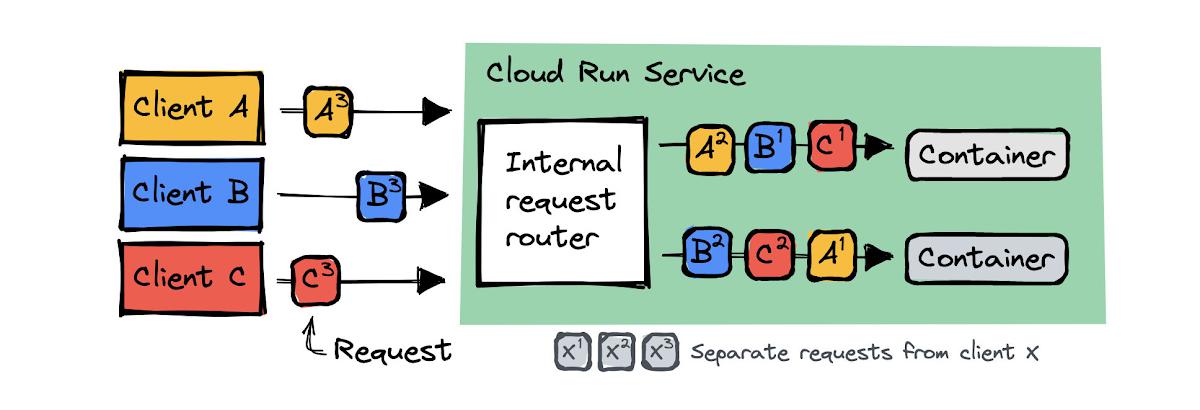
If you enable session affinity, requests from the same client will be routed to the same container instance, provided that is available and has capacity to handle the request.
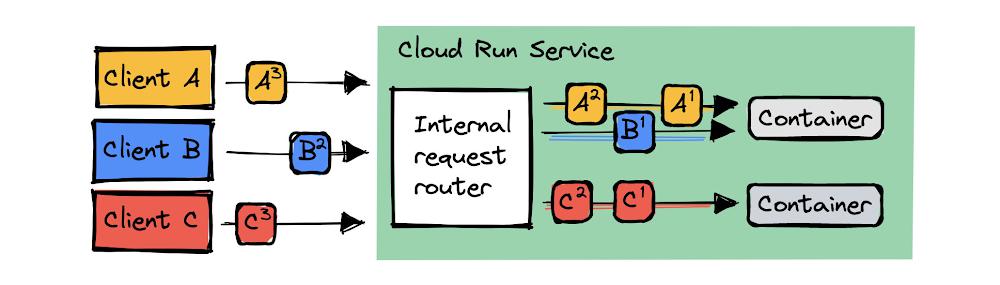
How does session affinity work?
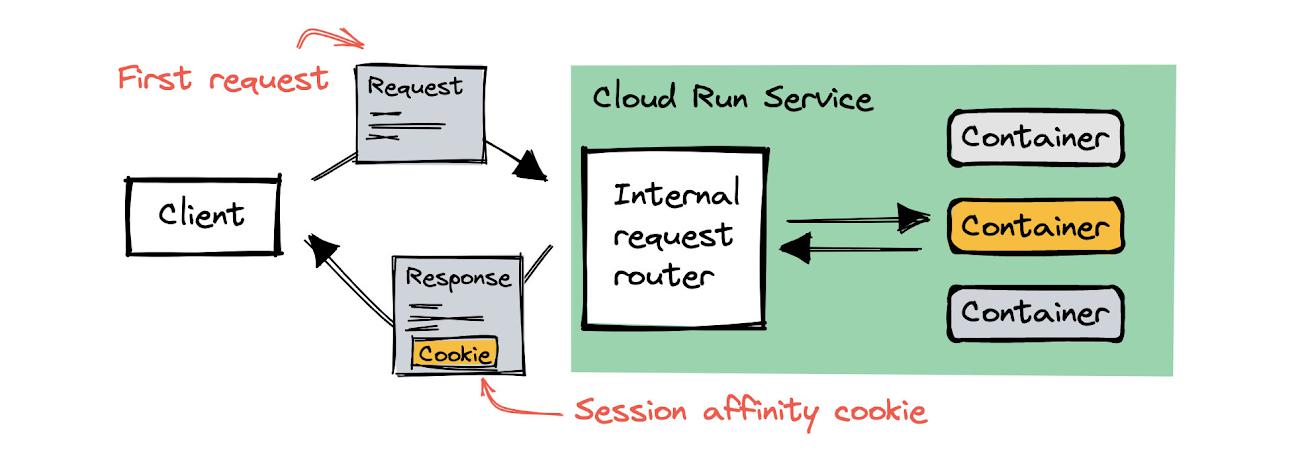
Let’s dive into how session affinity works so you can learn how to make the most of it. When Cloud Run responds to the first request from a client, it adds a generated session affinity cookie as a response header. Cloud Run can identify the container that served the request from this cookie:

For every subsequent request from the same client, Cloud Run routes the request to the container instance that the session affinity cookie links to.
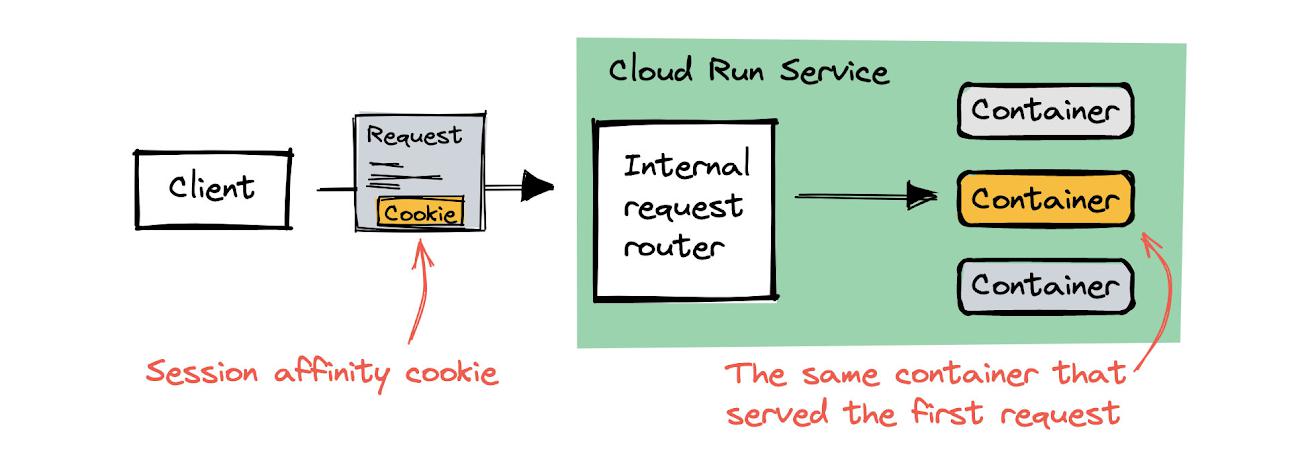
Handling cookies on the client
Browsers handle cookies transparently for you. If a server sends a response header with a cookie, your browser adds the cookie to subsequent requests.
If you’re sending requests programmatically you often need to explicitly manage cookies. If you’re sending requests from your code, you need to make sure that the session affinity cookie is added to all requests. This also applies if you’re sending requests from a script using a tool such as curl.
WebSocket streams use session affinity cookies in the same way as requests do. If a browser starts a WebSocket, it initializes the stream with a HTTP-based handshake that includes cookies. If that doesn’t make sense right now, don’t worry, I’ll dive deeper into it further down in “WebSockets reconnect to the same instance with session affinity”
Session affinity is all about avoiding the cost of rebuilding local state
Now that you know how session affinity works on Cloud Run, let’s make its benefits more concrete using an example of an application that makes heavy use of local caching on container instances. The example is based on an application I once built.

Let’s imagine you’re building a dashboard that lets users visualize query results. Users can view results and drill down using filters. Your application requests the data from an ancient backend system that isn’t very performant. You can’t send too many queries at the same time, and the response times are in the order of 10s of seconds.
Since you want to provide your users with a great experience, you’ve introduced caching to increase the responsiveness of the dashboard. Every time your application makes a query to the slow backend, it makes sure to store the results in memory. When users apply filters to the data, your code doesn’t send additional queries to the slow backend, but it filters the in-memory result set instead.
The results in the dashboard are client-specific, since every client tends to view different data. In essence, your application stores a big lookup table in memory with the client ID as the key and the cached results as the value. Thankfully, you found a library that handles all the hard parts of caching. All you have to do is get the results, and the library takes care of invalidating outdated records and maintaining a maximum size in memory.
Caching works so well for this dashboard, you’re even thinking about predicting future queries to prefetch results.
As your service grows more popular, you discover an issue. Performance gets progressively worse when there’s heavy traffic to your service. It looks like your in-memory cache is not used effectively when Cloud Run starts adding additional containers to handle all requests.
As Cloud Run adds container instances to handle incoming traffic, clients are likely to send subsequent requests to an instance that doesn’t have their cached results, and your application ends up unnecessarily re-requesting the data from the backend system again.
Session affinity helps to resolve this problem, since it makes a best effort to route client requests to the same container instance every time, allowing effective use of the query results cache.
I’m sure you can think of similar examples. Session affinity is all about avoiding the cost of rebuilding local state.
What happens when the container can’t handle a request?
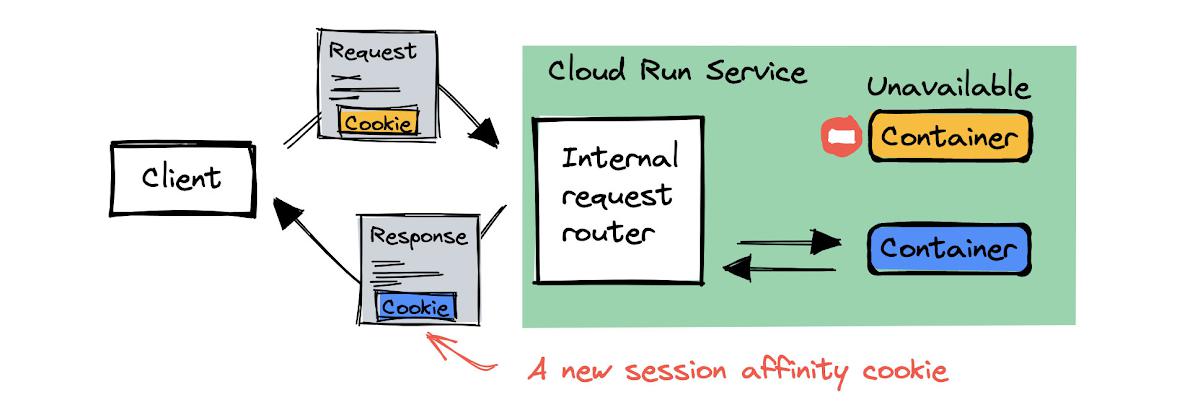
If Cloud Run receives a request for a container instance that can’t handle the request, Cloud Run still serves the request and uses a different container instance.
Cloud Run sends a response with an updated session affinity cookie that points to the new container instance. All subsequent requests will be served by the new container instance.
When does Cloud Run select a different container to serve the request?
There are various reasons why a container can be unavailable to handle requests. One reason can be that the container instance has been removed from the service. The Cloud Run autoscaler removes container instances as it scales in, and session affinity doesn’t keep container instances alive.
The other reasons have to do with the capacity of the container to handle requests. Cloud Run wants to make sure that the container can serve the request if it forwards it. Here are two examples of reasons why Cloud Run might decide to break session affinity and serve a request using a different container instance:
Concurrency limit
- Handling the request would cause the container to exceed the maximum concurrency of the container instance. Cloud Run limits the number of requests that can be handled by a container at the same time (refer to concurrency to learn more about this configurable setting).
High CPU
- Cloud Run avoids sending requests to container instances with high CPU utilization.
What happens when Cloud Run scales out the number of container instances?
Cloud Run automatically adds container instances to handle all incoming requests (that’s called scaling out). When a scale out event happens, the affinity of existing clients doesn’t change immediately. If Cloud Run receives a request with a session affinity cookie, it always tries to honor the affinity and deliver the request to the designated container instance.
One thing to keep in mind is that scale outs happen when the existing container instances are already busy handling requests and Cloud Run thinks it’s time to add more. The affinity of existing clients might change when their requests hit overloaded instances and are moved off to newly started instances.
Container lifetime is not guaranteed for the duration of a session
While the session affinity cookie has a set lifetime of 30 days, that doesn’t mean Cloud Run keeps a container instance ready for your client for 30 days. Regardless whether clients have affinity with a container instance, Cloud Run can decide to restart or remove the container instance.
Don’t worry, container instances remain active while serving requests. To stop a container, Cloud Run first stops forwarding requests to an instance, warns the container using the SIGTERM signal, before finally stopping it after a grace period of 10 seconds.
Store server-side session data in a persistent store
Server side session data is data that relates to a user session. Examples include the contents of a shopping cart, or the logged-in status of a user. You should always store this data in a persistent store.
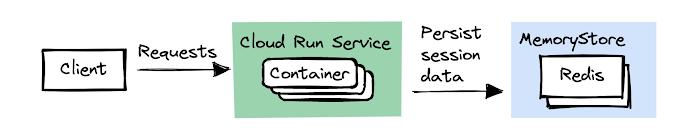
Many web frameworks store server-side session data on the filesystem by default. That’s great for a local development environment, but on Cloud Run it doesn’t work so well, even with session affinity enabled.
To understand why, recall how on Cloud Run session affinity is a best effort. As I outlined earlier in this article, there are several reasons why a request can land on a different container instance than the container instance that served the first request. If your application stored the shopping cart content on the first container instance, that session data is lost to the client when the affinity moves to another container instance. The user sees an empty cart.
On Google Cloud, there are several options available to store server-side session data. One option is to use Memorystore, which is a fully-managed Redis or Memcached. A proprietary alternative is Firestore, our managed NoSQL document store. If you choose one of the multi-regional locations of Firestore, you get a 99.999% monthly uptime service level agreement (SLA).
WebSockets reconnect to the same instance with session affinity
Before I’m wrapping up this article, I’d like to dive deeper into another use case I called out in the introduction – applications that use WebSockets.
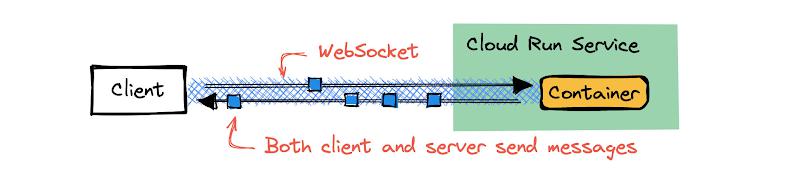
WebSockets are popular because they provide web servers with a way to send messages directly to connected clients. WebSockets are an end-to-end connection between a client (usually a browser) and a server, enabling use cases that include message notifications, collaborative editing tools, and multiplayer games. Cloud Run has complete support for WebSockets by default – no configuration needed.
As long as the connection is open, Cloud Run won’t stop the container instance – we’ve documented that right here in the container runtime contract. You might wonder why you should care about session affinity when using WebSockets.
The reality is that connections can break for various reasons, including application errors. You should also keep in mind that Cloud Run enforces the maximum duration of requests for WebSockets too. If a connection lasts for longer than the timeout, Cloud Run terminates the connection.
If a WebSocket connection is disrupted, it’s convenient if the client reconnects to the same instance, to avoid having to rebuild any server-side state. If you’re building a game, you’d like to avoid additional lag, or you don’t like to restore a player to the last state that was snapshotted and persisted.
With session affinity, both requests and WebSockets are routed to the instance that served the first request, if it’s still there and has capacity.
WebSockets start as a regular HTTP/1.1 request and response
Session affinity works in the same way with requests and WebSockets, because if your browser initializes a new WebSocket connection, it starts with an HTTP-based handshake, as shown here:
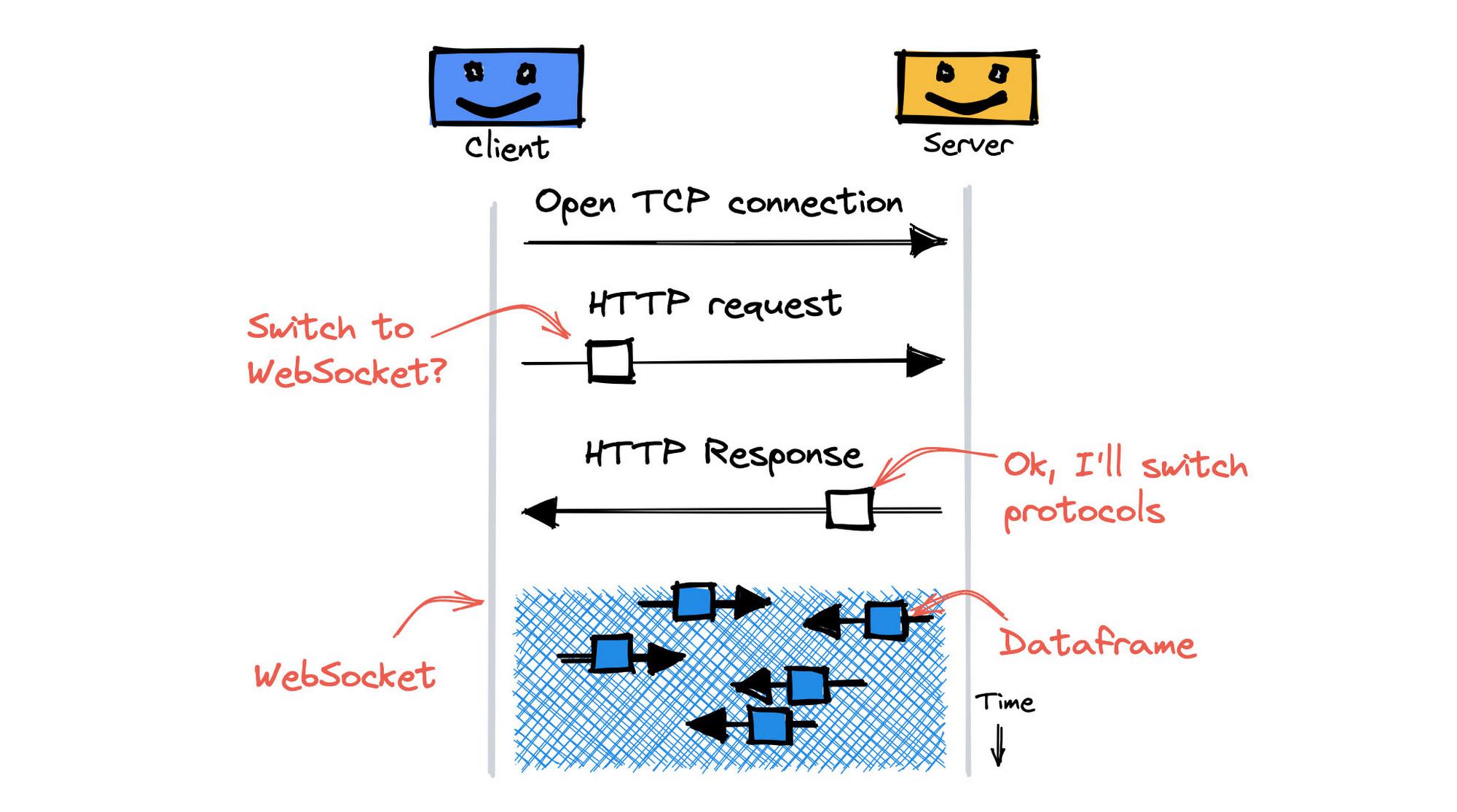
To create a WebSocket, the following happens:
- The client opens a new TCP connection.
- The client sends a regular HTTP/1.1 request that includes an Upgrade header, inviting the server to change protocols from HTTP to the WebSocket protocol.
- The server responds with an HTTP response that has status code 101 – Switching Protocols.
- Both the server and client switch to the WebSocket protocol immediately.
The HTTP request and response handshake that initiates a WebSocket connection can include HTTP headers, including the session affinity cookie.
Don’t worry, you’ll never find yourself implementing a WebSocket server on the protocol level. Libraries that help you create a WebSocket server are available for all major programming languages. Socket.io is a very popular example in Node.js.
Summary
In this post, you learned about the new feature session affinity we’re previewing since this June. This is what’s important to remember about session affinity:
- It routes client requests to the same instance that served the initial request, using a generated session affinity cookie.
- It’s all about avoiding the cost of rebuilding local state, use it as an optimization.
- It’s a best effort, not a guarantee. A container might be unavailable or out of capacity when a request comes in, in which case Cloud Run moves the affinity to a different container.
- Definitely don’t use it for storing data that needs to persist between requests and can’t be easily rebuilt, such as server-side session data.
Next steps
Here are some ideas for where to go next:
- Work through the codelab Dev to Prod in Three Easy Steps with Cloud Run that shows you how to build a small web app and deploy it to Cloud Run.
- Learn how to enable session affinity.
Session affinity launched in preview and we’re looking forward to hearing your feedback. Reach out to me if you have any feedback! I’m @wietsevenema on Twitter and Wietse Venema on LinkedIn.
By: Wietse Venema (Developer Advocate at Google Cloud)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!




