When you build a Machine Learning (ML) product, consider at least two MLOps scenarios. First, the model is replaceable, as breakthrough algorithms are introduced in academia or industry. Second, the model itself has to evolve with the data in the changing world.
We can handle both scenarios with the services provided by Vertex AI. For example:
From our partners:
- AutoML capability automatically identifies the best model based on your budget, data, and settings.
- You can easily manage the dataset with Vertex Managed Datasets by creating a new dataset or adding data to an existing dataset.
- You can build an ML pipeline to automate a series of steps that start with importing a dataset and end with deploying a model using Vertex Pipelines.
This blog post shows you how to build this system. You can find the full notebook for reproduction here. Many folks focus on the ML pipeline when it comes to MLOps, but there are more parts to building MLOps as a “system”. In this post, you will see how Google Cloud Storage (GCS) and Google Cloud Functions manage data and handle events in the MLOps system.
Architecture
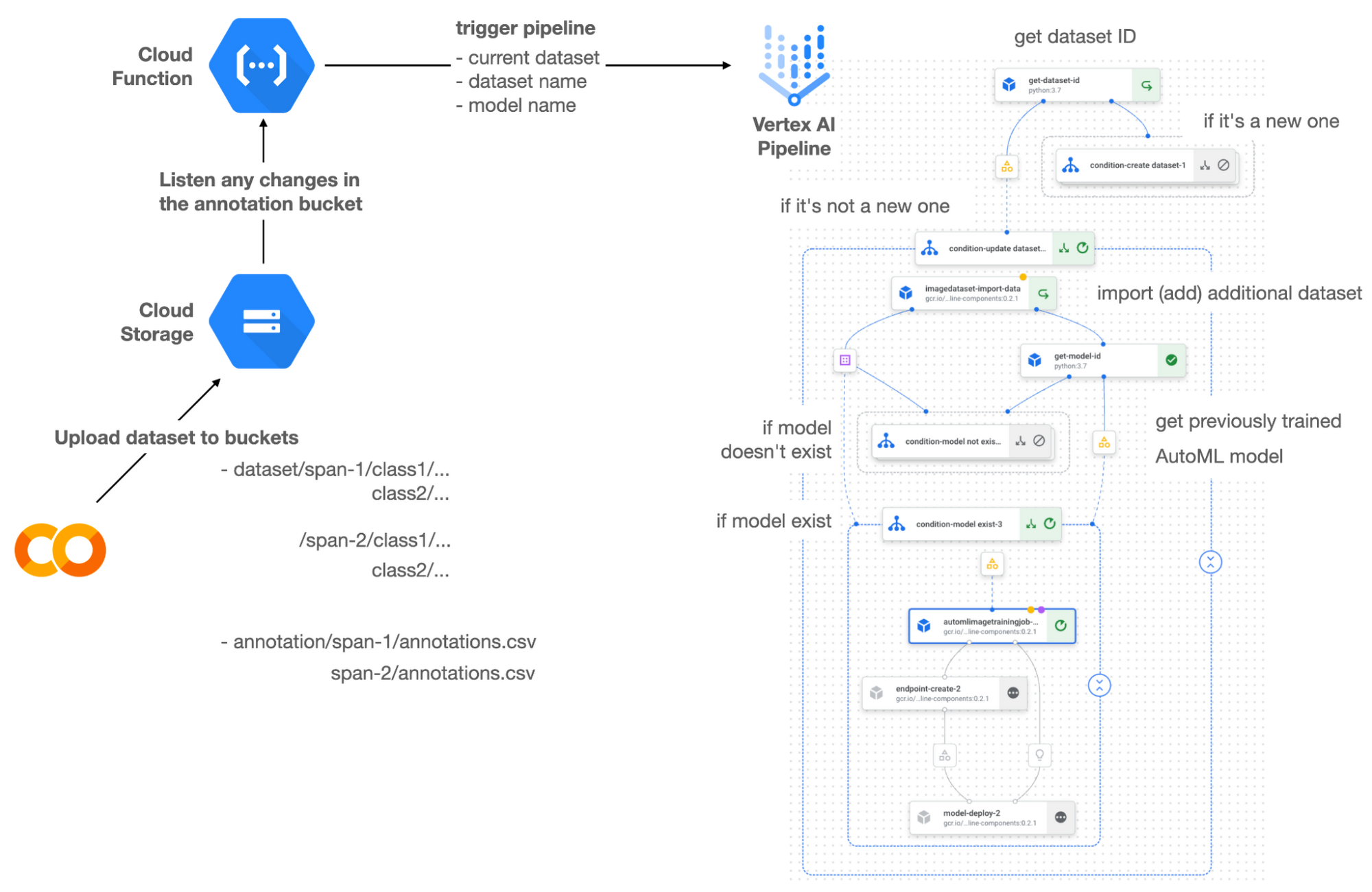
Figure 1 shows the overall architecture presented in this blog. We cover the components and their connection in the context of two common workflows of the MLOps system.
Components
Vertex AI is at the heart of this system, and it leverages Vertex Managed Datasets, AutoML, Predictions, and Pipelines. We can create and manage a dataset as it grows using Vertex Managed Datasets. Vertex AutoML selects the best model without your knowing much about modeling. Vertex Predictions creates an endpoint (RestAPI) to which the client communicates.
It is a simple, fully managed yet somewhat complete end-to-end MLOps workflow moves from a dataset to training a model that gets deployed. This workflow can be programmatically written in Vertex Pipelines. Vertex Pipelines outputs the specification for an ML pipeline allowing you to re-run the pipeline whenever or wherever you want. Specify when and how to trigger the pipeline using Cloud Functions and Cloud Storage.
Cloud Functions is a serverless way to deploy your code in Google Cloud. In this particular project, it triggers the pipeline by listening to changes on the specified Cloud Storage location. Specifically, if a new dataset is added, for example, a new span number is created; the pipeline is triggered to train the dataset, and a new model is deployed.
Workflow
This MLOps system prepares the dataset with either Vertex Dataset’s built-in user interface (UI) or any external tools based on your preference. You can upload the prepared dataset into the designated GCS bucket with a new folder named SPAN-NUMBER. Cloud Functions then detects the changes in the GCS bucket and triggers the Vertex Pipeline to run the jobs from AutoML training to endpoint deployment.
Inside the Vertex Pipeline, it checks if there is an existing dataset created previously. If the dataset is new, Vertex Pipeline creates a new Vertex Dataset by importing the dataset from the GCS location and emits the corresponding Artifact. Otherwise, it adds the additional dataset to the existing Vertex Dataset and emits an artifact.
When the Vertex Pipeline recognizes the dataset as a new one, it trains a new AutoML model and deploys it by creating a new endpoint. If the dataset isn’t new, it tries to retrieve the model ID from Vertex Model and determines whether a new AutoML model or an updated AutoML model is needed. The second branch determines whether the AutoML model has been created. If it hasn’t been created, the second branch creates a new model. Also, when the model is trained, the corresponding component emits the artifact as well.
Directory structure that reflects different distributions
In this project, I have created two subsets of the CIFAR-10 dataset, SPAN-1 and SPAN-2. A more general version of this project can be found here, which shows how to build training and batch evaluation pipelines pipelines. The pipelines can be set up to cooperate so they can evaluate the currently deployed model and trigger the retraining process.
ML Pipeline with Kubeflow Pipelines (KFP)
We chose to use Kubeflow Pipelines to orchestrate the pipeline. There are a few things that I would like to highlight. First, it’s good to know how to make branches with conditional statements in KFP. Second, you need to explore AutoML API specifications to fully leverage AutoML capabilities, such as training a model based on the previously trained one. Last, you also need to find a way to emit artifacts for Vertex Dataset and Vertex Model to consume that Vertex AI can recognize them. Let’s go through these one by one.
Branching strategy
In this project, there are two main conditions and two sub-branches inside the second main branch. The main branches split the pipeline based on a condition if there is an existing Vertex Dataset. The sub-branches are applied in the second main branch, which is selected when there is an exciting Vertex Dataset. It looks up the list of models and decides to train an AutoML model from scratch or a previously trained one.
ML pipelines written in KFP can have conditions with a special syntax of kfp.dsl.Condition. For instance, we can define the branches as follows:
from google_cloud_pipeline_components import aiplatform as gcc_aip# try to get Vertex Dataset IDdataset_op = get_dataset_id(...)with kfp.dsl.Condition(name="create dataset",dataset_op.outputs['Output'] == 'None'):# Create Vertex Dataset, train AutoML from scratch, deploy modelwith kfp.dsl.Condition(name="update dataset",dataset_op.outputs['Output'] != 'None'):# Update existing Vertex Dataset...# try to get Vertex Model IDmodel_op = get_model_id(...)with kfp.dsl.Condition(name='model not exist',model_op.outputs['Output'] == 'None'):# Create Vertex Dataset, train AutoML from scratch, deploy modelwith kfp.dsl.Condition(name='model exist',model_op.outputs['Output'] != 'None'):# Create Vertex Dataset, train AutoML based on trained one, deploy model
get_dataset_id and get_model_id are custom KFP components used to determine if there is an existing Vertex Dataset and Vertex Model respectively. Both return “None” if a model is found and some other value if a model isn’t found. They also emit Vertex AI-aware artifacts. You will see what this means in the next section.
Emit Vertex AI-aware artifacts
Artifacts track the path of each experiment in the ML pipeline and display metadata in the Vertex Pipeline UI. When Vertex AI aware artifacts are released into in the pipeline, Vertex Pipeline UI displays links for its internal services such as Vertex Dataset, so that users can visit a web page for more information.
So how could you write a custom component to generate Vertex AI-aware artifacts? To do this, custom components should have Output[Artifact] in their parameters. Then you need to replace the resourceName of the metadata attribute with a special string format.
The following code example is the actual definition of get_dataset_id used in the previous code snippet:
@component(packages_to_install=["google-cloud-aiplatform","google-cloud-pipeline-components"])def get_dataset_id(project_id: str,location: str,dataset_name: str,dataset_path: str,dataset: Output[Artifact]) -> str:from google.cloud import aiplatformfrom google.cloud.aiplatform.datasets.image_dataset import ImageDatasetfrom google_cloud_pipeline_components.types.artifact_types import VertexDatasetaiplatform.init(project=project_id, location=location)datasets = aiplatform.ImageDataset.list(project=project_id,location=location,filter=f'display_name={dataset_name}')if len(datasets) > 0:dataset.metadata['resourceName'] =f'projects/{project_id}/locations/{location}/datasets/{datasets[0].name}'return f'projects/{project_id}/locations/{location}/datasets/{datasets[0].name}'else:return 'None'
As you see, the dataset is defined in the parameters as Output[Artifact]. Even though it appears in the parameter, it is actually emitted automatically. You just need to provide the necessary data as if it is a function variable.
The dataset component retrieves the list of Vertex Dataset by calling the aiplotform.ImageDataset.list API. If the length of it is zero, it simply returns ‘None’. Otherwise, it returns the found resource name of the Vertex Dataset and provides the dataset.metadata[‘resourceName’] with the resource name at the same time. The Vertex AI-aware resource name follows a special string format, which is ‘projects/<project-id>/locations/<location>/<vertex-resource-type>/<resource-name>’.
The <vertex-resource-type>can be anything that points to an internal Vertex AI service. For instance, if you want to specify that the artifact is the Vertex Model, then you should replace <vertex-resource-type> with models. The <resource-name> is the unique ID of the resource, and it can be accessed in the name attribute of the resource found by the aiplatform API. The other custom component, get_model_id, is written in a very similar way as well.
AutoML based on the previous model
You sometimes want to train a new model on top of the previously best model. If that is possible, the new model will probably be much better than the one trained from scratch, because it leverages previously learned knowledge.
Luckily, Vertex AutoML comes with the ability to train a model using a previous model. AutoMLImageTrainingJobRunOp component lets you train a model by simply providing the base_model argument as follows:
training_job_run_op =gcc_aip.AutoMLImageTrainingJobRunOp(...,base_model=model_op.outputs['model'],...)
When training a new AutoML model from scratch, you pass ‘None’ in the base_model argument, and it is the default value. However, you can set it with a VertexModel artifact, and the component will trigger an AutoML training job based on the other model.
One thing to be careful of is that VertexModel artifacts can’t be constructed in a typical way of Python programming That means you can’t create an instance of VertexModel artifact by setting the id found in the Vertex Model dashboard. The only way you can create one is to set the metadata[‘resourceName’] parameters properly. The same rule applies to other Vertex AI-related artifacts such as VertexDataset. You can see how the VertexDataset artifact is constructed properly to get an existing Vertex Dataset to import additional data into it. See the full notebook of this project here.
Cost
You can reproduce the same result from this project with the free $300 credit when you create a new GCP account.
At the time of this blog post, Vertex Pipelines costs about $0.03/run, and the type of underlying VM for each pipeline component is e2-standard-4, which costs about $0.134/hour. Vertex AutoML training costs about $3.465/hour for image classification. GCS holds the actual data, which costs about $2.40/month for 100GiB capacity, and Vertex Dataset is free.
To simulate two different branches, the entire experiment took about one to two hours, and the total cost for this project is approximately $16.59. Please find more detailed pricing information about Vertex AI here.
Conclusion
Many people underestimate the capability of AutoML, but it is a great alternative for app and service developers who have little ML background. Vertex AI is a great platform that provides AutoML as well as Pipeline features to automate the ML workflow. In this article, I have demonstrated how to set up and run a basic MLOps workflow, from data injection to training a model based on the previously-achieved best one, to deploying the model to a Vertex AI platform. With this, we can let our ML model automatically adapt to the changes in a new dataset. What’s left for you to implement is to integrate a model monitoring system to detect data/model drift. One example is found here.
By: Chansung Park (ML Google Developer Expert)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!