
Life of a real time query
Real time queries let you subscribe to some particular data in your Firestore database, and get an instant update when the data changes, synchronizing the local cache on the user’s device. The following example code uses the Firestore Web SDK to issue a real time query against the document with the key “SF”, within the collection “cities”, and will log a message in the console any time the contents of this document are updated.
From our partners:
const unsub = onSnapshot(doc(db, "cities", "SF"), (doc) => {
console.log("Current data: ", doc.data());
});
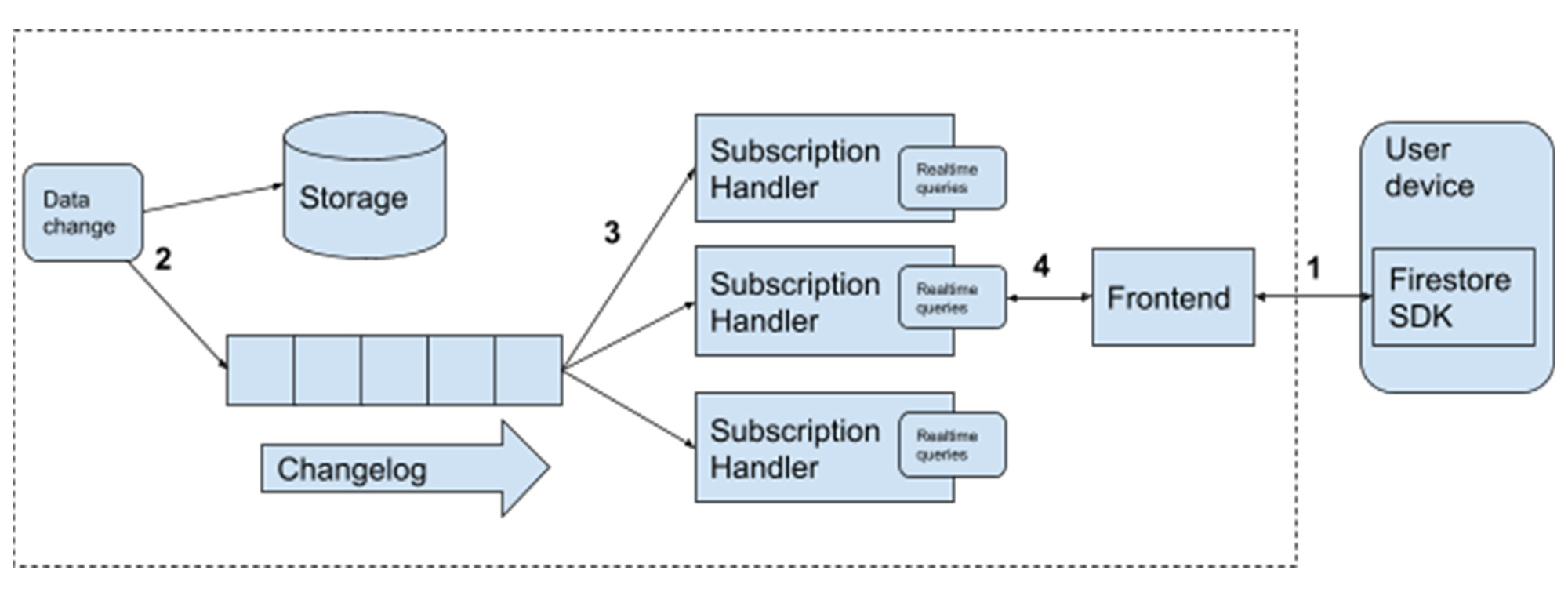
- The Firestore SDKs establish a connection from the user’s device to Firestore Front End servers. An
onSnapshotAPI call registers a new real time query with a Subscription Handler. - Whenever any data changes in Firestore, it is both persisted in replicated storage and transactionally sent to a server responsible for managing a commit-time-ordered Changelog of updates. This is the starting point for the real time query processing.
- Each change is then fanned out from the ChangeLog to a pool of Subscription Handlers.
- These handlers check which active real time queries match a specific data change, and in the case of a match (in the example above, whenever there is a change to the “cities/SF” document) forward the data to the Frontend and in turn to the SDK and the user’s application.
A key part of Firestore’s scalability is the fan-out from the Changelog to the SubscriptionHandler to the Frontends. This allows a single data change to be propagated efficiently to serve millions of real time queries and connected users. High availability is achieved by running many replicas of all these components across multiple zones (or multiple regions in the case of a multi-region deployment).
Previously, the changelogs were managed by a single backend server for each Firestore database. This meant that the maximum write throughput for Firestore Native was limited to what could be processed by one server.
Best practices when using Firestore at high scale
While this improvement to Firestore makes it easy to create very scalable applications, consider these best practices when designing your application to ensure that it will run optimally.
Control traffic to avoid hotspots
Both Firestore’s storage layer and changelogs have automatic load splitting functionality. This means that when the traffic increases, it will automatically be distributed across more servers. However, the system may take some time to react and typical split operations can take a few minutes to take effect.
A common problem in systems with automatic load splitting is hotspots— traffic that is increasing so fast that the load splitter can’t keep up. The typical effect of a hotspot is increased latency for write operations, but in the case of real time queries they can also mean slower notifications for the queries listening to data that is being hotspotted.
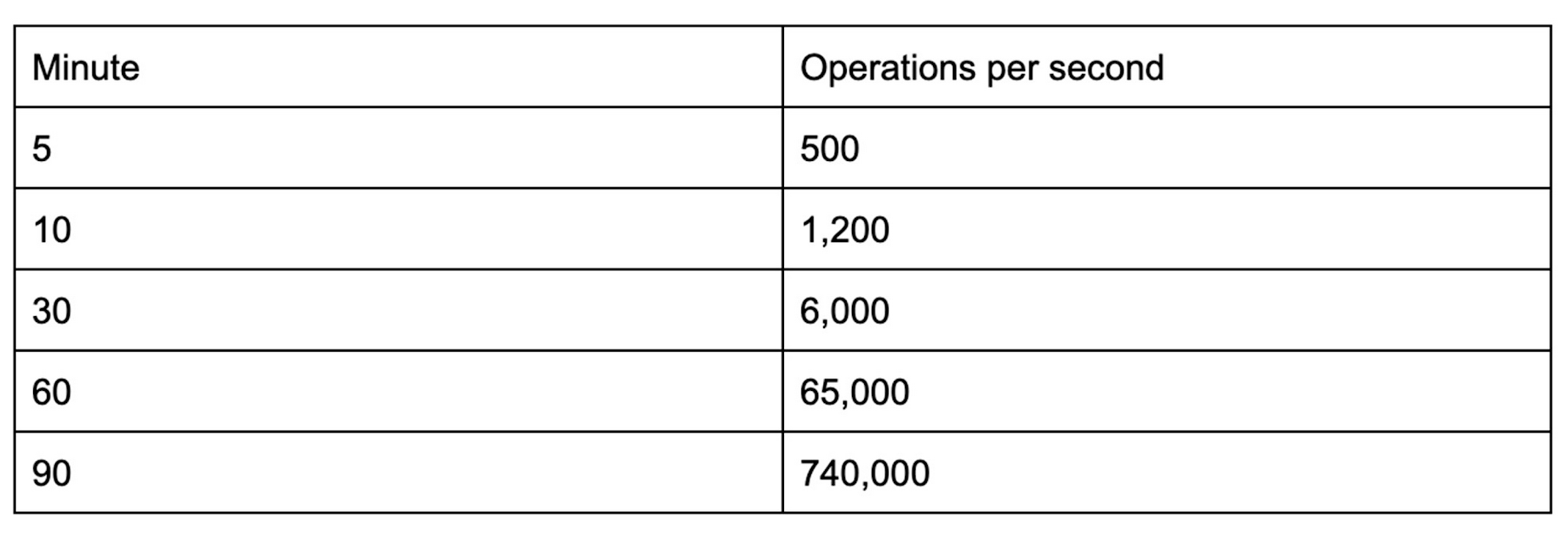
The best way to avoid hotspots is to control the way you ramp up traffic. For a good rule of thumb, we recommend following the “555 rule“. If you’re starting cold, start your traffic at 500 operations per second, then increase by at most 50% every 5 minutes. If you have a steady rate of traffic already, you can increase the rate more aggressively.
Keep documents, result sets, and batches small
To ensure low latency response time from real time queries, it is best to keep the data lean. Documents with small payloads (e.g. field count, field value size, etc) can be quickly processed by the query system, and this keeps your application responsive. Big batches of updates, large documents, and queries that read large sets of data, on the other hand, may slow things down, and you may see longer delays between when data is committed and when notifications are sent out. This may be counterintuitive when compared to a traditional database where batching is often a way to get higher throughput.
Control the fanout of queries
Firestore’s sharding algorithm tries to co-locate data in the same collection or collection group onto the same server. The intent is to maximize the possible write throughput while keeping the number of splits a query needs to talk to as small as possible. But certain patterns can still lead to suboptimal query processing — for example, if your application stores most of its data in one giant collection, a query against that collection may have to talk to many splits to read all the data, even if you apply a filter to the query. This in turn may increase the risk of higher variance in tail latency.
To avoid this you can design your schema and application in a way where queries can be served efficiently without going to many splits. Breaking your data into smaller collections — each one with a smaller write rate — may work better. We recommend load testing to best understand the behavior and need of your application and use case.
What’s next
- Read more about building scalable applications with Firestore
- Find out how to get real-time updates on Firestore
- Learn more about Key Visualizer for Firestore
By: Per Jacobsson (Tech Lead & Manager, Firestore Serving & Scalability)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







