
Overview of Tabnet
TabNet has a specially-designed architecture (overviewed in Fig. 1), based on sequential attention, that selects which model features to reason from at each step. This mechanism makes it possible to explain how the model arrives at its predictions and the thoughtful design helps with superior accuracy. TabNet not only outperforms alternative models (including neural networks and decision trees) but also provides interpretable feature attributions. More details, including results on academic benchmarks, can be found in our AAAI 2021 paper.
From our partners:
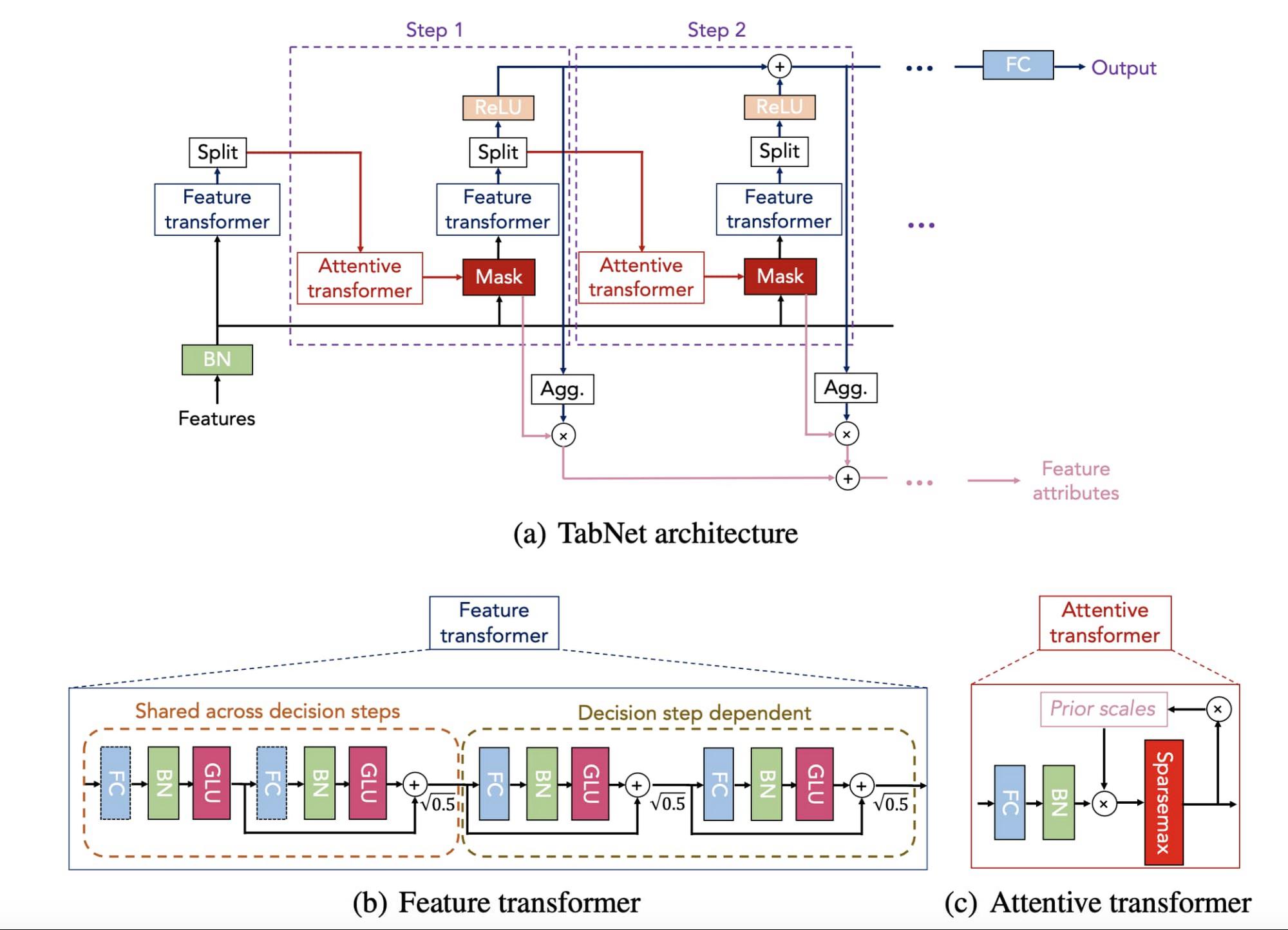
Figure 1: TabNet Architecture
Highlights of TabNet on Vertex AI Tabular Workflows
Scaling to Very Large Datasets
Fueled by the advances in cloud technologies like BigQuery, enterprises are increasingly collecting more tabular data, and datasets with billions of samples and hundreds/thousands of features are becoming the norm. In general, deep learning models get better learning from more data samples, and more features, with the optimal methods as they can better learn the complex patterns that drive the predictions. The computational challenges become significant though when model development on massive datasets is considered. This results in high cost or very long model development times, constituting a bottleneck for most customers to fully take advantage of their large datasets. With TabNet on Tabular Workflows, we’re making it more efficient to scale to very large tabular datasets.
Key Implementation Aspects: The TabNet architecture has unique advantages for scaling: it is composed mainly of tensor algebra operations, it utilizes very large batch sizes, and it has high compute intensity (i.e., the architecture employs a high number of operations for each data byte transmitted). These open a path to efficient distributed training on many GPUs, utilized to scale TabNet training in our improved implementation.
In TabNet on Vertex AI Tabular Workflows, we have carefully engineered the data and training pipelines to maximize hardware utilization so that users can get the best return for their Vertex AI spending. The following features enable scale with TabNet on Tabular workflows:
- Parallel data reading with multiple CPUs in a pipeline optimized to maximize GPU utilization for distributed training, reflecting best practices from Tensorflow.
- Training on multiple GPUs that can provide significant speedups on large datasets with high compute requirements. Users can specify any available machine on GCP with multiple GPUs, and the model will automatically run on them with distributed training.
- For efficient data parallelism with distributed learning, we use Tensorflow mirrored distribution strategy to support data parallelism across many GPUs. Our results demonstrate >80% utilization with several GPUs on billion-scale datasets with 100s-1000s of features.
Standard implementations of deep learning models could yield a low GPU utilization, and thus inefficient use of resources. With our implementation, TabNet on Vertex, users can get the maximal return on their compute spend on large-scale datasets.
Examples on real-world customer data: We have benchmarked the training time specifically for enterprise use cases where large datasets are being used and fast training is crucial. In one representative example, we used 1 NVIDIA_TESLA_V100 GPU to achieve state-of-the-art performance in ~1 hour on a dataset with ~5 million samples. In another example, we used 4 NVIDIA_TESLA_V100 GPUs to achieve state-of-the-art performance in ~14 hours on a dataset with ~1.4 billion samples.
Improving Accuracy given Real-World Data Challenges
Compared to its original version, TabNet on Vertex AI Tabular Workflows has improved machine learning capabilities. We have specifically focused on the common real-world tabular data challenges. One common challenge for real-world tabular data is numerical columns having skewed distributions, for which we productionized learnable preprocessing layers (e.g. including parametrized power transform families and quantile transformations) that improve the TabNet learning. Another common challenge is the high number of categories for categorical data, for which we adopted tunable high-dimensional embeddings. Another one is imbalance of label distribution, for which we added various loss function families (e.g. focal loss and differentiable AUC variants). We have observed that such additions can provide a noticeable performance boost in some cases.
Case studies with real-world customer data: We have worked with large customers to replace legacy algorithms with TabNet for a wide range of use cases, including recommendation, rankings, fraud detection, and estimated arrival time predictions. In one representative example, TabNet was stacked against a sophisticated model ensemble for a large customer. It outperformed the ensemble in most cases, leading to a nearly 10% error reduction on some of the key tasks. This is an impressive result, given that each percentage improvement on this model resulted in multi-million savings for the customer!
Out-of-the-box Explainability
In addition to high accuracy, another core benefit of TabNet is that, unlike conventional deep neural network (DNN) models such as multi-layer perceptrons, its architecture includes explainability out of the box. This new launch on Vertex Tabular Workflows makes it very convenient to visualize explanations of the trained TabNet models, so that the users can quickly gain insights on how the TabNet models arrive at its decisions. TabNet provides feature importance output via its learned masks, which indicate whether a feature is selected at a given decision step in the model. Below is the visualization of the local and global feature importance based on the mask values. The higher the value of the mask for a particular sample, the more important the corresponding feature is for that sample. Explainability of TabNet has fundamental benefits over post-hoc methods like Shapley values that are computationally-expensive to estimate, while TabNet’s explanations are readily available from the model’s intermediate layers. Furthermore, post-hoc explanations are based on approximations to nonlinear black-box functions while TabNet’s explanations are based on what the actual decision making is based on.
Explainability example: To illustrate what is achievable with this kind of explainability, Figure 2 below shows the feature importance for the Census dataset. The figure indicates that education, occupation, and number of hours per week are the most important features to predict whether a person can earn more than $50K/year (the color of corresponding columns are lighter). The explainability capability is sample-wise, which means that we can get the feature importance for each sample separately.

Figure 2: The aggregate feature importance masks in Census data, which shows the global instance-wise feature selection. Brighter colors show a higher value. Each row represents the masks for each input instance. The Figure includes the output masks of 30 input instances. Each column represents a feature. For example, the first column represents the age feature, the second column represents the workclass feature in Census data, etc. The figure shows that education, occupation, and number of hours per week are the most important features (these corresponding columns have “light” shading).
Benefits as a Fully-Managed Vertex Pipeline
TabNet on Vertex Tabular Workflows makes the model development and deployments tasks much simpler – without writing any code, one can obtain the trained TabNet model, deploy it in their application, and use the MLOps capabilities enabled by Vertex Managed Pipelines! Some of these benefits are highlighted as:
- Compatibility with Vertex AI ML Ops for implementing automated ML at scale including products like Vertex AI Pipelines and Vertex AI Experiments.
- Deployment convenience: Vertex AI prediction services, both in batch and online mode, are supported out-of-the-box.
- Customizable feature engineering to enable the best utilization of the domain knowledge of users.
- Using Google’s state-of-the-art search algorithms, automatic tuning to identify the best-performing hyperparameters, with automatic selection of the appropriate hyper-parameter search space based on dataset size, prediction type, and training budget.
- Tracking the deployed model and convenient evaluation tools.
- Easiness in comparative benchmarking with other models (such as AutoML and Wide & Deep Networks) as the user journey would be unified.
- Multi-region availability to better address international workloads.
More details
If you’re interested in trying TabNet on Vertex AI on your tabular datasets, please check out Tabular Workflow on Vertex AI and fill out this form.
Acknowledgements:We’d like to thank Nate Yoder, Yihe Dong, Dawei Jia, Alex Martin, Helin Wang, Henry Tappen and Tomas Pfister for their contributions to this blog.
By: Long T. Le (Software Engineer, Google Cloud AI) and Sercan Ö. Arik (Research Scientist, Google Cloud AI)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!






