
Relational databases like Oracle are designed to store data, but they aren’t well suited for supporting analytics at scale. Google Cloud BigQuery is a serverless, scalable cloud data warehouse that is ideal for analytics use cases. To ensure timely and accurate analytics, it is essential to be able to continuously move data streams to BigQuery with minimal latency.
From our partners:
The best way to stream data from databases to BigQuery is through log-based Change Data Capture (CDC). Log-based CDC works by directly reading the transaction logs to collect DML operations, such as inserts, updates, and deletes. Unlike other CDC methods, log-based CDC provides a non-intrusive approach to streaming database changes that puts minimal load on the database.
Striim — a unified real-time data integration and streaming platform — comes with out-of-the-box log-based CDC readers that can move data from various databases (including Oracle) to BigQuery in real-time. Striim enables teams to act on data quickly, producing new insights, supporting optimal customer experiences, and driving innovation.
In this blog post, we will outline experimental results cited in Striim’s recent white paper, Real-Time Data Integration from Oracle to Google BigQuery: A Performance Study.
Building a Data Pipeline from Oracle to Google BigQuery with Striim: Components
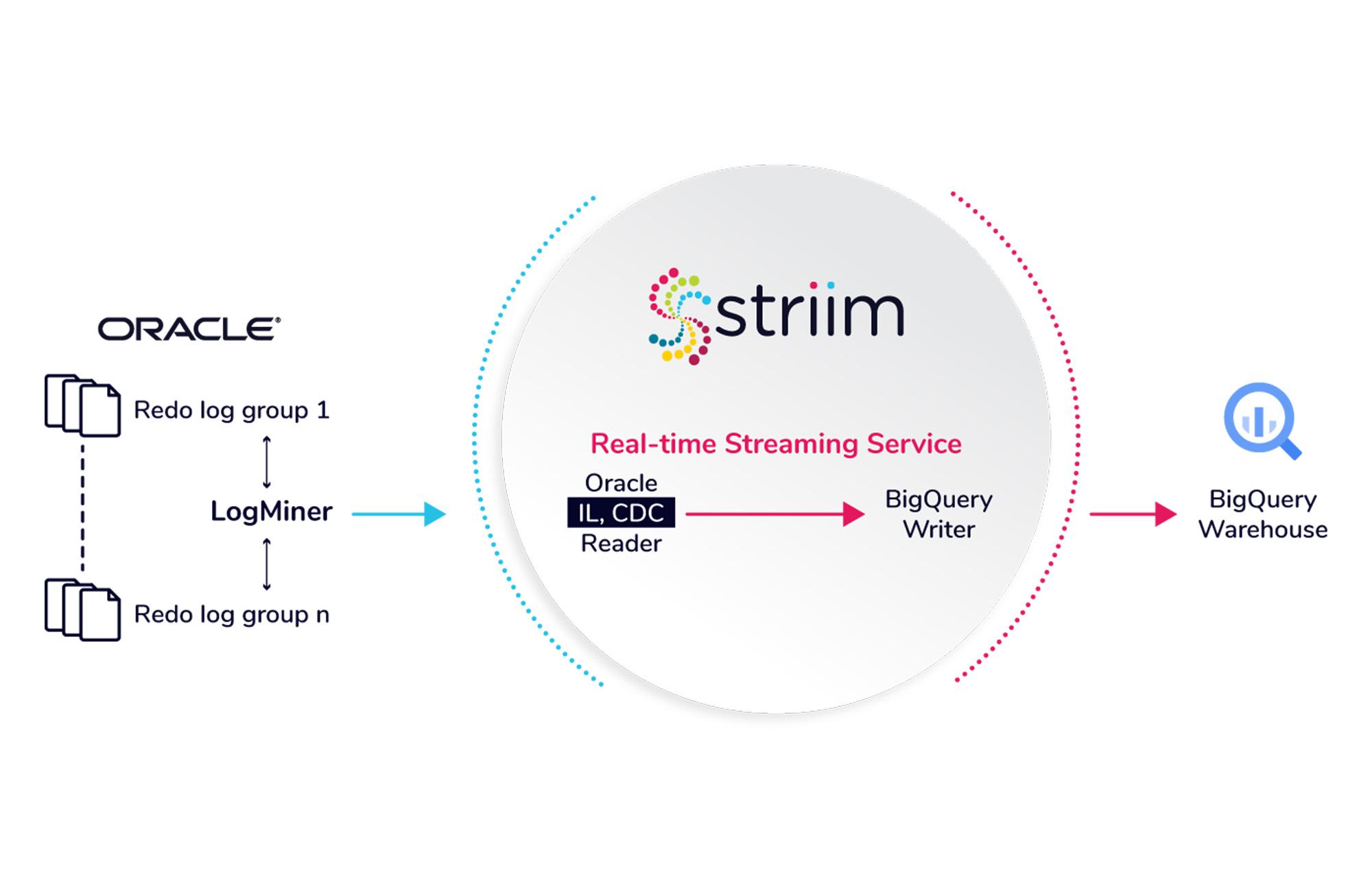
- LogMiner-based Oracle CDC Reader uses Oracle LogMiner to ingest database changes on the server side and replicate them to the streaming platform. This adapter is ideal for low and medium workloads.
- OJet adapter uses a high-performance log mining API to support high volumes of database changes on the source and replicate them in real time. This adaptor is ideal for high volume high throughput CDC workloads.
With two types of Oracle adapters to choose from, when is it advisable to use one over the other?
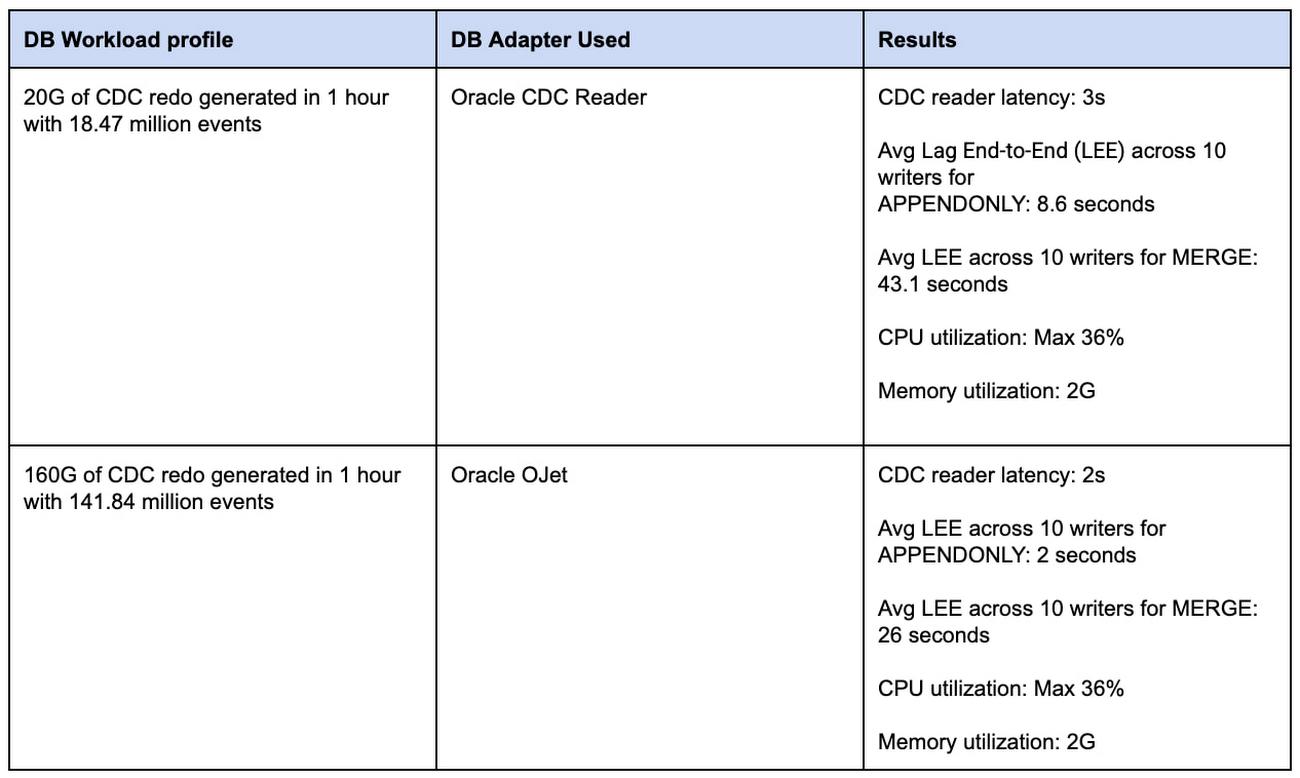
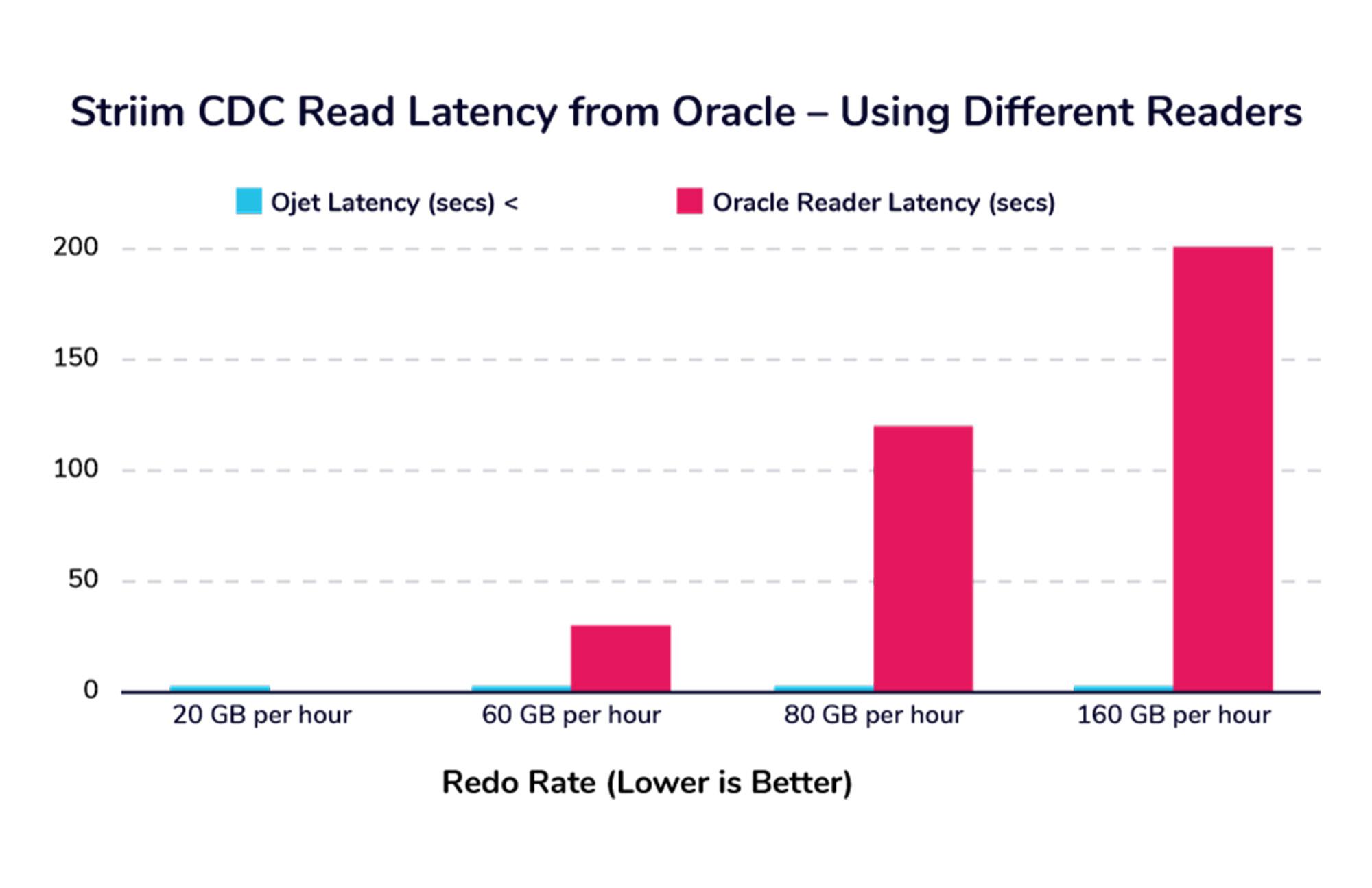
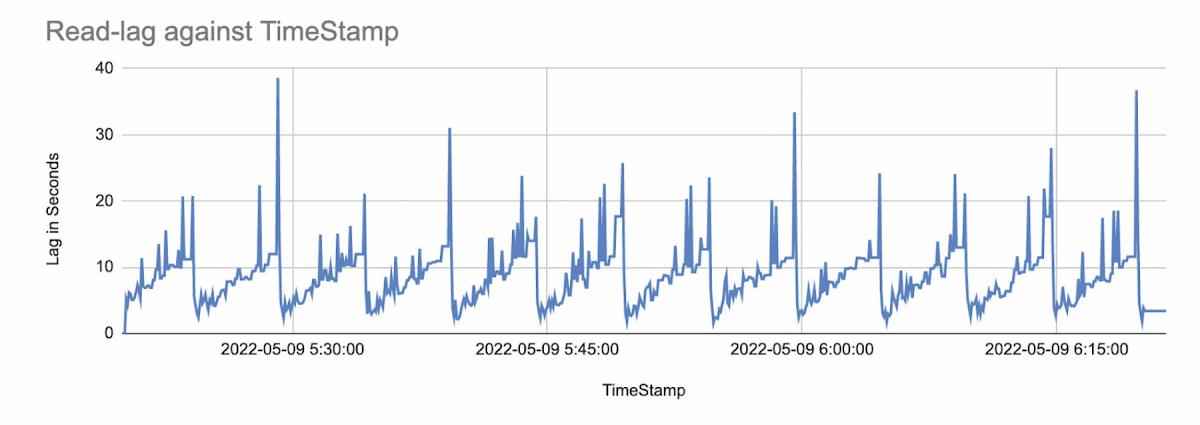
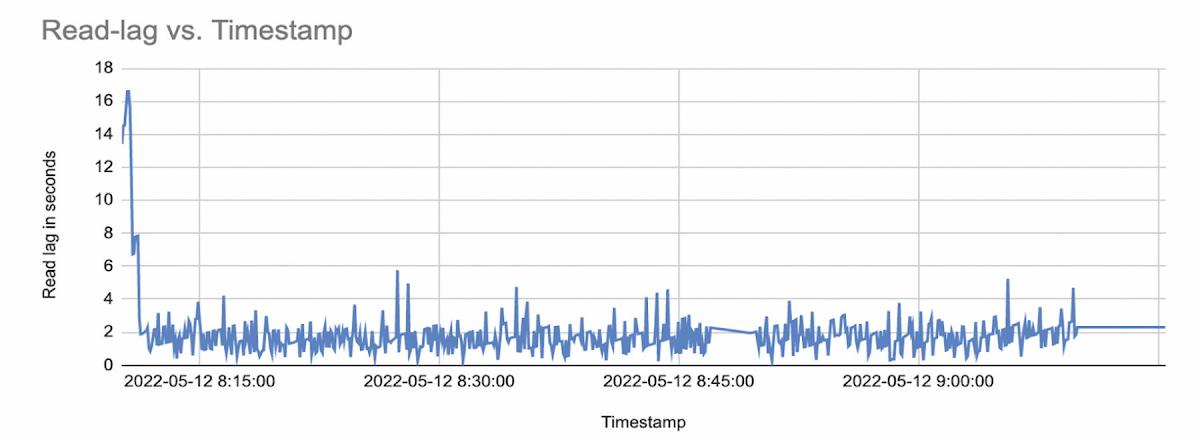
Our results show that if your DB workload profile is between 20GB and 80GB of CDC data per hour, the LogMiner based Oracle CDC reader is a good choice. If you work with a higher amount of data, then the OJet adapter is better; currently, it’s the fastest Oracle CDC Reader available. Here’s a table and chart that shows the latency (read-lag) for both adapters:
Building the Data Pipeline: Steps
We built the data pipeline for our experiment following these steps:
1. Configure the source database and profile the workload
Striim’s Oracle adapters connect to Oracle server instances to mine for redo data. Therefore it’s important to have the source database instance tuned for optimum redo mining performance. Here’s what you need to keep in mind about the configuration:
- Profile the DB workload to measure the load it generates on the source database
- Redo log sizes to a reasonably large value of 2G per log group
- For the OJet adapter, set a large size for the DB streams_pool_size to mine redo as quickly as possible
- For an extremely high CDC data rate of around 150 Gb/hour, set streams_pool_size to 4G
2. Configure the Oracle adapter
For both adapters, default settings are enough to get started. The only configuration required is to set the DB endpoints to read data from the source database. Based on your need, you can use Striim to perform any of the following:
- Handle large transactions
- Read and write data to a downstream database
- Mine from a specific SCN or timestamp
Regardless of which Oracle adapter you choose, only one adapter is needed to collect all data streams from the source database. This practice helps to cut the overhead incurred by both adapters.
3. Configure the BigQuery Writer
Use BigQuery Writer to configure how your data moves from source to database. For instance, you can set your writers to work with a specified dataset to move large amounts of data in parallel.
For performance improvement, you can use multiple BigQuery writers to integrate incoming data in parallel. Using a router ensures that events are distributed such that a single event isn’t sent to multiple writers.
Tuning the number of writers and their properties helps to ensure that data is moved from Oracle to BigQuery in real time. Since we’re dealing with large volumes of incoming streams, we configure 20 BigQuery Writers in our experiment. There are many other BigQuery Writer properties that can help you to move and control data. You can learn about them in detail here.
How to Execute the Striim App and Analyze Results
We used a Google BigQuery dataset to run our data integration infrastructure. We performed the following tasks to run our simulation and capture results for analysis:
- Start the Striim app on the Striim server
- Start monitoring our app components using the Tungsten Console by passing a simple script
- Start the Database Workload
- Capture all DB events in the Striim app, and let the app commit all incoming data to the BigQuery target
- Analyze the app performance
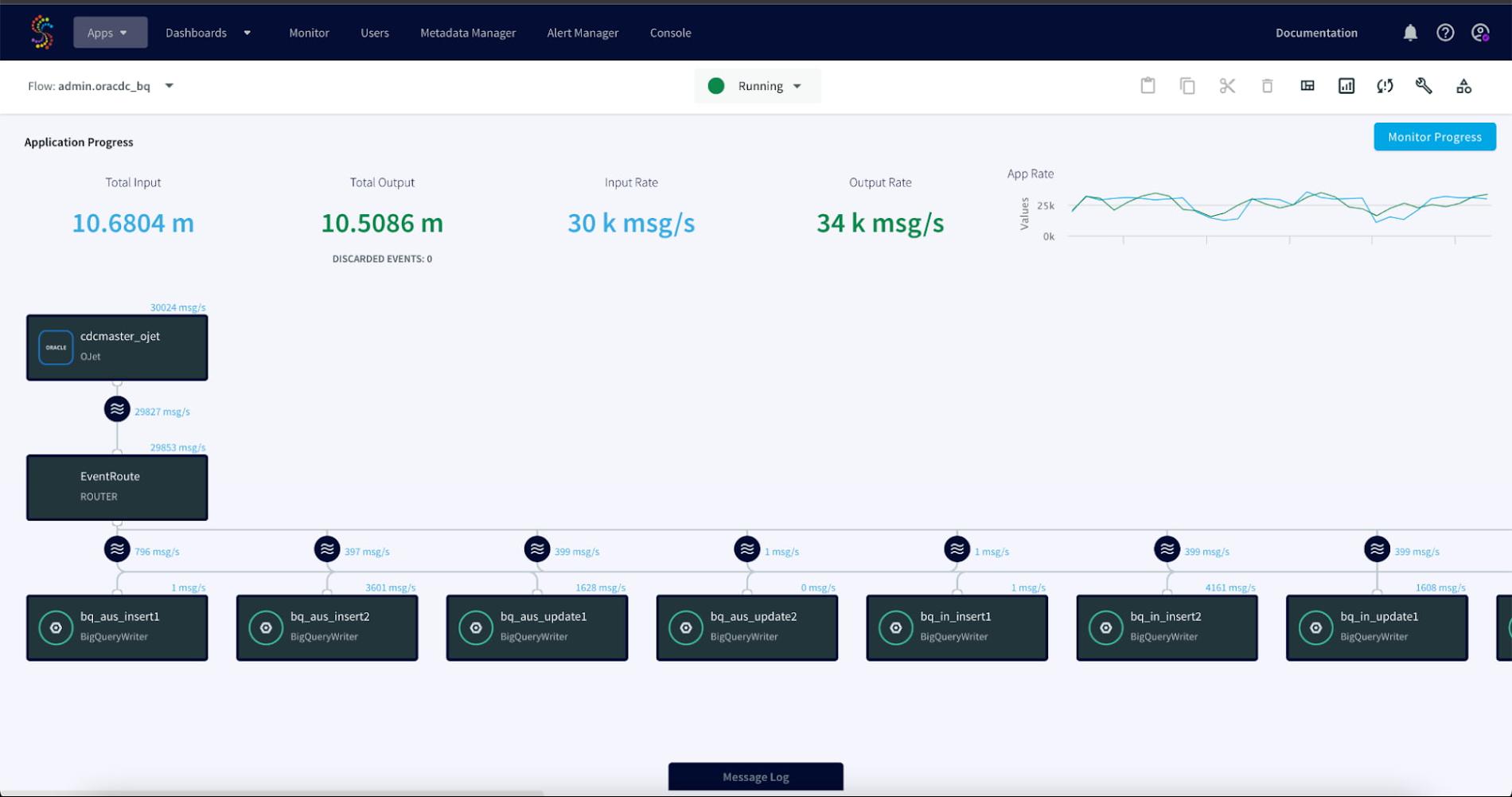
The Striim UI image below shows our app running on the Striim server. From this UI, we can monitor the app throughput and latency in real time.
Results Analysis: Comparing the Performance of two Oracle Readers
At the end of the DB workload run, we looked at our captured performance data and analyzed the performance. Details are tabulated below for each of the source adapter types.
*LEE => Lag End-to-End
Use Striim to Move Data in Real Time to Google Cloud BigQuery
This experiment showed how to use Striim to move large amounts of data in real time from Oracle to BigQuery. Striim offers two high-performance Oracle CDC readers to support data streaming from Oracle databases. We demonstrated that Striim’s OJet Oracle reader is optimal for larger workloads, as measured by read-lag, end-to-end lag, and CPU and memory utilization. For smaller workloads, Striim’s LogMiner-based Oracle reader offers excellent performance.For more in-depth information, please refer to the white paper, check out a demo, Striim’s Marketplace listing or contact Striim.
By: Sudhir Hasbe (Sr. Director of Product Management, Google Cloud) and Alok Pareek (Founder & EVP Products, Striim)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







