- Data file format
- Data compression
- Level of parallelization of data load
- Schema autodetect ‘ON’ or ‘OFF’
- Wide tables vs narrow(fewer columns) tables.
Data file format
From our partners:
Bulk insert into BigQuery is the fastest way to insert data for speed and cost efficiency. Streaming inserts are however more efficient when you need to report on the data immediately. Today data files come in many different file types including Comma Separated(CSV), JSON, PARQUET, AVRO to name a few. We are often asked how the file format matters and whether there are any advantages in choosing one file format over the other.
CSV files (comma-separated values) contain tabular data with a header row naming the columns. When loading data one can parse the header for column names. When loading from csv files one can use the header row for schema autodetect to pick up the columns. With schema autodetect set to off, one can skip the header row and create a schema manually, using the column names in the header. CSV files can use other field separators(like ; or |) too as a separator, since many data outputs already have a comma in the data. You cannot store nested or repeated data in CSV file format.
JSON (JavaScript object notation) data is stored as a key-value pair in a semi structured format. JSON is preferred as a file type because it can store data in a hierarchical format. The schemaless nature of JSON data rows gives the flexibility to evolve the schema and thus change the payload. JSON formats are user-readable. REST-based web services use json over other file types.
PARQUET is a column-oriented data file format designed for efficient storage and retrieval of data. PARQUET compression and encoding is very efficient and provides improved performance to handle complex data in bulk.
AVRO: The data is stored in a binary format and the schema is stored in JSON format. This helps in minimizing the file size and maximizes efficiency.
From a data loading perspective we did various tests with millions to hundreds of billions of rows with narrow to wide column data .We have done this test with a public dataset named `bigquery-public-data.samples.github_timeline` and `bigquery-public-data.wikipedia.pageviews_2022`. We used 1000 flex slots for the test and the number of loading(called PIPELINE slots) slots is limited to the number of slots you have allocated for your environment. Schema Autodetection was set to ‘NO’. For the parallelization of the data files, each file should typically be less than 256MB uncompressed for faster throughput and here is a summary of our findings:
Do I compress the data?
Sometimes batch files are compressed for faster network transfers to the cloud. Especially for large data files that are being transferred, it is faster to compress the data before sending over the cloud Interconnect or VPN connection. In such cases is it better to uncompress the data before loading into BigQuery? Here are the tests we did for various file types with different file sizes with different compression algorithms. Shown results are the average of five runs:
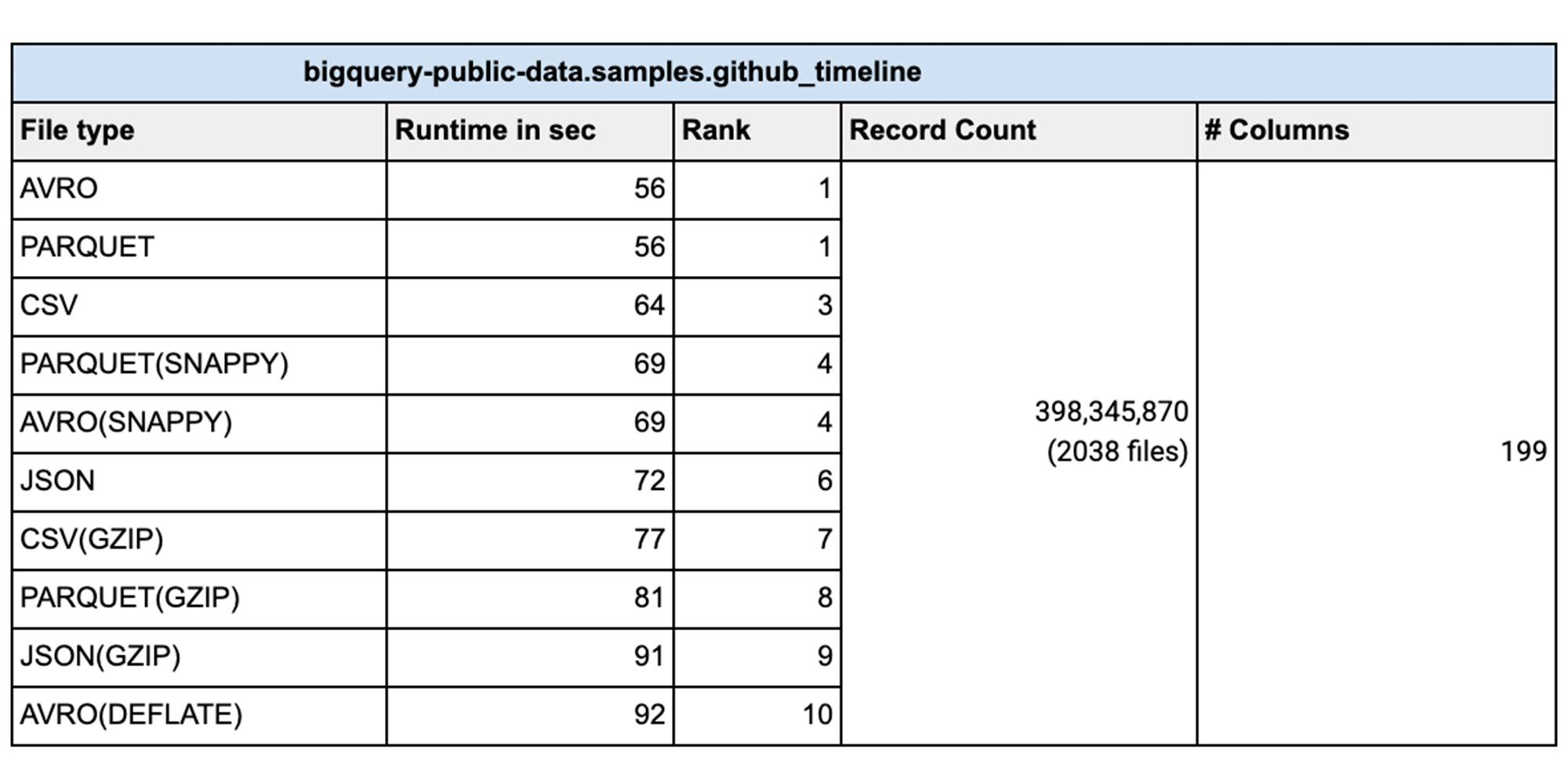
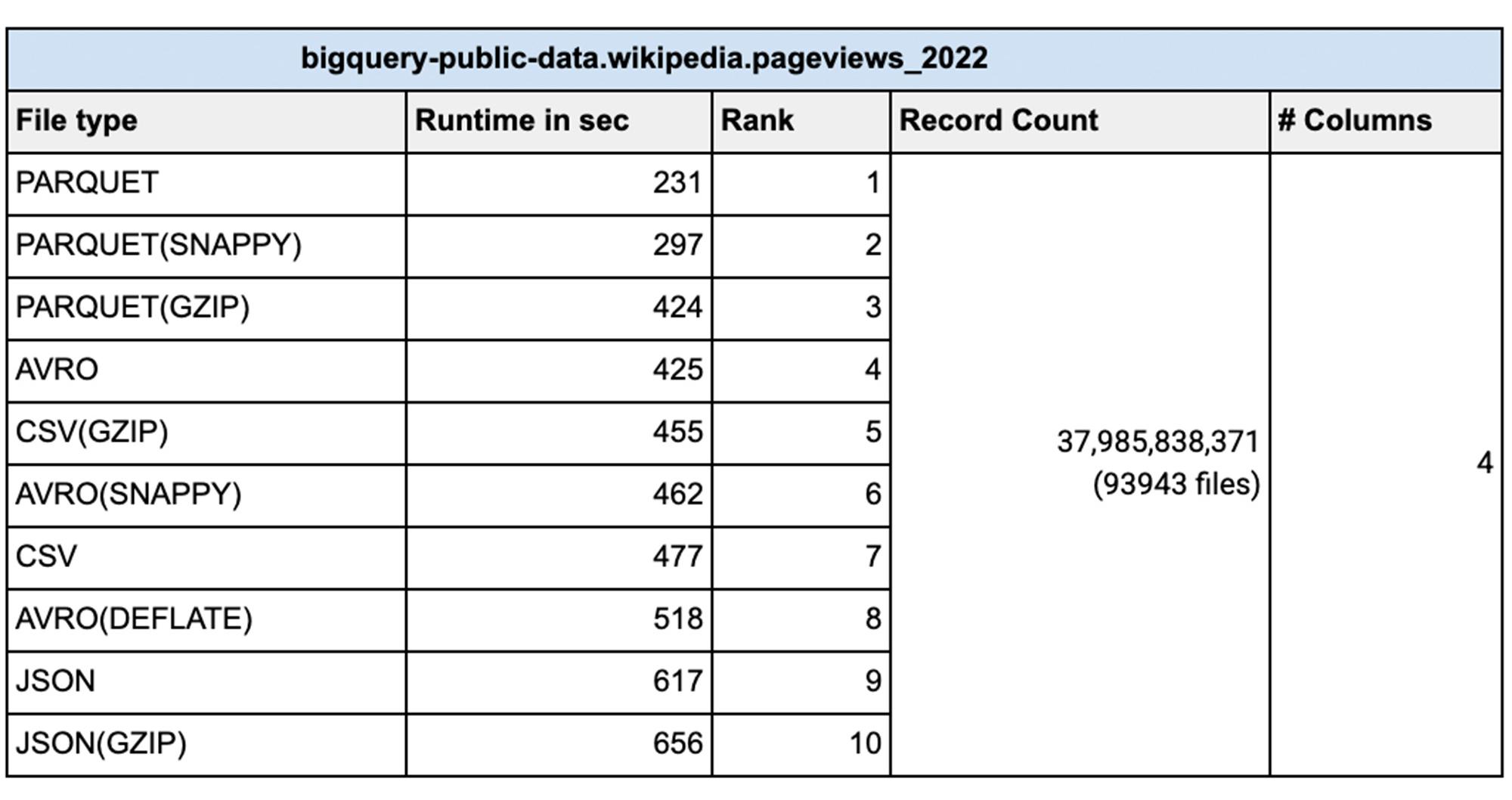
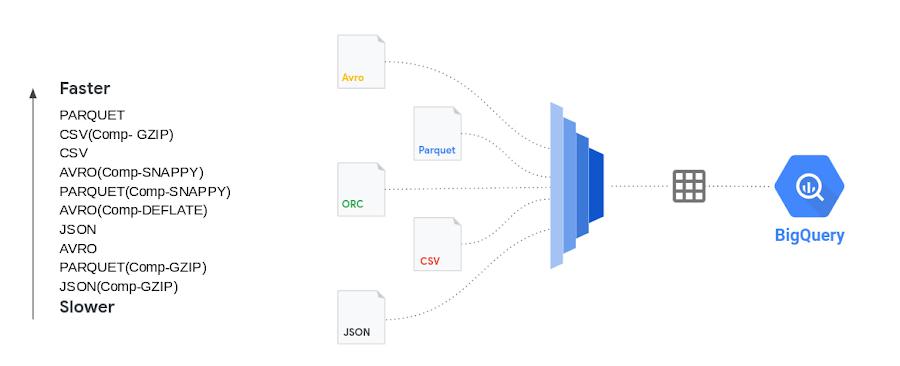
Disclaimer: These tests were done with limited resources for BigQuery in a test environment during different times of the day with noisy neighbors, so the actual timings and the number of rows might not be reflective of your test results. The numbers provided here are for comparison sake only, so that you can choose the right file types, compression for your workload. This testing was done with two tables, one with 199 columns (wide table) and another with 4 columns (narrow table). Your results will vary based on the datatypes, number of columns, amount of data, assignment of PIPELINE slots and various file types. We recommend that you test with your own data before coming to any conclusion.
By: Jit Biswas (Principal Architect – Data & Analytics, Google) and Layo Jesudhass (Customer Engineer – Data & Analytics, Google)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!