
Setting up the TensorFlow Profiler
Before you can use the TensorFlow Profiler, you’ll need to configure Vertex AI TensorBoard to work with your custom training job. You can find step by step instructions on this setup here. Once TensorBoard is set up, you’ll make a few changes to your training code, and your training job config.
From our partners:
Modify training code
First, you’ll need to install the Vertex AI Python SDK with the cloud_profiler plugin as a dependency for your training code. After installing the plugin, there are three changes you’ll make to your training application code.
First, you’ll need to import the cloud_profiler in your training script:
from google.cloud.aiplatform.training_utils import cloud_profiler
import tensorflow as tf
# create and compile model
model = tf.keras.models.Sequential(...)
model.compile(...)
# initialize profiler
cloud_profiler.init()
# create callback
# use AIP_TENSORBOARD_LOG_DIR to update where logs are written
tensorboard_callback = tf.keras.callbacks.TensorBoard(
log_dir=os.environ["AIP_TENSORBOARD_LOG_DIR"], histogram_freq=1)
# pass callback to model.fit
model.fit(x_train,
y_train,
epochs = EPOCHS,
callbacks=[tensorboard_callback],)
Configure Custom JobAfter updating your training code, you can create a custom job with the Vertex AI Python SDK.
from google.cloud import aiplatform
# create custom job
job = aiplatform.CustomJob(project=MY_PROJECT_ID,
location=REGION,
display_name=JOB_NAME,
worker_pool_specs=WORKER_POOL_SPEC,
base_output_dir=MODEL_DIR,)
# run custom job
job.run(service_account=SERVICE_ACCOUNT,
tensorboard=TENSORBOARD_INSTANCE_NAME)
Open TensorBoard
- Once you’re there go to the Profiler tab and click Capture profile
- In the Profile Service URL(s) or TPU name field, enter
workerpool0-0 - Select IP address for the Address type
- Click CAPTURE
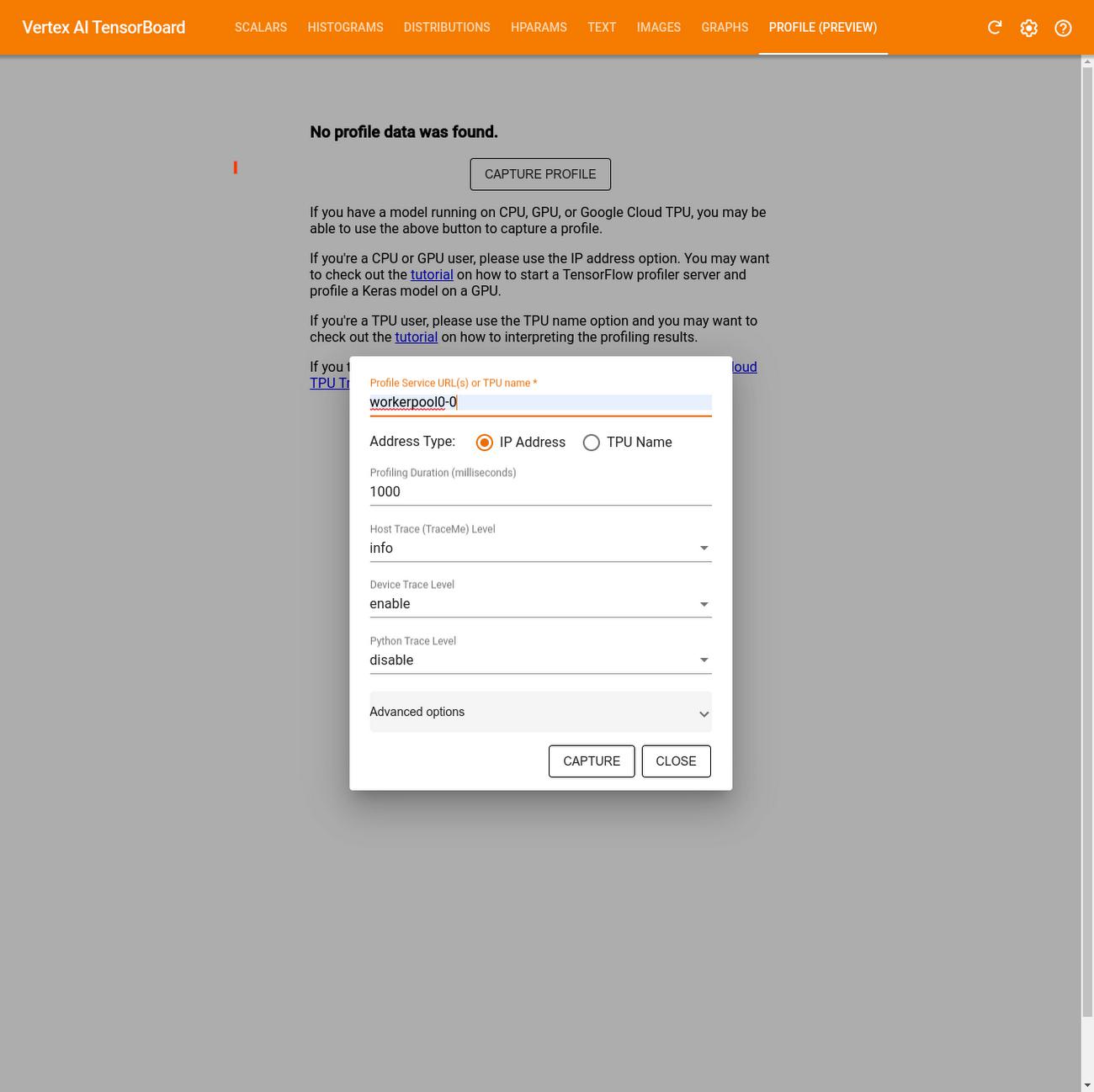
Capture Profile
Using the TensorBoard Profiler to analyze performance
Once you’ve captured a profile, there are numerous insights you can gain from analyzing the hardware resource consumption of the various operations in your model. These insights can help you to resolve performance bottlenecks and, ultimately, make the model execute faster.
The TensorFlow Profiler provides a lot of information and it can be difficult to know where to start. So to make things a little easier, we’ve outlined five ways you can get started with the profiler to better understand your training jobs.
Get a high level understanding of performance with the overview page
The TensorFlow Profiler includes an overview page that provides a summary of your training job performance.
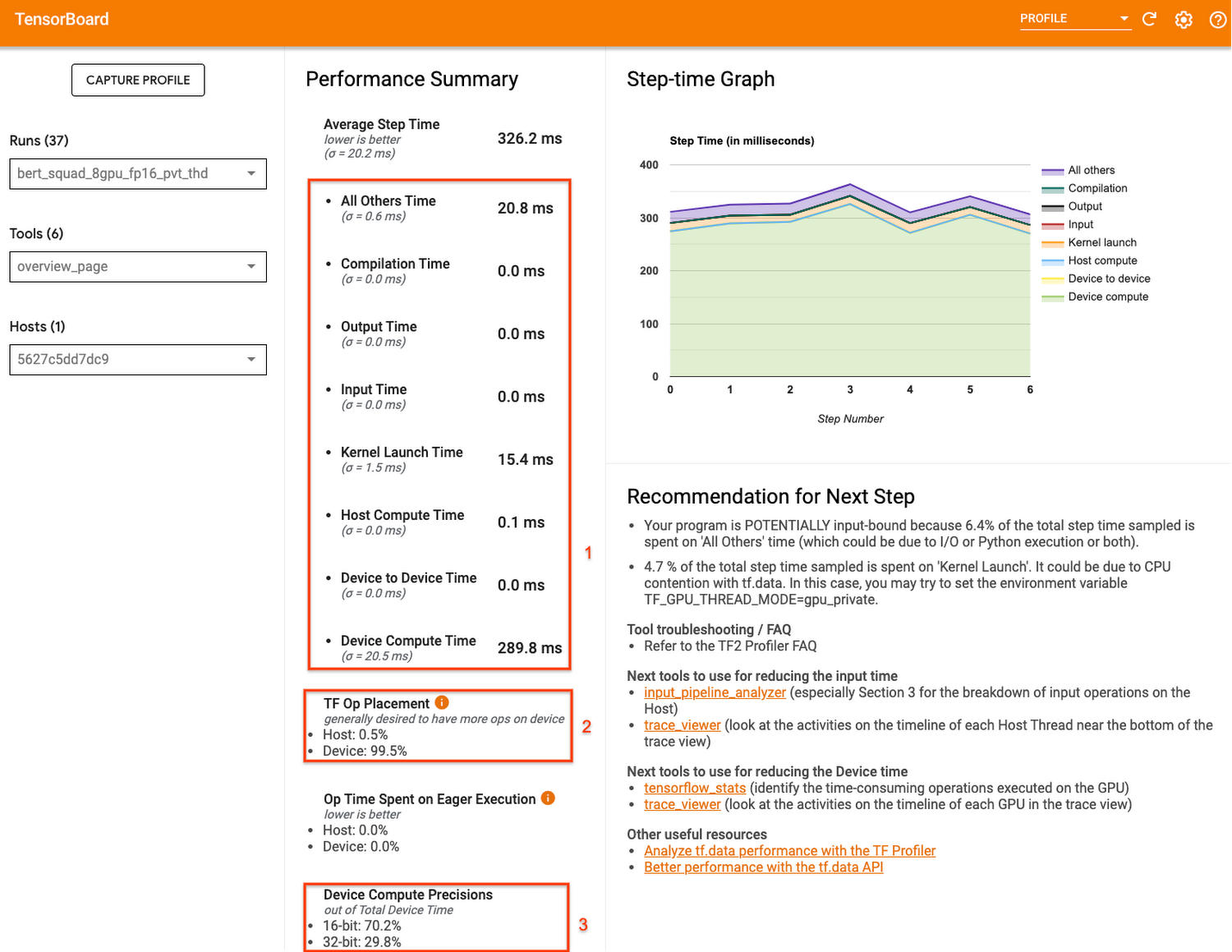
Overview Page
You’ll notice that the summary section also provides some recommendations for next steps. So in the following sections we’ll take a look at some more specialized profiler features that can help you to debug.
Deep dive into the performance of your input pipeline
After taking a look at the overview page, a great next step is to evaluate the performance of your input pipeline, which generally includes reading the data, preprocessing the data, and then transferring data from the host (CPU) to the device (GPU/TPU).
GPUs and TPUs can reduce the time required to execute a single training step. But achieving high accelerator utilization depends on an efficient input pipeline that delivers data for the next step before the current step has finished. You don’t want your accelerators sitting idle as the host prepares batches of data!
The TensorFlow Profiler provides an Input-pipeline analyzer that can help you determine if your program is input bound. For example, the profile shown here indicates that the training job is highly input bound. Over 80% of the step time is spent waiting for training data. By preparing the batches of data before the next step is finished, you can reduce the amount of time each step takes, thus reducing total training time overall.
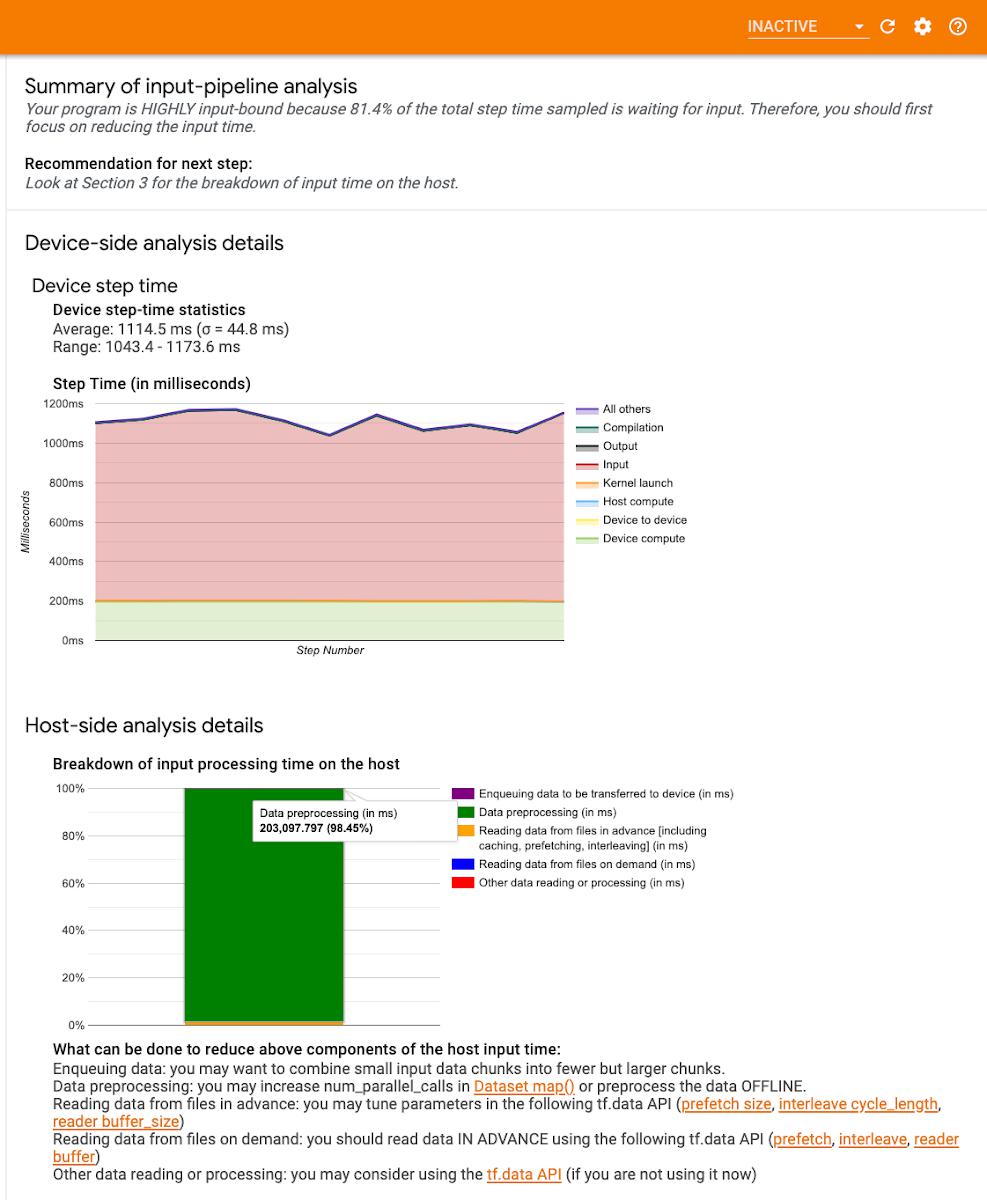
Input-pipeline analyzer
Use the trace viewer to maximize GPU utilization
The profiler provides a trace viewer, which displays a timeline that shows the durations for the operations that were executed by your model, as well as which part of the system (host or device) the op was executed. Reading traces can take a bit of time to get used to, but once you do you’ll find that they are an incredibly powerful tool for understanding the details of your program.
When you open the trace viewer, you’ll see a trace for the CPU and for each device. In general, you want to see the host execute input operations like preprocessing training data and transferring it to the device. On the device, you want to see the ops that relate to actual model training.
On the device, you should see timelines for three stream:
- Stream 13 is used to launch compute kernels and device-to-device copies
- Stream 14 is used for host-to-device copies
- Stream 15 for device to host copies.
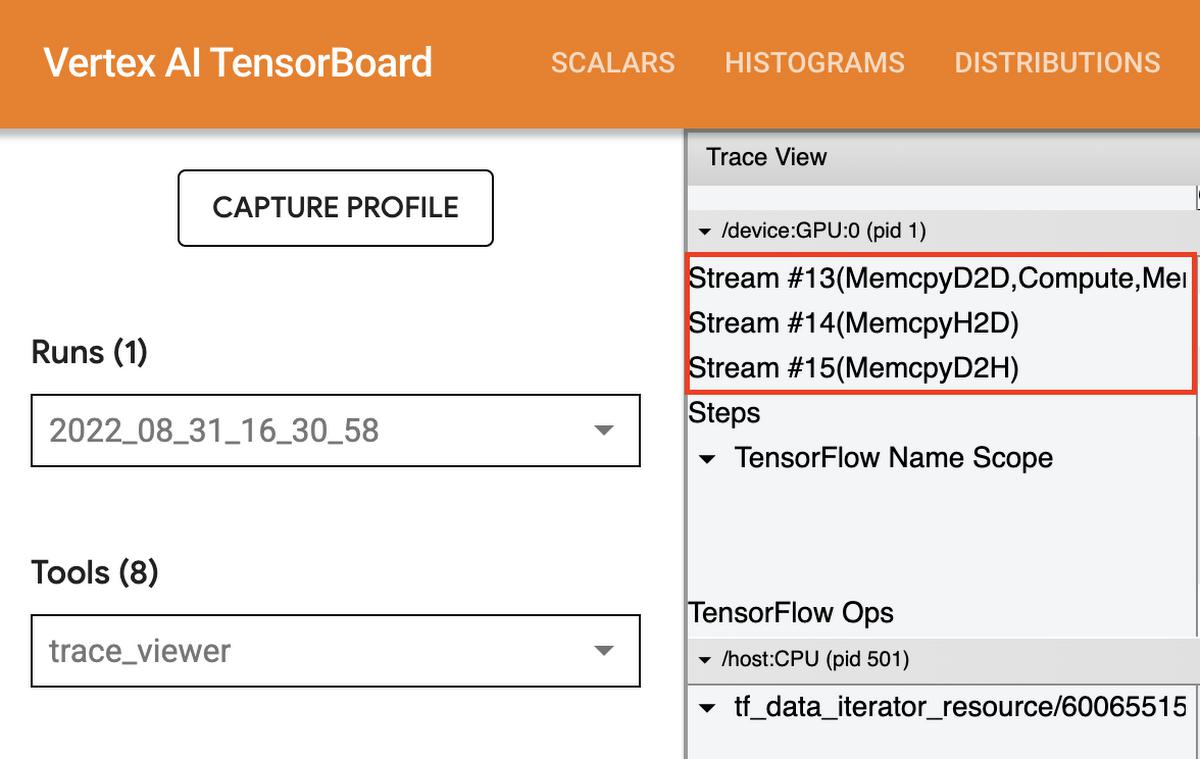
Trace viewer streams
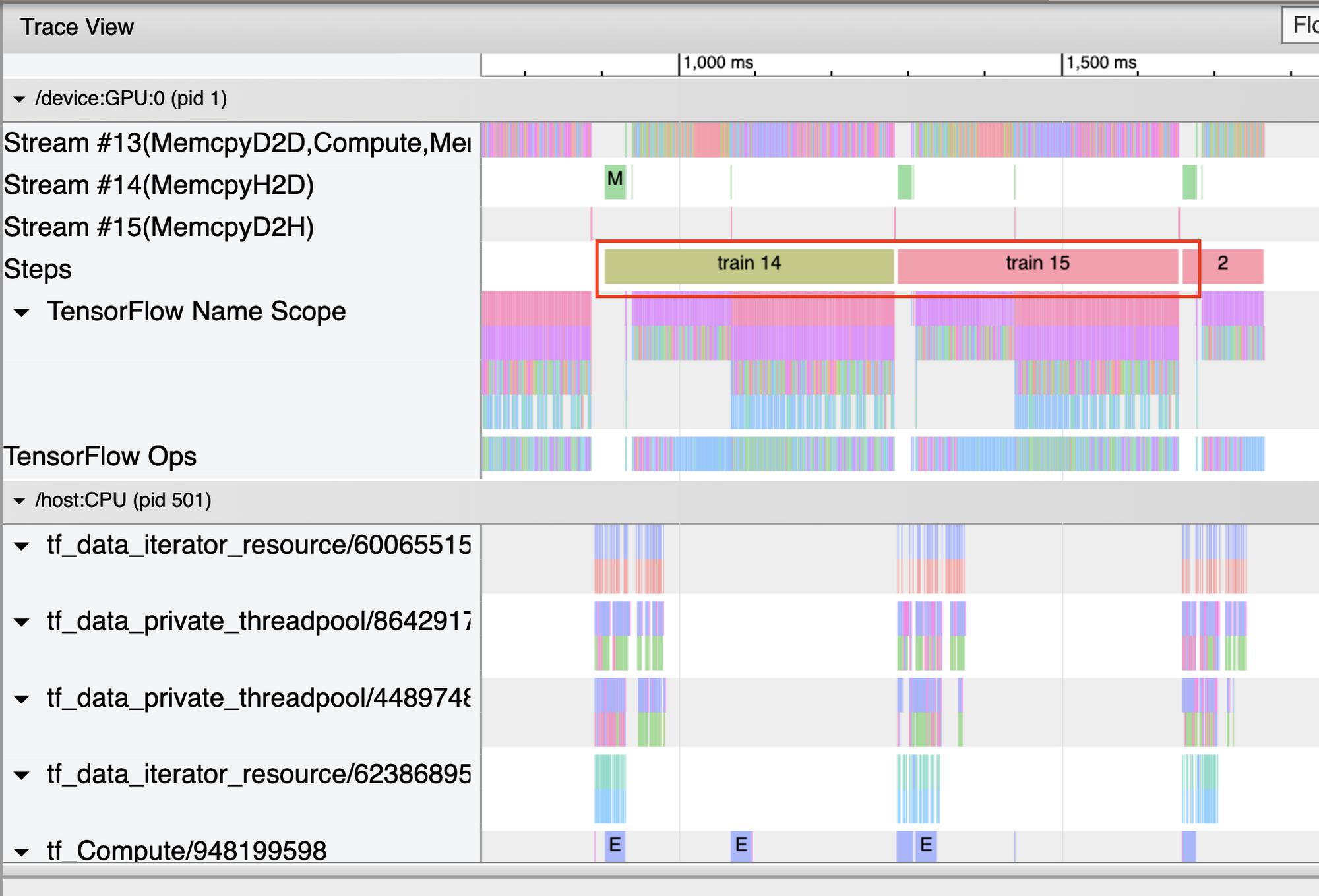
Trace viewer steps

Gap in steps
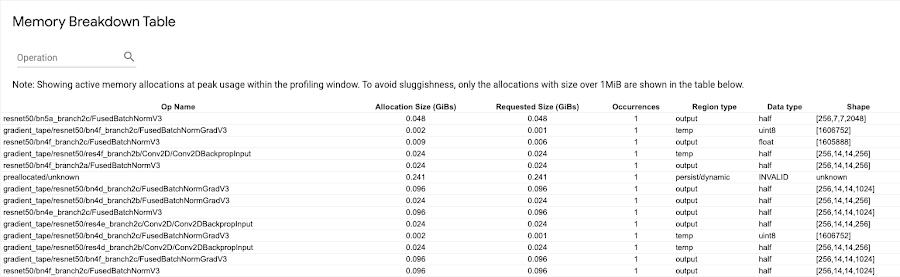
Memory breakdown table
You can check the GPU timeline in your program’s trace view for any unnecessary AllReduce calls, as this results in a synchronization across all devices. But you can also use the trace viewer to get a quick check as to whether the overhead of running a distributed training job is as expected, or if you need to do further performance debugging.
The time to AllReduce should be:
(number of parameters * 4bytes)/ (communication bandwidth)
Note that each model parameter is 4 bytes in size since TensorFlow uses fp32 (float32) to communicate gradients. Even when you have fp16 enabled, NCCL AllReduce utilizes fp32 parameters. You can get the number of parameters in your model from Model.summary.
If your trace indicates that the time to AllReduce was much longer than this calculation, that means you’re incurring additional and likely unnecessary overheads.
What’s next?
The TensorFlow Profiler is a powerful tool that can help you to diagnose and debug performance bottlenecks, and make your model train faster. Now you know five ways you can use this tool to understand your training performance. To get a deeper understanding of how to use the profiler, be sure to check out the GPU guide and data guide from the official TensorFlow docs. It’s time for you to profile some training jobs of your own!
By: Nikita Namjoshi (Developer Advocate) and Bruno Mendez (Software Engineer, GCP Cloud AI and Industry Solutions)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!






