Several social apps maintain feeds and allow users to upvote and share content through their social platforms. These votes and shares are tracked as “counters” in the backend database. This guide provides an array of choices to implement upvote and share counters using a Cloud Spanner database. This could be easily extended to track scores in a live game, managing inventory in retail, and several other applications across different industry verticals.
Cloud Spanner as a relational database provides SQL semantics to empower all these solutions. It is built for scale and provides built-in sharding capability for large-scale business applications that would normally encounter scaling limits. It also provides strong transactional consistency with applications handling inventory, accounting, and marketplaces.
From our partners:
Challenge
The social apps commonly have viral posts that cause users to upvote and/or share them millions of times within a short duration. This causes backend database overload for a small set of rows, caused by hotspotting. A hotspot is defined as a situation where too many requests are being sent to the same database row, saturating the resources of the server hosting the row and causing high end-user latencies.
A popular social app can have several thousand viral posts, and the upvotes on these can lead to overload behavior in the app and on its database. This can be seen in the form of read/write latencies and in the increased use of memory and CPU resources on the database.
Additionally, several social applications allow users to sort by popular posts, which requires fast read access and this can be built using an Index on these counters. Implementing these sorted reads creates additional performance load during writes. During Upvotes or Shares, a database write is translated into transactional update on the base table and counter index (which in case of Cloud Spanner is a multi-participant commit and may have lower performance) which adds further complexity to the system.
There are several different solutions that could be used to solve this problem, though each has a different requirement that would need to be relaxed.
Solutions
Legend

1. Read Modify Write
The database table could save the counters as part of the post metadata, colocated on the same table. The client application would perform a Read-Modify-Write transaction, i.e. it would read the current counter value from the post and update it with +1 value.
Every transaction updating a single counter is serialized one after another and the expected throughput will be a function of a single transaction latency.
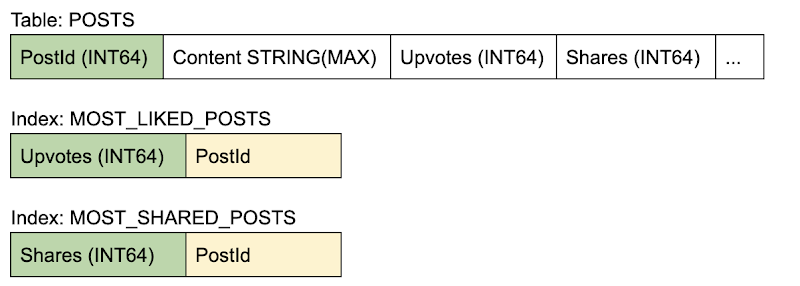
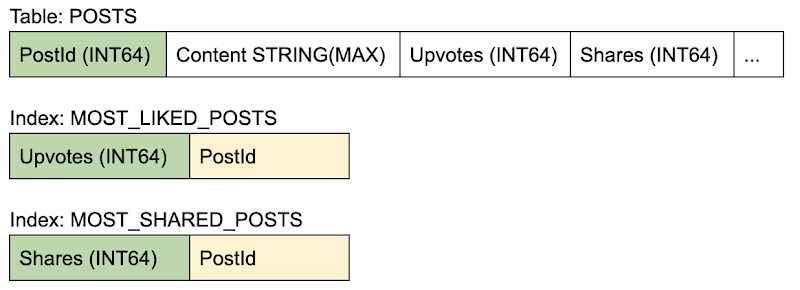
Schema
Advantages:
- This is the most straightforward and simple solution, both to develop and maintain. Most customer applications are built using this approach until they reach scaling limits.
- All reads for loading a post and its metadata are done on a single TABLE, and therefore incur no additional processing to gather data from multiple tables (as in a JOIN). Finding the post(s) with highest counter values can be directly scanned on the INDEX, with additional metadata (like author, date etc.) saved within the STORING clause.
- Also, the counters are already aggregated and therefore require no additional processing (like SUM(upvotes)).
- This provides the application with the latest counter values (strong consistency), i.e. there is no staleness in the counter values.
Disadvantages:
- This is inherently exposed to hotspotting, and high lock contentions causing the application to have lower throughput for both Read & Writes.
2. Sharded Counter
Database tables can save counters as part of an interleaved table. In Cloud Spanner, interleaved tables are co-located on the same split, and therefore read and write are faster than usual operation on two separate tables. This interleaved table will implement a sharded counter (i.e. multiple counter values spread across X rows). Depending on the expected write throughput, the value of X could be in the order of 10 – 100. An appropriate value can be determined by executing load tests and measuring latency across a fixed throughput benchmark.
For each write, a random row (using random number generator) in the interleaved table is incremented. As such without reads, the write throughput will linearly increase (with the number of shards) in this approach. Reads are however more expensive. For each read for the aggregated counter value, a sum (counters) across all rows on the interleaved table is performed. For high read throughput, customers should use (stale or strong) reads within a read-only transaction. Doing reads within read-write transactions may be significantly slower and may cause higher lock contention (with writers) with this approach.
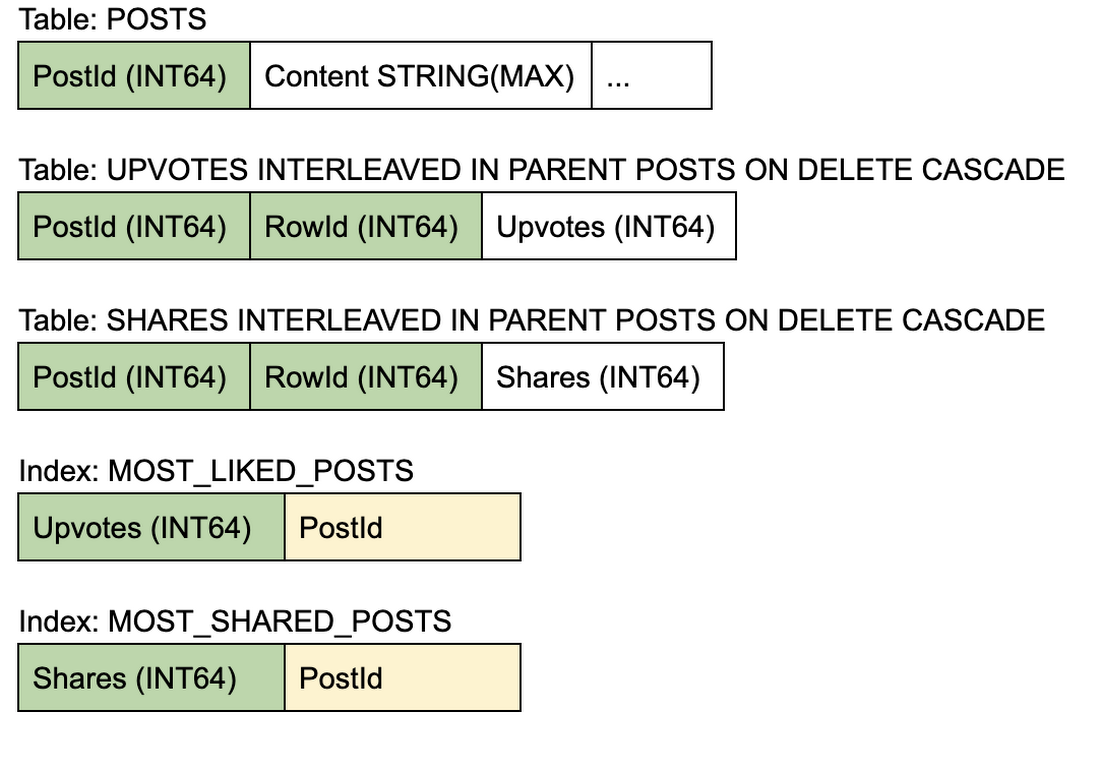
Schema
Advantages:
- Writes to increment the counter are now distributed across the X rows in the interleaved table. Therefore, there is a reduced chance for hotspotting. Also, if there are infrequent updates on the other post-metadata (i.e. in the parent POSTS table), writes into the interleaved counter tables only maintain a Reader-Shared lock on the parent row, which greatly improves read performance of the parent POSTS table.
- Reading the counters can be simply done using the SUM() function, and given the small size of the interleaved table, such reads will be very efficient to execute (with read-only transactions) for Cloud Spanner.
- This provides the application with the latest counter values (strong concurrency).
Disadvantages:
- If the read to write ratio of counters in transactions is high, this approach will not provide efficiency gains.
3. Blind Writes and periodic aggregation
Note: this solution is only suitable for a very high throughput application, expecting QPS in the order of ~100K per key.
The performance of all solutions discussed above is constrained by the Read-Modify-Write update semantics that internally maintains an exclusive lock on the post row and limits the read/write throughput on the counters. Those paradigms also increase lock-held duration due to network round-trip latencies of requests for read, write and eventually commit, which has the consequence of higher end-user latencies caused by lock contentions and higher rate of transaction ABORTs.
Cloud Spanner allows for Blind-Writes that do not take exclusive locks and can significantly improve throughput. Though using blind writes for maintaining counters require some sophisticated logic built at the client application layer and a more complex database schema.
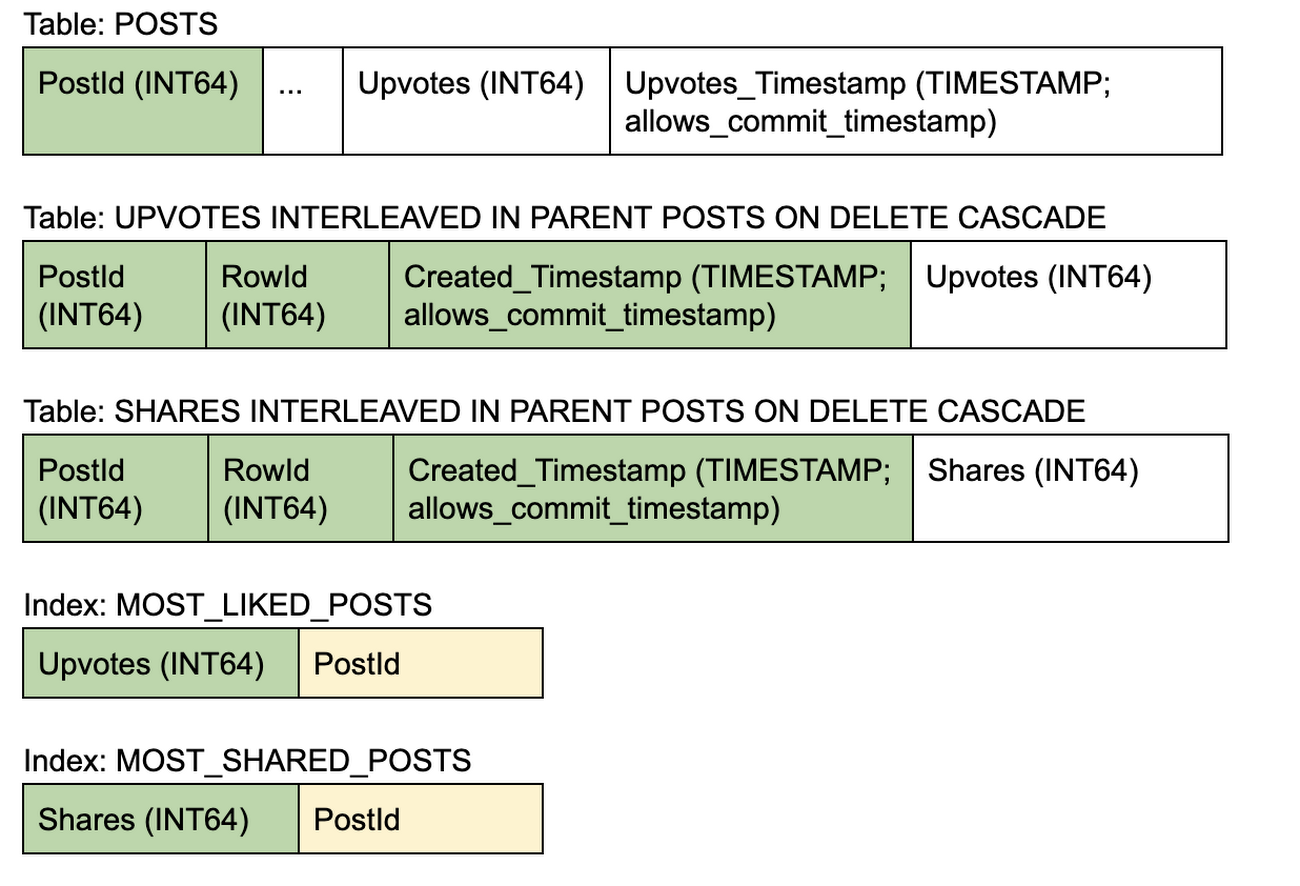
The parent table (i.e. POSTS) will save the aggregated counter value and a timestamp at which this was last aggregated (implemented using commit_timestamp). Each application ‘writes’ to update the counter value will only append a row within the specific counter interleaved table and a timestamp. Periodically, these transactions will sum all counters from the interleaved table since the last aggregated timestamp and update the parent row. It can optionally purge the interleaved rows thereafter or apply the Spanner’s TTL policy.
Each read will have to read the aggregated value from the parent table and count the rows in the interleaved table (since the last aggregated timestamp) to find the latest counter value.
Schema
4. Caching
Note: this solution is suitable for applications that do not rely on strong transactional consistency of the counters. The recommendation of a cache as an aggregation layer is to reduce the total number of writes to Spanner to achieve higher throughput.
The client application layer could cache these counters on an intermediate layer (like Cloud Memorystore), and update them periodically (in the background) into the database. Sophisticated implementations could use a distributed cache to read and write these counters simultaneously.
Implementing write-back cache will improve application write throughput. The main advantage is to aggregate multiple writes into a single write into Spanner. This paradigm comes with the cost of stale Spanner data (until the async writes are done).
Schema
Advantages:
- Caches have lower latencies on Read-Modify-Write operations and they guarantee ACID properties.
- This would improve Read & Write throughput on the client application.
Disadvantages:
- Additional infrastructure for a caching layer to be built and maintained.
- All reads need to go to the cache as the database may be stale.
- Data durability will be a concern for non-durable caches.
What’s next?
Cloud Spanner offers a scalable solution for all customer application sizes. To read more about Spanner’s read and write transactions, see this documentation. To get started on Cloud Spanner, try a quick tutorial.
By Sneha Shah, Senior Software Engineer
Originally published at Google Cloud
Source: Cyberpogo
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







