
Getting started with any machine learning project often starts with the question: “How much data is enough?”. The response depends on several factors like the diversity of production data, the availability of open-source datasets, the expected performance of the system, and the list can go on for quite a while. In this article, I’d like to debunk a popular myth about machines only learning from large amounts of data, and share a use case of applying ML with a small dataset.
With the rapid adoption of deep learning in computer vision, there are more and more diverse tasks needed to be solved with the help of machines. To understand machine learning applications in the real world, let’s focus on the task of object detection.
From our partners:
What is Object Detection?
Object detection is a branch of computer vision that deals with identifying and locating objects in a photo or video. The goal of object detection is to find objects with certain characteristics in a digital image or video with the help of machine learning. Often, object detection is a preliminary step for item recognition: first, we have to identify objects and then apply recognition models to identify certain elements.
Object Detection Business Use Cases
Object detection is a core task of AI-powered solutions for visual inspection, warehouse automation, inventory management, security, and more. Below are some object detection use cases that are successfully implemented across industries.
Manufacturing. Quality assurance, inventory management, sorting, and assembly line – object detection plays an important role in the automation of many manufacturing processes. Machine learning algorithms allow to quickly detect any defects, automatically count and locate objects. This allows them to improve inventory accuracy by minimizing human error and the time spent.
Automotive. Machine learning is used in self-driving cars, pedestrian detection, and optimizing traffic flow in cities. Object detection is used to perceive vehicles and obstacles surrounding the driver. In transportation, object recognition is used to detect and count vehicles. It’s also used for traffic analysis and helps to detect cars that stop on highways or crossroads.
Retail. Object detection helps detect SKUs (Stock Keeping Units) by analyzing and comparing shelf images with the ideal state. Сomputer vision techniques integrated into hardware help reduce waiting time in retail stores, track the way customers interact with the products, and automate delivery.
Healthcare. Object detection is used for studying medical images like CT scans, MRIs, and X-rays. It’s used in cancer screening, helping to identify high-risk patients, detect abnormalities and even provide surgical assistance. Applying object detection and recognition to assist with medical examinations for telehealth is a new trend set to change the way healthcare is delivered to patients.
Safety and surveillance. Among the applications of object detection are video surveillance systems capable of people detection and face recognition. Using machine learning algorithms, such systems are designed for biometric identification and remote surveillance. This technology has even been used for suicide prevention.
Logistics and warehouse automation. Object detection models are capable of visual inspection for defect detection, inventory management, quality control, and automation of supply chain management. AI-powered logistics solutions use object detection models instead of barcode detection, thus replacing manual scanning.How to Develop an Object Detection System: the PoC Approach
Developing an object detection system to be used for tasks similar to the ones we mentioned above is no different from any other ML project. It usually starts with building a hypothesis to be checked during several rounds of experiments with data.
Such a hypothesis is a part of the PoC approach in software development. It aligns with machine learning, as in this case, the delivery is not an end product. Running research allows us to come up with results that will allow us to say either chosen approach could be used or there’s a need to run extra experiments to choose a different direction.
If the question is “how much data is enough for machine learning”, the hypothesis may sound like “150 data samples are enough for the model to reach an optimal level of performance”.
Experienced ML practitioners such as Andrew Ng (co-founder of Google Brain, ex-Chief Scientist at Baidu) recommend building the first iteration of the system with machine learning functionality quickly, then deploying it and iterating from there.
This approach allows us to create a functional and scalable prototype system that can be upgraded with the data and feedback from the production team. This solution is far more efficient compared to the situation where you would try to build the final system from the get-go. A prototype like this does not necessarily require large amounts of data.
To answer the “how much data is enough” question, it’s absolutely true that no machine learning expert can predict how much data is needed. The only way to find out is to set a hypothesis and test it on a real case. This is exactly what we’ve done with the following object detection example.
Case Study: Object Detection Using Small Dataset for Automated Items Counting in Logistics
Our goal was to create a system capable of detecting objects for logistics. Goods transportation from production to a warehouse or from warehouse to facilities often requires intermediate control and coordination of the actual quantity with invoices and a database. When done manually, this task would require hours of human work and involves high risks.
Speaking of the hypothesis, ours was to check if a small annotated dataset is enough to address the issue of automatically counting various items for logistics purposes.
The typical approach to the problem that many would choose is using classic Computer Vision techniques. For instance, one might combine Sobel filter edge detection and Hough circle transform methods to detect and count round objects. The method is simple and relatively reliable, however, it is more suitable for a controlled environment, such as a production line with objects having a well-defined round or oval shape.
In the use case we selected, the classical methods are far less reliable since the shape of the objects, quality of the images, as well as lighting conditions, can vary greatly. Furthermore, the classical methods cannot learn from the data. This makes it difficult to iterate over the system by collecting more data. In this case, the best option would be to fine-tune a neural network-based object detector.
Data Collection and Labeling
To perform an experiment of object detection with a small dataset, we collected and manually annotated several images available in public sources. We decided to focus on the detection of wood logs and divided the annotated images into train and validation splits.
We additionally gathered a set of test images without labels where the logs would be in some way different from the train and validation images (orientation, size, and shape of logs, color) to see where the limit to the model’s detection capabilities would be given the train set.

In object detection, the quantity of data is determined not just by the number of images in the dataset, but also by the number of individual object instances in each image. In our case, the images were quite densely packed with objects – the number of instances reached 50-90 per image.
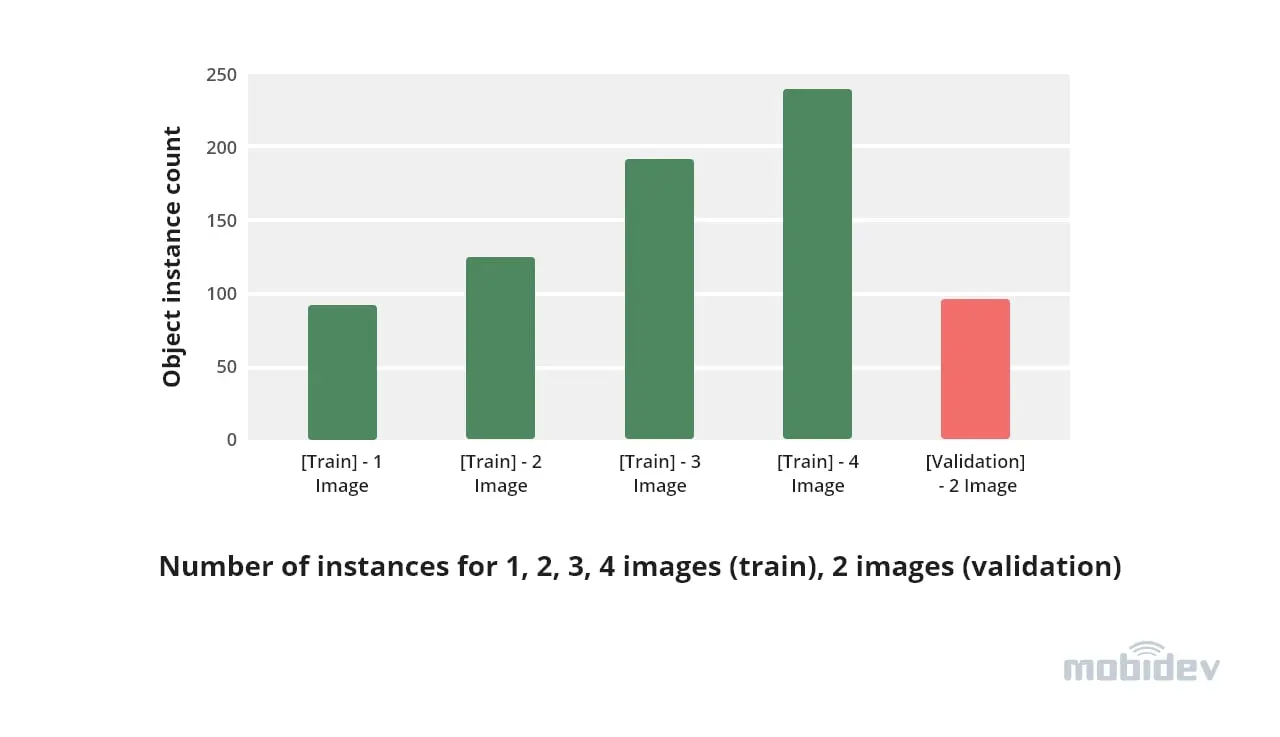
Detectron2 Object Detection
The model we decided to use was an implementation of Faster R-CNN by Facebook in a Computer Vision library Detectron2.
Let’s have a closer look at how Faster R-CNN works for object detection. First, an input image is passed through the backbone (a deep CNN model pre-trained on image classification problem) and is converted into a compressed representation called feature maps. Feature maps are then processed by the Region Proposal Network (RPN) that identifies areas in the feature maps that are likely to contain an object of interest.
Next, the areas are extracted from the feature maps using RoI pooling operation and processed by bounding box offset head (predicts accurate bounding box coordinates for each region) and object classification head (predicts the class of the object in the region).
Faster R-CNN (Region-based Convolutional Neural Network) is the 3rd iteration of R-CNN architecture.
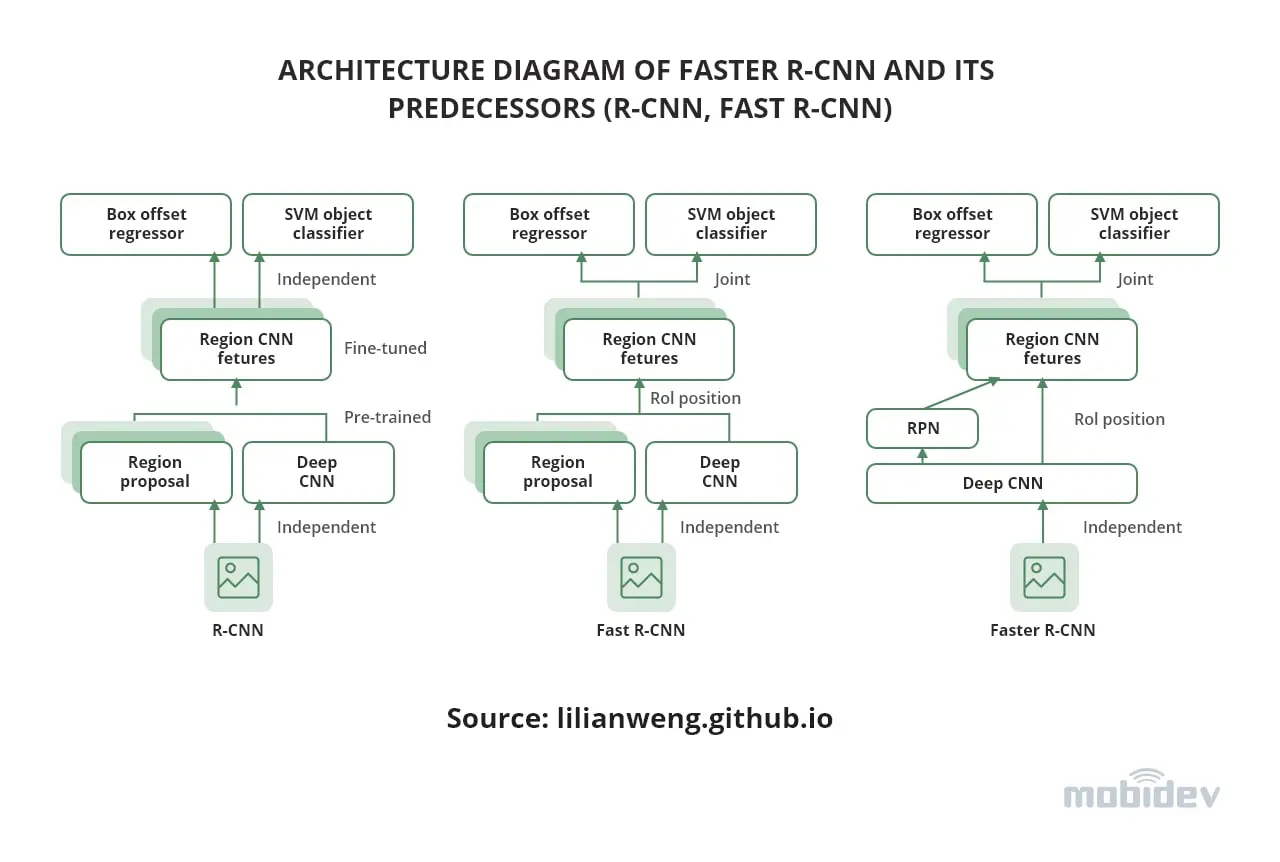
Faster R-CNN is a two-stage object detection model. It includes the RPN sub-network to sample object proposals. However, this is not the only solution to the small dataset for object detection.
There are one-stage detector models attempting to find the relevant objects without this repion proposal screening stage. One-stage detectors have simpler architectures and are typically faster but less accurate compared to two-stage models. Among the examples are Yolov4 and Yolov5 architectures, – some of the lighter configured models from these families can reach up to 50-140 FPS (although compromising the detection quality) while Faster R-CNN runs at 15-25 FPS at maximum.
The original paper on Faster R-CNN explained was published in 2016 and from there received some small improvements to the architecture, which were reflected in the Detectron2 library that we used.
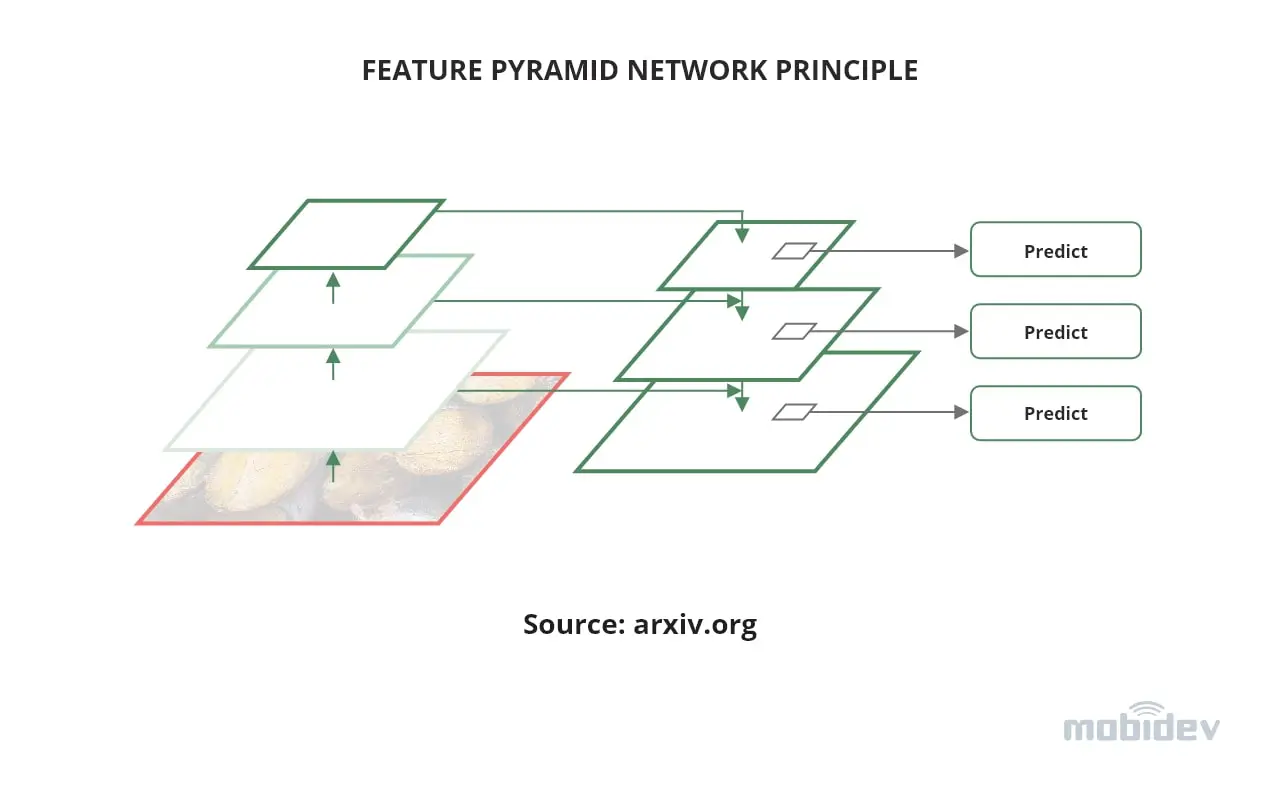
For example, the selected for our experiments model config R50-FPN uses backbone ResNet-50 with Feature Pyramid Network – a concept that was introduced in the CVPR 2017 paper and since then has become a staple of CNN backbones for feature extraction. In simpler terms, in Feature Pyramid Networks we use are not just the deepest feature maps extracted from CNN but also low- and medium-level ones. This allows small object detection that would be otherwise lost during the compression down to the deepest levels.
Results
In our experiments, we used the following logic:
- Take a Faster R-CNN pre-trained on COCO 2017 dataset with 80 object classes.
- Replace 320 units in bounding box regression and 80 units in classification heads with 4 and 1 units respectively, to train the model for 1 novel class (bounding box regression head has 4 units for each class to regress X, Y, W, H dimensions of bounding box where X, Y are the center coords of the bbox center and W, H are its width and height).
After some preliminary runs we picked the following training parameters:
- Model config: R50-FPN
- Learning rate: 0.000125
- Batch size: 2
- Batch size for RoI heads: 128
- Max iterations: 200
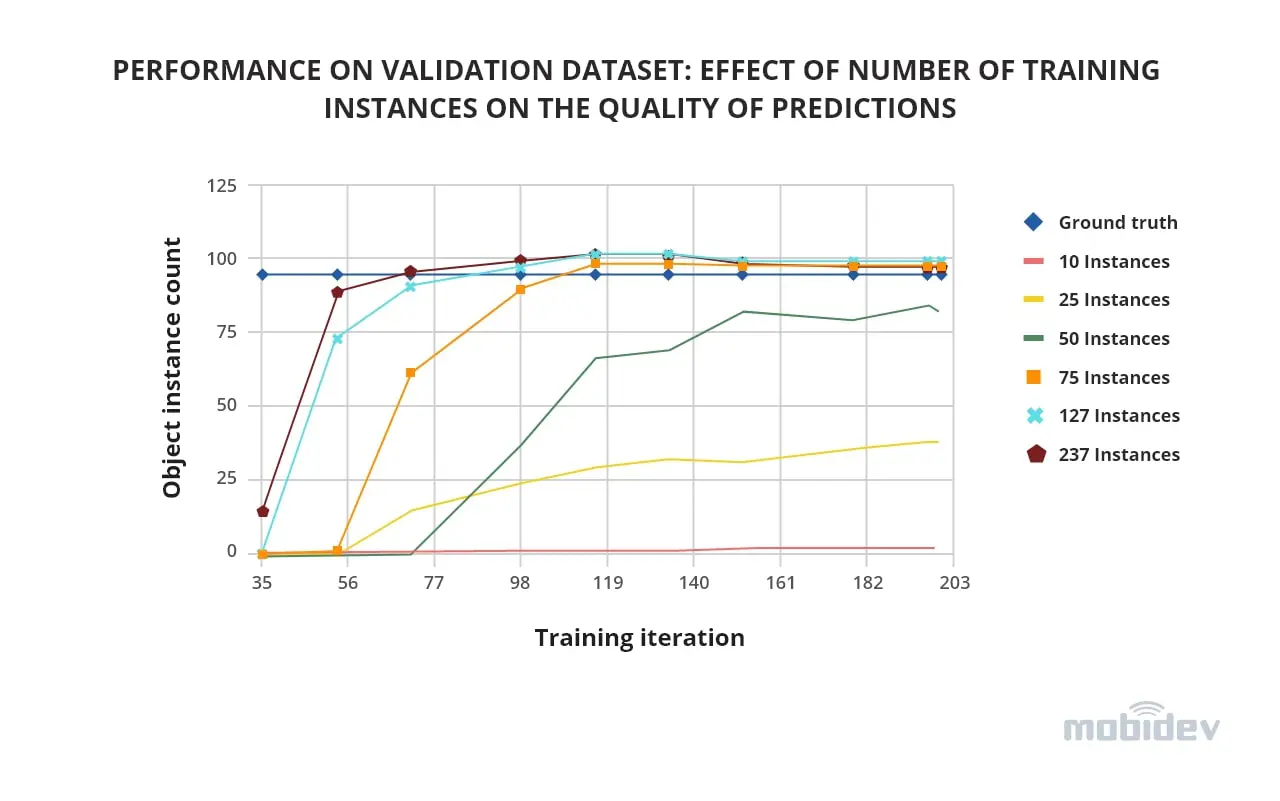
With the parameters set, we started looking into the most interesting aspect of training: how many training instances were needed to obtain decent results on the validation set. Since even 1 image contained up to 90 instances, we had to randomly remove part of the annotations to test a smaller number of instances. What we discovered was that for our validation set with 98 instances, at 10 training instances we could pick up only 1-2 instances, at 25 we already got ~40, and at 75 and higher, we were able to predict all the instances.
Increasing the number of training instances from 75 to 100 and 200 led to the same final training results. However, the model converged faster due to the higher diversity of the training examples.
Predictions of the model trained with 237 instances on the image from the validation set can be seen in the image below; there are several false positives (marked by red arrows) but they have low confidence and thus could be mostly filtered out by setting the confidence threshold at ~80%.
At the next step, we explored the performance of the trained model on the test images without labels. As expected, images similar to the train set distribution had confident and high-quality predictions. Whereas the images where the logs had an unusual shape, color, or were differently oriented were much tougher for the model to work with.

However, even on the challenging images from the test set, we observed a positive effect from increasing the number of training instances. In the image below we show how the model learns to pick up additional instances (marked by green stars) with the increase in the number of train images (1 train image – 91 instances, 2-4 images – 127-237 instances).

To sum up, the results showed that the model was able to pick up ~95% of the instances in the validation dataset. After fine-tuning with 75-200 objects instances provided validation data resembled the train data. This proves that selecting proper training examples makes quality object detection possible in a limited data scenario.
Future of Object Detection
Object detection is one of the most commonly used computer vision technologies that has emerged in recent years. The reason for this is versatility. Some of the existing models are successfully implemented in consumer electronics or integrated into driver-assistance software. Others are the basis for robotic solutions used to automate logistics and transform healthcare and manufacturing.
The task of object detection is essential for digital transformation, as it serves as a basis for AI-driven software and robotics, which in the long run means we can gradually free people from performing tedious jobs and mitigate multiple risks.
Written by Maksym Tatariants, AI Solution Architect at MobiDev
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!






