
This blog is intended for customers who have migrated on-premises data sources to Google Cloud VMware Engine and want to utilize data and analytics services provided by Google Cloud. One of the objectives of customers who choose Google Cloud is to leverage Google Cloud analytics with their datasets. If you are an IT decision maker or a data architect who wants to quickly use the power of your data with Google analytics, this blog describes approaches to access your data within BigQuery, where advanced analytics and machine learning on your datasets is possible.
Why?
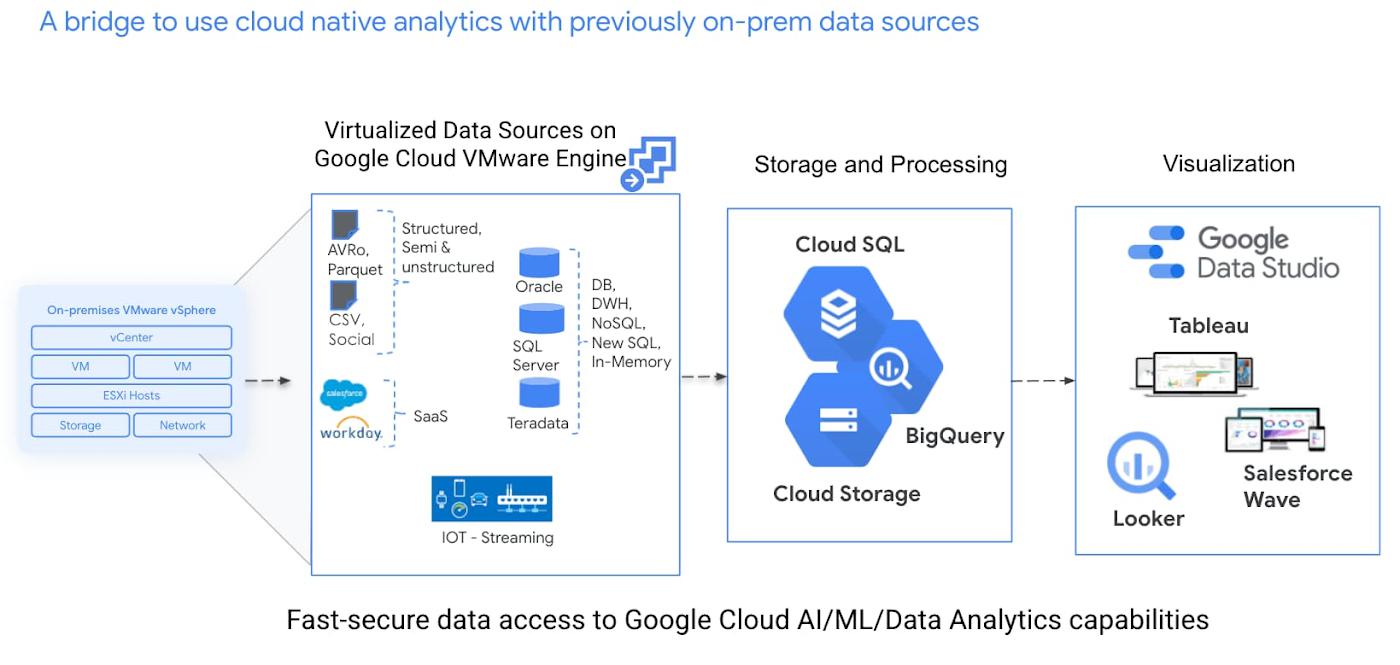
Data consumption and analytics is at the forefront of technology. Customers today consume and manage large amounts of data and resource pools. These challenges create an opportunity for Google Cloud to assist in managing and understanding your existing databases without having the need to undergo costly re-architecting of your source material or data location. This blog presents approaches to access Google Cloud data and analytics services with your existing data without having to re-architect your databases. Once your data sources are in Google Cloud VMware Engine, Google’s highly available and fault tolerant infrastructure can be leveraged to enhance the performance of data pipelines. These solutions aim to reduce time to value extraction from your datasets with cloud native analytics available via BigQuery.
From our partners:
This solution of migrating via Google Cloud VMware Engine offers advantages to all parts of data operations. The database administrator (DBA) and virtual infrastructure/cloud admins can use familiar environments similar to on-premises on the cloud. The on-premises infrastructure team can enable the data scientist/AI/machine learning (ML) teams using familiar toolsets. These teams now have access to Google Cloud AI/ML/data analytics capabilities for their on-premises data.

For example, if you want to uncover cross-sell opportunities within your products, the first step is to ensure that product usage and billing datasets across your products are connected for analytics. The DBA team will identify these datasets and the infrastructure team will enable access to these sources. The application team will then replicate this data to BigQuery and use approaches such as BigQuery ML recommendations to uncover cross-sell opportunities. Another example of a use case is forecasting usage growth for operations and growth planning. Once your sales data is replicated within BigQuery, approaches for advanced time-series forecasting become available with your datasets.
What does this cover?
We present approaches to replicate your relational datasets within BigQuery in a private and secure way utilizing either Google Cloud Data Fusion or Google Cloud Datastream. Datafusion is an ETL tool that supports various kinds of data pipelines. Datastream is a service for change-data-capture and replication. Using both these services, data is always within your projects in Google Cloud and internal IP is used to access data. We will focus on real-time replication, so that you can access your data continuously from operational data stores, such as SQL Server, MySQL, and Oracle within BigQuery.
Moving data from your data sources to the cloud and maintaining data pipelines to your data warehouses via Extract Transform Load (ETL) is a time consuming activity. An alternate approach is ELT (Extract Load Transform). The ELT approach loads data into the target system (e.g., BigQuery) before transforming the data. The ELT process is frequently preferred over the traditional ETL process because it’s simpler to realize and loads the data faster.
With your datasets now residing in the Google Cloud, data teams can utilize Cloud Data Fusion and Datastream over the high speed, low latency Google Cloud network to replicate or move data from your VMware infrastructure to various destinations in Google Cloud such as Google Cloud native storage buckets or BigQuery.
For simplicity, we will assume that all services are consumed within the same project. We will also discuss some pricing implications when moving data from Google Cloud VMware Engine from on-premises or another virtual private cloud (VPC).


Cloud Data Fusion:
Cloud Data Fusion provides a visual point-and-click interface that enables code-free deployment of ETL/ELT data pipeline. Cloud Data Fusion also provides a replication accelerator that allows you to replicate your tables into BigQuery.
Cloud Data Fusion internally sets up a tenant project with its own VPCs to manage Cloud Data Fusion resources. To access data sources within Google Cloud VMware Engine using Cloud Data Fusion, we use a reverse proxy on the main VPC. This is described in the image below.
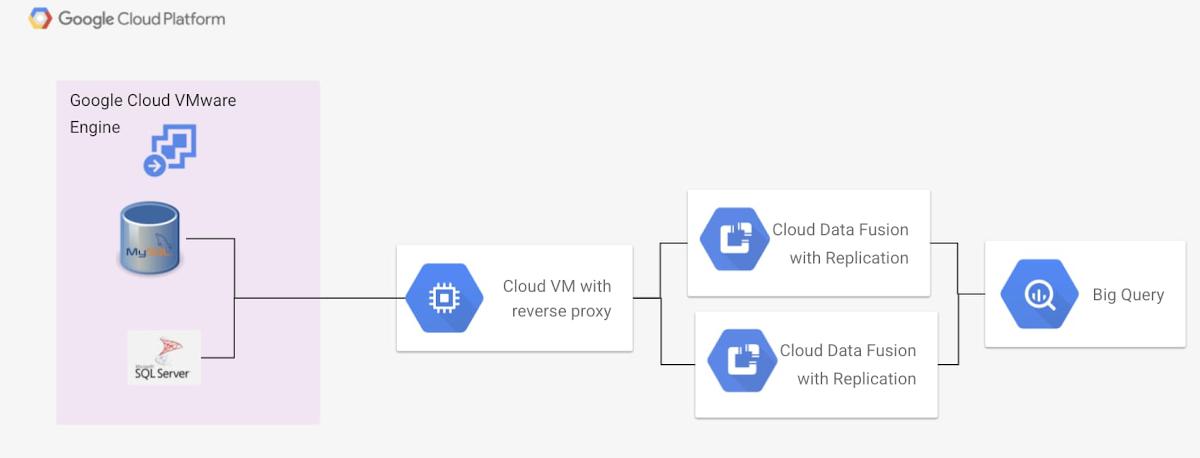
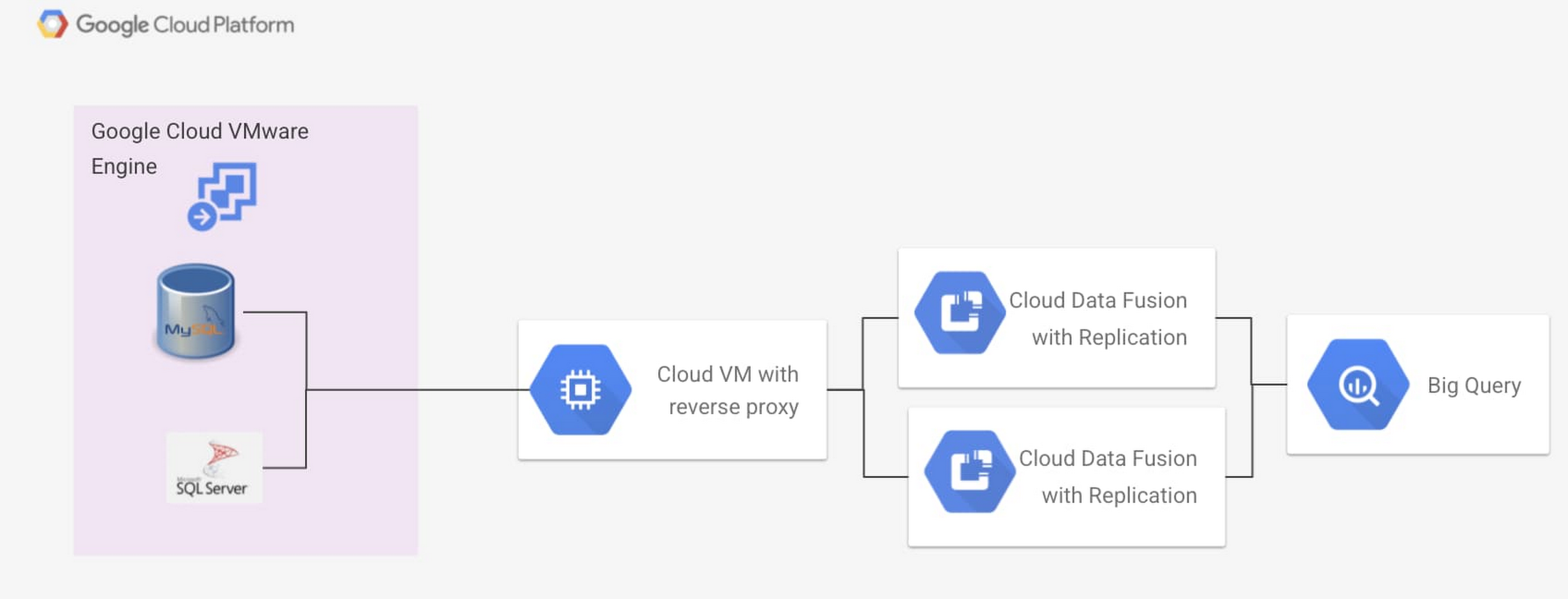
In this scenario, we have our data workloads running on the Google Cloud VMware Engine instance within the project. The Google Cloud VMware Engine environment is accessed via a project level VPC peered with Google Cloud VMware Engine. A Google Compute Engine instance on the project level VPC exposes reverse proxy to the Google Cloud VMware Engine database to services that are unable to access the Google Cloud VMware Engine instance directly. A Cloud Data Fusion instance is enabled with private IP access and network peering to the main VPC and is able to access the data via the reverse proxy instance. This process to set up internal IP access and network peering on Cloud Data Fusion is described in this documentation.
Once this peering is complete, we use a Java Database Connectivity connector within Cloud Data Fusion to access our databases either for replication or for advanced ETL operations. To enable change data capture, we need to enable the database within Google Cloud VMware Engine to track and capture the changes to the databases. This entire process setup and replication are described in the documentation for MySQL and for SQL Server.
Google Cloud Datastream:
Datastream is a serverless change data capture and replication service. You can access streaming, low-latency data from Oracle, and MySQL databases on Google Cloud VMware Engine. This approach offers more flexibility in managing data flow pipelines. This solution is currently in pre-general availability and is only available in select regions.
This option also requires a reverse proxy configured within a Google Compute Engine instance. This reverse proxy is used to access data sources within Google Cloud VMware Engine. This option is described in this documentation.
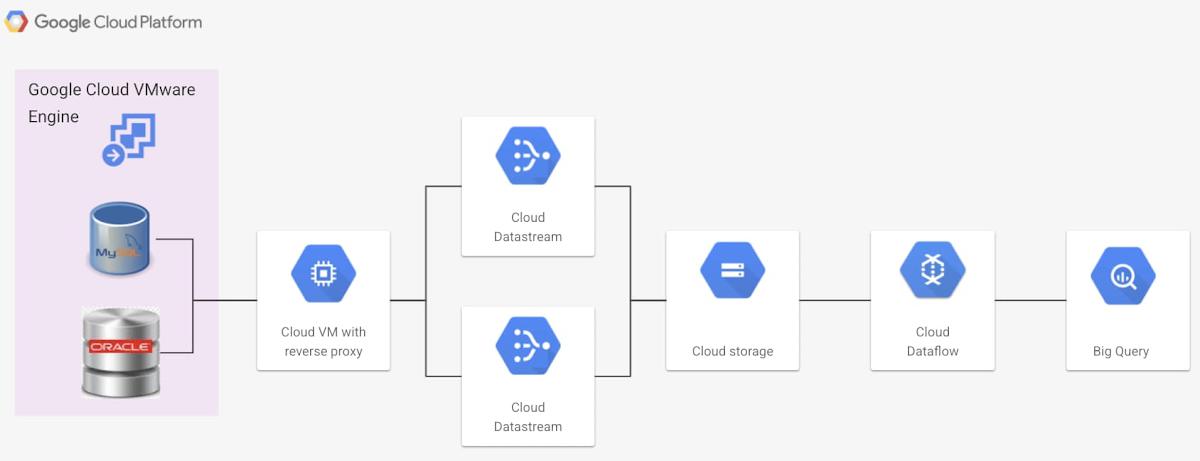
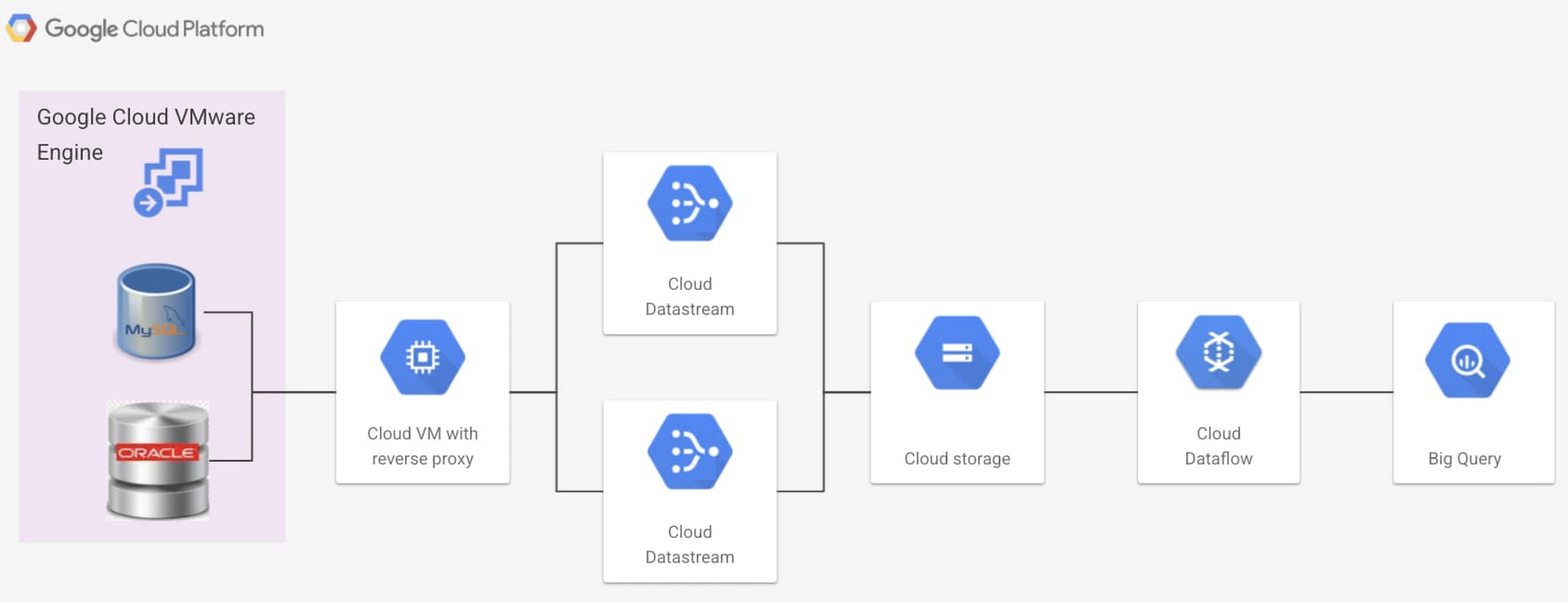
The complete setup to use Datastream can be found in this how-to guide. To enable replication, we need a stream configured on Datastream, this stream accesses data from the database and pipes the data to the cloud storage sink. Datastream accesses data using a reverse proxy which needs to be exposed on the customer’s VPC. To pipe the data to BigQuery, we use a pre-configured Datastream to BigQuery template within Dataflow.
How to get started?
First step is to migrate workloads to Google Cloud VMware Engine. Your cloud admin/architect will typically drive this. If not already identified during the migration phase, the next step is to identify databases residing on virtual machines hosted within Google Cloud VMware Engine, and recreate existing reports using BigQuery. In most organizations there will be multiple personas involved with this process. For example, a data architect might be the best source for info on data sources, a solutions architect will have insights on the cost/performance implications, and the infrastructure inputs will be needed for network interfaces. The steps below outline one possible approach to enable this motion.
- Identify datasets residing on virtual machines migrated to Google Cloud VMware Engine that are used for reports.
- Select the right pipeline (Datastream vs. Data Fusion) based on the database type and the pipeline requirements (price/performance trade offs and ease of use).
- Based on the data pipeline, select the appropriate region. There are no data egress charges within the same region.
- Setup the reverse proxy to the Google Cloud VMware Engine dataset.
- Setup the replication service with performance parameters based on the replication performance needed.
- Enable analytics and visualization based on the business requirements on the dataset.
Conclusion:
The Google Cloud VMware Engine service is a fast and easy way to enable data and analytics visualization using your existing data sets. You can now leverage your existing infrastructure operational posture on VMware to enable cloud analytics without having to undergo time consuming re-architecting of your databases. These approaches enable you to leverage the performance benefits of dedicated hardware on Google Cloud, connecting with the world’s most advanced data capabilities.
Acknowledgements:
The authors would like to thank Manoj Sharma and Sai Gopalan regarding their inputs on this blog.
By: Nitish Murthy (Product Manager, Google Cloud) and Wade Holmes (Solutions Manager – VMware-aaS Global Lead)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







