Thirty five years ago, SQL-86, the first SQL standard, came into our world, published as an ANSI standard in 1986 and adopted by the International Standards Organization (ISO) in 1987. On this Valentine’s Day, we, in BigQuery, reaffirm our love and commitment to user-friendly SQL through a whole slew of new SQL features that we’re pleased to share with you, our beloved BigQuery users.
Expanded Datatypes
INTERVAL datatype
They say time and tide wait for no man. Now, thanks to the <a href="https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#interval_type" target="_blank" rel="noopener">INTERVAL</a> data type, you can measure the duration of time within BigQuery. This datatype allows you to save the difference between a start and an end timestamp in a native datatype in units ranging from years to fractions of a second with sign.
From our partners:
#This example creates and queries a table with a column of INTERVAL type.CREATE TABLE dataset.table(i INTERVAL) AS (SELECT * FROM UNNEST([INTERVAL 3 DAY,INTERVAL 2 MONTH,INTERVAL -2 MONTH,INTERVAL 5 MINUTE,INTERVAL 3 DAY + INTERVAL 1.234 SECOND]));SELECT * FROM dataset.table;#you can now add or subtract INTERVAL data from a DATE or DATETIME object to perform calendar arithmetic.SELECT DATETIME ‘2021-06-01 04:00:00’ + iFROM dataset.table;
Change column datatype
In a prior BigQuery user-friendly SQL update, we announced support for parameterized datatypes in BigQuery. Building on this, BigQuery now support the ability to change the datatype of an existing column to make it less restrictive. Using the SET DATA TYPE clause, a NUMERIC data type can be changed to a BIGNUMERIC type or the length or precision & scale of a parameterized datatype column can be increased. For a table of valid data type coercions, compare the “From Type” column to the “Coercion To” column in the Conversion rules in Standard SQL page.
# The following example changes the data type of column c1 from an INT64 to NUMERIC:CREATE TABLE dataset.table(c1 INT64);ALTER TABLE dataset.table ALTER COLUMN c1 SET DATA TYPE NUMERIC;# The following example changes the data type of one of the fields in the s1 column:CREATE TABLE dataset.table(s1 STRUCT<a INT64, b STRING>);ALTER TABLE dataset.table ALTER COLUMN s1SET DATA TYPE STRUCT<a NUMERIC, b STRING>;# The following example changes the precision of a parameterized data type column:CREATE TABLE dataset.table (pt NUMERIC(7,2));ALTER TABLE dataset.tableALTER COLUMN ptSET DATA TYPE NUMERIC(8,2);
To learn about the new JSON data type, read Announcing preview of BigQuery’s native support for semi-structured data.
Expanded SQL Expressions and Scripting Control Statements
WITH RECURSIVE common table expression
A common table expression (CTE) referenced using a WITH clause in a query allow the user to break up a complex query by allowing a temporary table containing the results of the CTE subquery which can then be referenced in other parts of the same query as a table. A recursive CTE referenced using a WITH RECURSIVE clause containting a UNION ALL operation has the following parts:
- base_term: Runs the initial iteration of the recursive operation.
- recursive_term: Runs the remaining iterations until the recursion terminates.
- union_operator: The UNION operator returns the rows that are from the union of the base term and recursive term.
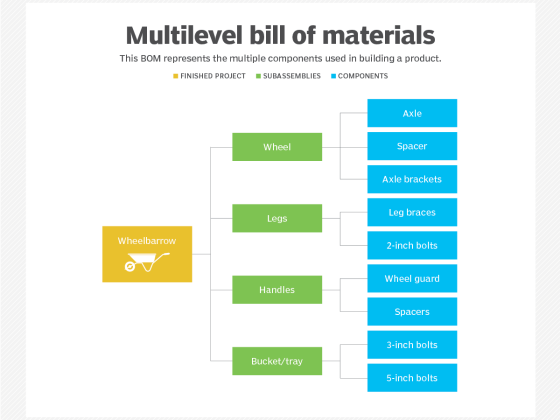
Recursive CTEs can be very useful in querying hierarchical data in tables, such as an employee and their supervisor of a large multi-level organization or the bill-of-materials of a complex product defined by its subcomponents and their associated parts.
# The most common use case for WITH RECURSIVE is querying hierarchy data,# where there are some relations among the rows of the table.WITH RECURSIVE# Below is a regular CTE which contains two columns:# employee_name and manager_name,# one employee can only have one manager.EmployeeInfo AS (SELECT 'Thomas' AS employee_name, 'Alex' AS manager_name UNION ALLSELECT 'Jim', 'Alex' UNION ALLSELECT 'Nikola', 'Thomas' UNION ALLSELECT 'John', 'Thomas' UNION ALLSELECT 'Isaac', 'Jim' UNION ALLSELECT 'Carl', 'Nikola' UNION ALLSELECT 'Will', 'Nikola' UNION ALLSELECT 'Lucy', 'John' UNION ALLSELECT 'Charles', 'Carl' UNION ALLSELECT 'James', 'Will' UNION ALLSELECT 'Amanda', 'Lucy'),# Below is a recursive CTE which contains all the people# that directly or indirectly report to Thomas.ThomasReports AS(# Below is the base term, which contains all the people# that directly report to Thomas.SELECT employee_name FROM EmployeeInfo WHERE manager_name = 'Thomas'UNION ALL# Below is the recursive term, which recursively includes# those people that directly report to Thomas's known reports.SELECT e.employee_name FROM EmployeeInfo AS e JOIN ThomasReports AS t on e.manager_name = t.employee_name)# output the total number of Thomas's reportsselect COUNT(*) AS total from ThomasReports
Control statements in Scripting
As business logic to analyze data becomes more complex, control statements in scripting allow data analysts to apply conditional logic to execute different workflows based on specific conditions encountered during script execution. BigQuery is pleased to support the following additional control statements in scripting:
<a href="https://cloud.google.com/bigquery/docs/reference/standard-sql/scripting#for-in" target="_blank" rel="noopener">FOR…IN</a>: loops over every row in a table expression. This offers a succinct way to iterate through query results that other loops do not.<a href="https://cloud.google.com/bigquery/docs/reference/standard-sql/scripting#repeat" target="_blank" rel="noopener">REPEAT</a>: repeatedly executes a list of SQL statements until the boolean condition at the end of the list isTRUE<a href="https://cloud.google.com/bigquery/docs/reference/standard-sql/scripting#case" target="_blank" rel="noopener">CASE</a>: Provides a more efficient SQL expression to execute conditional logic that previously supportedIF…ELSE IFstatements. It executes the first list of SQL statements where a boolean expression isTRUE.<a href="https://cloud.google.com/bigquery/docs/reference/standard-sql/scripting#case_search_expression" target="_blank" rel="noopener">CASE <i><search expression></i></a>: TheCASEstatement with the search expression executes the first list of SQL statements where the search expression matches aWHENexpression.<a href="https://cloud.google.com/bigquery/docs/reference/standard-sql/scripting#labels" target="_blank" rel="noopener">Labels</a>: provides an unconditional jump to the end of the block or loop associated with a label. With labeledBREAKorCONTINUE, users now have more control over nested loops or statement bodies by skipping to specific (named) locations in the script instead of continuing with sequential execution.
# Example using FOR…INFOR record IN(SELECT word, word_countFROM bigquery-public-data.samples.shakespeareLIMIT 5)DOSELECT record.word, record.word_count;END FOR;
Table copy DDL
CREATE TABLE LIKE and COPY
Analysts and data engineers often need to make a copy of a table schema (without data) or a full table copy (with data) from a production into a test or development environment. The CREATE TABLE LIKE statement copies only the metadata of the source table while the CREATE TABLE COPY statement copies both the metadata and data from the source table into the new table. The new table for both CREATE TABLE operations has no relationship to the source table after creation; thus modifications to the source table will not propagate to the new table.
# The following example creates a new empty table named newtable# in mydataset with the same metadata as sourcetable#and the data from the SELECT statement:CREATE TABLE mydataset.newtableLIKE mydataset.sourcetableAS SELECT * FROM mydataset.myothertable# The following example creates a copy of the mydataset.sourcetable table# named newtable in mydataset:CREATE TABLE mydataset.newtableCOPY mydataset.sourcetable
To learn about DDL support for table snapshots, read Quickly, easily and affordably back up your data with BigQuery table snapshots.
Expanded INFORMATION_SCHEMA views
INFORMATION SCHEMA for streaming data
If you stream data into BigQuery, you can now monitor your data streams using INFORMATION_SCHEMA streaming views to retrieve historical and real-time information about data streaming into BigQuery. These views contain per minute aggregated statistics for each table that have data streamed into them.
# The following example calculates the per minute breakdown of total failed requests for all tables in the project in the last 30 minutes, split by error code.SELECTstart_timestamp,error_code,SUM(total_requests) AS num_failed_requestsFROM`region-us`.INFORMATION_SCHEMA.STREAMING_TIMELINE_BY_PROJECTWHEREerror_code IS NOT NULLAND start_timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP, INTERVAL 30 MINUTE)GROUP BYstart_timestamp,error_codeORDER BY1 DESC
Expanded DDL column support in INFORMATION_SCHEMA views
Last year, we announced DDL column support in INFORMATION SCHEMA views – an innovative approach which allows data administrators to generate object creation DDL for one, multiple or all tables and views directly from the TABLES INFORMATION_SCHEMA view. BigQuery now supports the ability to generate object creation DDL for other object types such as <a href="https://cloud.google.com/bigquery/docs/information-schema-datasets#schemata_view" target="_blank" rel="noopener">schemata</a> (datasets) and routines (functions, table functions and procedures).
We hope you love these new user-friendly SQL features from BigQuery. To learn more, visit the BigQuery page and try BigQuery for free using the BigQuery Sandbox.
By: Jagan R. Athreya (Product Manager, Google Cloud)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!