
As data environments become more complex, companies are turning to streaming analytics solutions that analyze data as it’s ingested and deliver immediate, high-value insights into what is happening now. These insights enable decision makers to act in real time to take advantage of opportunities or respond to issues as they occur.
While understanding what is happening now has great business value, forward-thinking companies are taking things a step further, using real-time analytics integrated with artificial intelligence (AI) and business intelligence (BI) to answer the question, “what might happen in the future?” Arkansas-based Tyson Foods has embraced AI/BI analytics to enable predictive insights that unlock new opportunities and drive future growth.
From our partners:
Creating a digital twin for connected intelligence company wide
Before using AI/BI, Tyson’s analytics capabilities consisted of traditional BI solutions focused on KPIs and simplifying data so that humans could understand it. Tyson wanted to leverage its data to uncover ways to improve current processes and grow its business. But with BI alone, Tyson struggled to use data to run the simulations and scenarios essential to make educated decisions. To keep growing, it had to embrace the complexity of its data, building ways to analyze it and use it to inform decision making.
Tyson’s on-premises analytics solutions limited its ability to be aggressive and make intelligent, timely, prescriptive decisions. The solution was to create a digital twin to scale optimizations within business processes, moving from local optimizations to system-wide connected optimizations. Doing so meant shifting entirely to cloud computing, with an initial focus on building the ingestion component of the digital twin platform.
Investing in a digital twin enabled Tyson to accelerate new capabilities like supply chain simulation “what-if” scenarios, prescriptive price elasticity recommendations, and improvement of customer intimacy.
Solving the ingestion problem for faster time to insights
Before its migration to Google Cloud, analytics projects that Tyson suffered from uncertainty over how to obtain the data. This problem was prolific and caused project times to be extended for weeks or even months due to the need to write and support one-off data ingestion processes at the front end. This problem also prevented the IT team from delivering analytics solutions fast enough for the business to take full advantage of them.
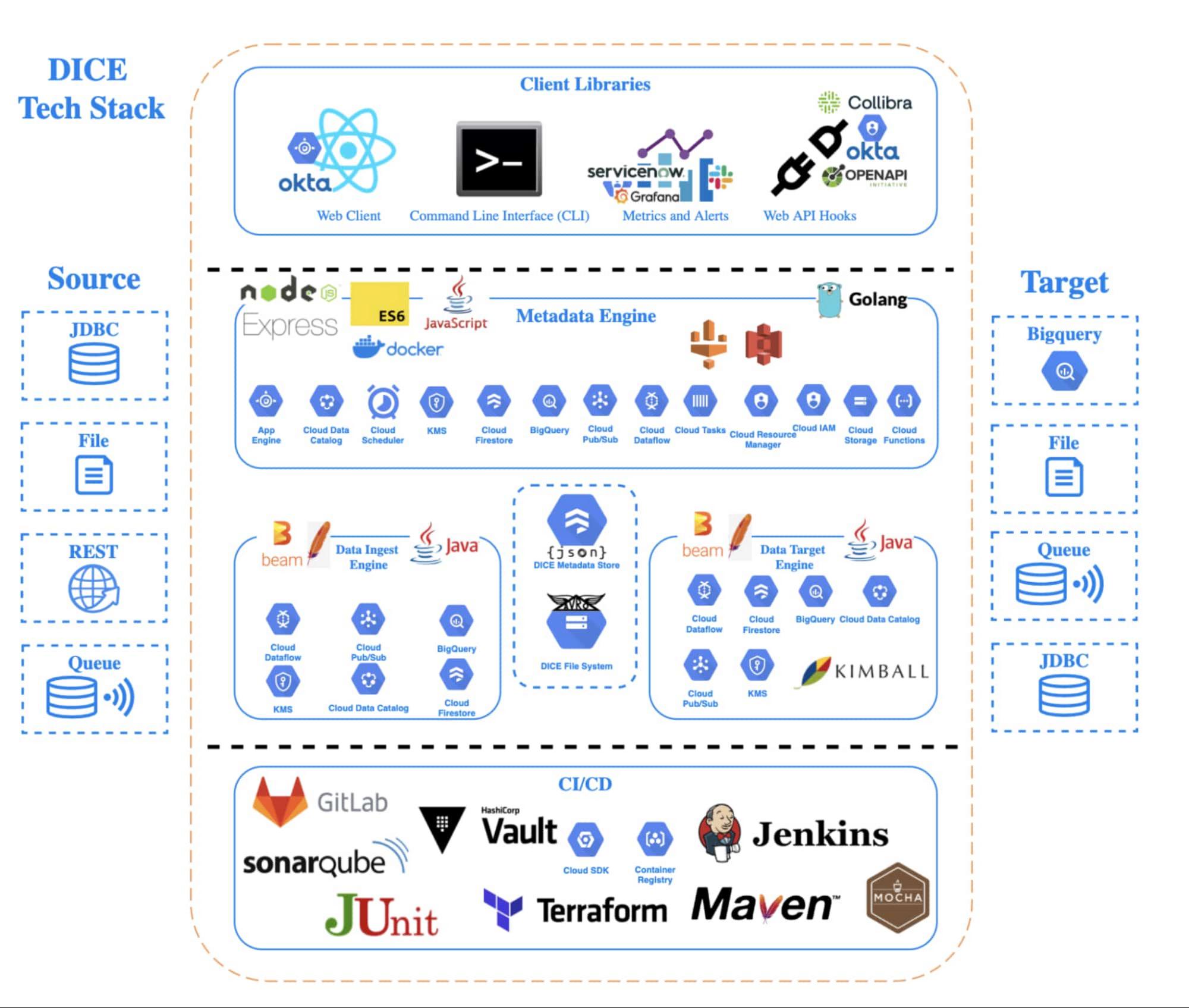
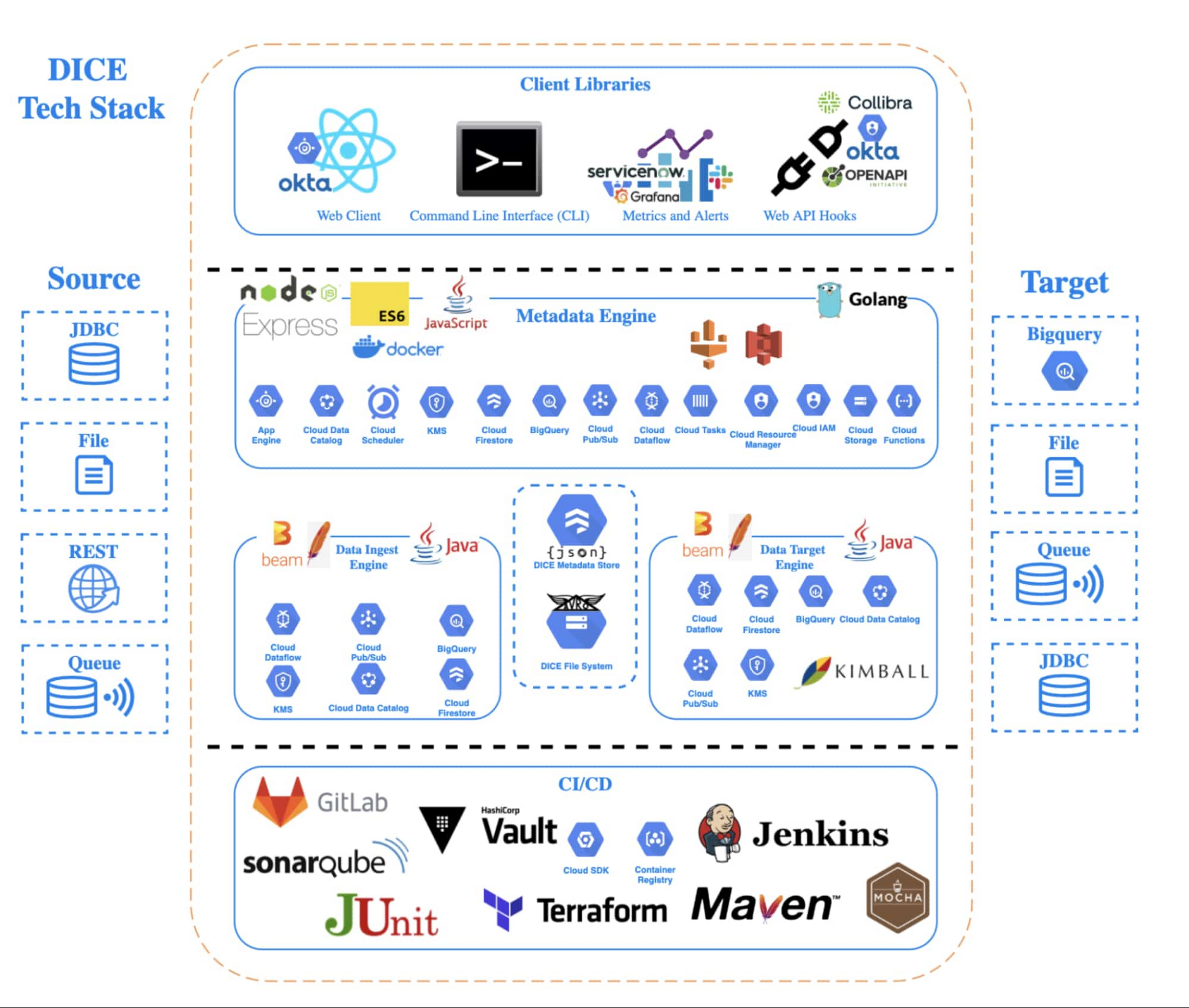
To solve this analytics problem, the team created Data Ingestion Compute Engine (DICE). DICE is a Google Cloud-hosted, open-source, cloud-native ingestion platform developed to provide configuration-based, no-ops, code-free ingestion from disparate enterprise data systems, both internal and external. It is centered on three high-level goals:
- Accelerate the speed of delivery of IT analytics solutions
- Enable growth of IT capabilities to produce meaningful insight
- Reduce long-term total cost of ownership for ingestion solutions
Creating DICE ingestion platform with Google Cloud services
Teams use DICE to set up secure data ingestion jobs in minutes without having to manage complex connections or write, deploy, and support their own code. DICE enables unbound scale, highly parallel processing, DevSecOps, open source, and the implementation of Lambda Data Architecture.
A DICE job is the logical unit of work in the DICE platform, consisting of immutable and mutable configurations persisted as JSON documents stored in Firestore. The job exists as an instruction set for the DICE data engine, which is Apache Beam running Dataflow to instruct which data to pull, how to pull it, how often to pull it, how to process it, when it changes, and where to direct it.
Two of DICE’s primary layers include the metadata engine and the data engine. The metadata engine is responsible for the creation and management of DICE job configuration and orchestration. It is made up of many microservices that interact with multiple Google Cloud services, including the job configuration creation API, job build configuration helper API, and job execution scheduler API.
The data engine is responsible for the physical ingestion of data, the change detection processing of that data, and the delivery of that data to specified targets. The data engine is Java code that uses the Apache Beam unified programming model and runs in Dataflow. It is comprised of streaming, jobs, and Dataflow flex template batch jobs. Logically, the data engine is segmented across three layers: the inbound processing layer, the DICE file system layer, and the target processing layer, which takes the data from the DICE file system and moves it to targets.
Rolling DICE for thousands of ingestion jobs each day
DICE was first deployed to a production environment in November 2019, and just two years later, it has more than 3,000 data ingestion jobs from more than a hundred disparate data systems, both internal and external to Tyson Foods. Most of these jobs run multiple times a day. On a daily basis the DICE environment sees more than 25,000 Dataflow jobs running and an average of 3.25 terabytes of new data being ingested.


DICE supports ingestion from many different types of technologies, including BigQuery, SQL Server, SAP HANA, Postgres, Oracle, MySQL, Db2, various types of file systems, and FTP servers. Additionally, DICE supports target platform technologies for ingestion jobs that include multiple JDBC targets, multiple file system targets, and BigQuery and queue-based store and forward technologies.
The platform continues to see linear growth of DICE jobs, all while keeping platform costs relatively flat. With increasing demand for the platform, Tyson’s IT team is constantly enhancing DICE to support new sources and targets.
This intelligent platform keeps adding new value and makes it simple for Tyson to take advantage of its data. This innovation is a necessity in this fast-changing world of digital business in which companies must transform a high volume of complex data into actionable insight.
By: Nathan Marks (Staff Engineer, Tyson) and Sagar Kewalramani (Customer Engineer, Google)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







