Today it is even easier to capture logs in your Java applications. Developers can get more data with their application logs using a new version of the Cloud Logging client library for Java. The library populates the current executing context implicitly with every ingested log entry. Read this if you want to learn how to get HTTP requests and tracing information and additional metadata in your logs without writing a single line of code.
There are three ways to ingest log data into Google Cloud Logging:
From our partners:
- Develop a proprietary solution that directly calls the Logging API.
- Leverage logging capabilities of the Google Cloud managed environments like GKE or install Google Cloud Ops agent and print your application logs to stdout and stderr.
- Use Google Cloud Logging client library in one of many supported programming languages.
The library provides you with ready to use boilerplate constructs built following the best practices of using Logging API. Java applications can use the Google Cloud Logging library to ingest logs using the integrations with Java Logging and Logback framework.
If you are new to using Google Logging client libraries for Java, follow the steps to set up Cloud Logging for Java and get started.
In the version 3.6 release of the the Logging client library for Java you get many long demanding features including automatic population of the metadata about the environment’s resource supporting Cloud Run and Cloud Functions, HTTP request contextual information, tracing correlation that enables displaying grouped log entries in Logs Explorer and more. This release of the library is composed of the three packages:
- google-cloud-logging — provides the hand-written layer above Cloud Logging API and the integration with legacy Java Logging solution.
- google-cloud-logging-logback is the integration with the Logback framework and ingests logs using the google-cloud-logging package.
- google-cloud-logging-servlet-initializer is a new addition to the library; it provides integration with servlet-based Web applications.
The features are available in the versions ≥3.6.3 and ≥0.123.3-alpha of the google-cloud-logging and google-cloud-logging-logback packages respectively.
If you are using Maven, update the packages’ versions in the pom.xml:
<dependency><groupId>com.google.cloud</groupId><artifactId>google-cloud-logging</artifactId><version>3.6.3</version></dependency><dependency><groupId>com.google.cloud</groupId><artifactId>google-cloud-logging-logback</artifactId><version>0.123.3-alpha</version></dependency>
If you are using Gradle, , update your dependencies:
implementation 'com.google.cloud:google-cloud-logging:3.6.3'implementation 'com.google.cloud:google-cloud-logging-logback:0.123.3-alpha'
You can use the official Google Cloud BOM version 0.167.0 that includes the new releases of the packages.
What is new
The Java library inserts structured information about the executing environment including resource types, HTTP request metadata, tracing and more. Using the library you can write your payloads in one of the three formats:
- A text provided as a Java string
- A JSON object provided as an instance of Map<String, ?> or Struct
- A protobuf object provided as an instance of Any
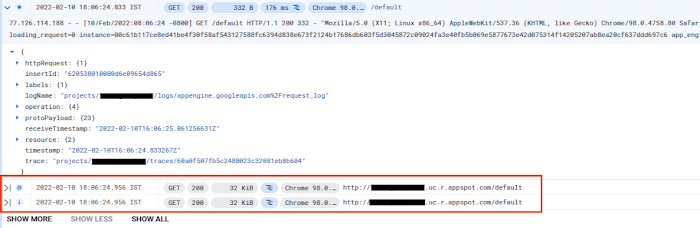
You can use the structured logs with enhanced filtering in Logs Explorer to observe and troubleshoot their applications. The Logs Explorer uses structured logs to establish correlations between traces and logs and to group together logs that belong to the same transaction. The correlated “child” logs are displayed “under” the entry of the “parent” log:
With the previous versions of the Logging library you had to write code to explicitly populate these fields. For example, developers that use Logback framework had to write a code like below to populate the trace field of the ingested logs:
// . . .String traceInfo = request.getHeader("x-cloud-trace-context");TraceLoggingEventEnhancer.setCurrentTraceId(traceInfo);// . . .
And to invoke this code at the beginning of each transaction.
The new features of the Logging library makes implementing the population logic unnecessary. The new version of the library supports automatic population of following log entry fields:
- resource ‒ describes the resource type and its attributes where the application is running. Along with GCE instances, it supports Google Cloud managed services such as GKE, AppEngine (both Standard and Flexible), Cloud Run and Cloud Functions.
- httpRequest ‒ captures info about HTTP requests from the current application’s context. The context is defined per-thread and can be populated both explicitly in the application code or implicitly from the Jakarta servlet requests pipeline.
- trace and spanId ‒ reads the tracing data from the HTTP request header. The tracing data assists in correlating multiple logs that belong to the same transaction.
- sourceLocation ‒ stores info about the class and method names as well as the line of code where the application called the log ingestion method. The library retrieves the data by traversing the trace stack up until the first entry that is not part of the Logging library code or the system package.
What is left to you is to set the payload and relevant payload’s metadata labels. The only field in the log entry that the library does not automatically populate now is the operation field.
Disable information auto-population in log entries
You have full control over the auto-population functionality. The auto-population is enabled by default for your convenience. But in certain scenarios it can be desirable to disable it. For example, if your application is log intensive and has a narrow bandwidth, you may want to disable the auto-population in order to save the connection’s bandwidth for the application communication.
If you are ingesting logs using the write() method of the Logging interface, you can configure the LoggingOptions argument to disable the auto-population:
LoggingOptions options = LoggingOptions.newBuilder().setAutoPopulateMetadata(false).build();Logging logging = options.getService();
If you are using Java Logging, you can disable auto population by adding the following to your logging.properties file:
com.google.cloud.logging.LoggingHandler.autoPopulateMetadata=falseIf you are using Logback framework, you can disable auto population by adding the following to your Logback configuration:
<autoPopulateMetadata>false</autoPopulateMetadata>How the current context is populated
Rich query and display capabilities of Log Explorer such as displaying correlated logs use the log entries’ fields such as httpRequest and trace. The new version of the library uses the Context class to store the information about the HTTP request and tracing data in the current application context. The context’s scope is per thread. Before the library ingests logs into Cloud Logging, it reads the HTTP request and tracing information from the current context and sets the respective fields in the log entries. The fields are populated only if the caller did not explicitly provide values in these fields. Using the ContextHandler class you can setup the HTTP request and tracing data of the current context:
import com.google.cloud.logging.HttpRequest;// . . .HttpRequest request;// . . .ContextHandler ctxHandler = new ContextHandler();Context ctx = Context.newBuilder().setRequest(request).setTraceId(traceId).setSpanId(spanId).build();ctxHandler.setCurrentContext(ctx);
After the context is set all logs that will be ingested in the same scope as the context will be populated with the HTTP request and tracing information that was set in the current context. The Context class can setup the HTTP request using partial data such as URL or request method:
import com.google.cloud.logging.HttpRequest.RequestMethod;// . . .ContextHandler ctxHandler = new ContextHandler();Context ctx = Context.newBuilder().setRequestUrl("https://example.com/info").setRequestMethod(RequestMethod.GET);.build();ctxHandler.setCurrentContext(ctx);
The builder of the Context class also supports setting the tracing information from the parsed values of the Google tracing context and W3C tracing context strings using the methods loadCloudTraceContext() and loadW3CTraceParentContext() respectively.
Implementation of the context population can be a complex task. Java Web servers support asynchronous execution of the request handlers. To manage the context in the right scope may require in-depth knowledge of specific implementation details about each Web server. The new version of the Logging library provides a simple way to automate the process of the current context management, saving you the effort of implementing the code by themselves. The automation supports all Web servers that are based on the Jakarta servlets such as Tomcat, Jetty or Undertow. The current implementation supports Jakarta servlets version ≥ 4.0.4. The implementation is added to the new google-cloud-logging-servlet-initializer package. All that you have to do to enable automatic capturing of the current context is to add the package to your application.
If you are using Maven add the following to your pom.xml:
<dependency><groupId>com.google.cloud</groupId><artifactId>google-cloud-logging-servlet-initializer</artifactId><version>0.1.7-alpha</version><type>pom</type></dependency>
If you are using Gradle, add the following to your dependencies:
implementation 'com.google.cloud:google-cloud-logging-servlet-initializer:0.1.7-alpha'The added package uses the Java’s Service Provider Interface to register the ContextCaptureInitializer class which integrates into the servlet pipeline to capture information about current HTTP requests. The information is parsed to populate the HttpRequest structure. It also parses the request’s headers to retrieve tracing information. It supports “x-cloud-trace-context” (Google tracing context) and “traceparent” (W3C tracing context) headers.
Use Logging library with logging agents
Many applications utilize logging capabilities of the Google Cloud managed services. The applications output their logs to stdout and stderr, and the logs are ingested into Cloud Logging by Logging agents or the Cloud managed services with the logging agent capabilities. This approach benefits from asynchronous log processing that does not consume application resources. The drawback of the approach is that if you want to populate fields in the structured logs or provide the structured payload, they have to format their output following the special Json format that the logging agents can parse. Also, while the logging agents can detect and populate the resource information about the managed environment, they cannot help with auto population of other fields of the log entry such as traceId or sourceLocation.
The new release of the Logging library for Java introduces the support for logging agents in both of its Java Logging and Logback integrations. Now the library’s users can instruct the appropriate handler to redirect the log writing to stdout instead of Logging API.
If you are using Java Logging, add the following to your logging.properties file:
com.google.cloud.logging.LoggingHandler.redirectToStdout=trueIf you are using Logback, add the following to the Logback configuration:
<redirectToStdout>true</redirectToStdout>By default, both LoggingHandler and LoggingAppender write logs by calling the Logging API. You have to add the above configurations to make them utilize the logging agents for the log ingestion.
Some limitations of using Logging Agents
When configuring the library’s Java Logging handler or Logback adapter to redirect log writing to stdout, you should be aware of the constraints that the use of logging agents implies.
Google Cloud managed services (e.g. GKE) automatically install logging agents in the resources that they provision. For example, a GKE cluster has a logging agent installed in each worker node (GCE instance) of the cluster. As a result, logging agents are constrained with the resource they run and do not support customization of the resource field of the ingested log entries.
Additionally, the logName of all ingested logs is defined by the agent and cannot be changed*. It means that the application cannot define the log name or where the log entry will be stored (a.k.a. log’s destination name).
If it is essential for you to define a custom resource type or to control to which project the logs will be routed and/or the log name, you should not redirect the log writing to standard output.
* It is possible to customize the log name (but not the destination) by customizing the Logging agent’s configuration in GCE instances by defining the name as the “tag”.
What is next
Let’s recap the benefits of upgrading your logging client to the latest version.
Use the new Logging library if you need log correlation capabilities of Log Explorer or forward Cloud Logging structured logs to external solutions and use the data in the auto-populated fields.
Use the google-cloud-logging-servlet-initializer package to automate the context management if you run a request based application that uses Jakarta servlets. Note that it will not work with legacy Java EE servlets or Web servers that are not based on Java servlets such as Netty.
If you run your application in the Google Cloud serverless environments like Cloud Run or Cloud Functions, consider using Java Logging or Logback with the configuration that redirects formatted logs to standard output like it is described in the previous section. Leveraging logging agents for ingesting logs resolves some reliability problems about asynchronous log ingestion such as CPU throttling on Cloud Run or no grace period in Cloud Functions.
By Leonid Yankulin, Developer Relations Engineer
Source Google Cloud
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!