This past August at NGINX Sprint 2.0, I discussed the patterns we see customers adopt to successfully leverage cloud-native technologies when building modern apps. They are converting monoliths to microservices, adopting service meshes, and approaching the world from a “distributed and decoupled first” viewpoint. I’m not a huge fan of introducing YAT (yet another term), but one concept keeps emerging within the enterprise: “Cluster Out”. I wrote about it in NGINX Sprint 2.0: Clear Vision, Fresh Code, New Commitments to Open Source.
Cluster Out is not a comprehensive Kubernetes architecture. It stems from solving networking and security gaps that customers have uncovered. It starts with building a rock-solid ingress/egress (north/south) and service mesh (east/west) with security. From that foundation, it addresses similar networking and security gaps that emerge in intra-cluster API traffic and inter-cluster routing and failover. As more of our customers stand up Kubernetes in production and advance down the cloud-native path (and as NGINX’s capabilities for serving cloud-native continue to evolve), I want to expand on Cluster Out and further develop the modern app story.
From our partners:
Because we believe developing broad Cluster Out awareness will save lots of pain and heartache when transitioning from POC Kubernetes and microservices applications to production deployments. One of the wonderful things about Kubernetes is that it works equally well at small and large scale. Unfortunately, the shortcomings in the out-of-the-box Kubernetes are not revealed until you start put it into production and start running moderate or significant L7 traffic through a cluster. Scaling out Kubernetes is analogous to what we saw in the explosion of 3-tier web applications. Networking companies created Application Delivery Controllers to secure and scale these rapidly expanding and increasingly critical 3-tier apps.
The same pattern is occurring in the realm of microservices and Kubernetes. But now we’ve broken up the various requirements of applications into specific services like local load balancing, WAF, DDoS, authentication, encryption, and global load balancing. And we run each service discretely on its own piece of the cluster. Thinking and designing Cluster Out is a mindset and framework for ensuring you shore up these areas so that you don’t have modern apps fall over you on you when it matters most — in production while serving live customers. Ideally, you would architect Cluster Out from the beginning. Sadly, many companies do it reactively only after K8s traffic falls over. This is why we want to foster a Cluster Out mindset even in the POC and exploratory phases of standing up Modern Applications running on Kubernetes.
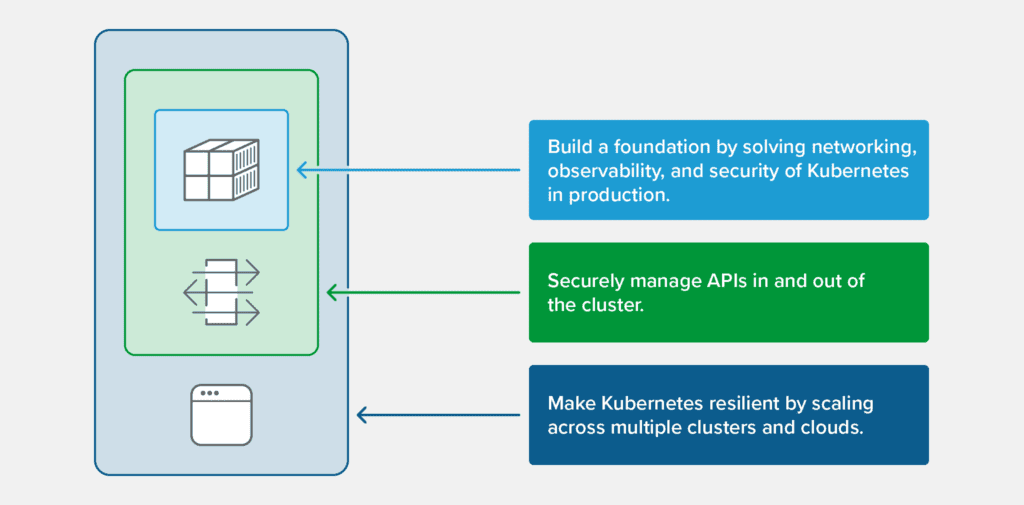
The Three Stages of the Cluster Out Pattern
We see three stages in the Cluster Out pattern:
- Stage #1: Build a foundation by solving networking, observability, and security of Kubernetes in production.
- Stage #2: Securely manage and performance-tune APIs in and out of the cluster.
- Stage #3: Make Kubernetes resilient by scaling across multiple clusters and clouds.
Stage #1: Build a Solid Kubernetes Foundation
Developer productivity is paramount in our digital-first world. Containers have boosted productivity as devs can get code running in production faster. But what happens when you have thousands of containers? Enter Kubernetes. As more and more organizations get up to speed with Kubernetes and containers, they often learn this brave new world requires a high degree of customization and tuning. It also needs a different mindset – one where all applications are designed to be distributed and loosely coupled via APIs. While Kubernetes is quite general purpose and adaptable for almost any use case, you must add capabilities in key areas to make it production-ready and stable for developers.
Layer 7 Traffic Management
Kubernetes comes with native per connection load balancing via kube-proxy, which is designed for Layer 4 (L4) traffic. Although kube-proxy multiplexes over to Layer 7 (L7) when no other proxy is present, it’s risky because L7 traffic management (load balancing, traffic shaping, and other core capabilities) should run on a per request basis. Trying to use kube-proxy for L7 traffic can lead to poor performance and defaults to connection-level security policies that may not map over to application-level requirements. To achieve production readiness, most organizations benefit from adopting a specialized L4-L7 proxy called an Ingress controller. The adoption of a production-grade Ingress controller provides:
- Resilience, such as blue-green deployments, rate limiting, and circuit breaking
- Security and identity, such as WAF integration, centralized authentication/authorization, mutual TLS, and end-to-end encryption
- Monitoring and observability, such as real-time dashboards and Prometheus metrics
Security and Identity
Making a Kubernetes cluster secure enough for production requires considerable modifications to the out-of-the-box install. Kubernetes is controlled via API and uses APIs for all internal and external communications, so it’s essential to properly secure APIs by controlling access and setting up authentication methods, and then configure RBACs for authorizing API access. Of particular importance is controlling access to the kubelet API, which enables control over nodes and containers. By default, kubelet allows unauthenticated access to this API.
Beyond APIs, it’s crucial to control the capabilities of a workload or user at the actual runtime. Default authorization and workload/user control are high-level and not configured to specific business logic or security limitations. Similarly, create and apply resource quote limits by namespace on the amount or type of CPU, memory, or persistent disk. This is also a good way to limit the number of services, pods, or volumes that can exist in any namespace. Other necessary steps include limiting unauthorized container kernels modules, restricting network access, and properly configuring log capabilities are all necessary steps. Bottom line: It does take a bit of work to properly secure Kubernetes and create automated rules to apply these policies and practices on any Kubernetes cluster in your environment.
Monitoring and Observability
As more moving parts are added, and those parts move faster and faster, modern apps require a different approach to monitoring and observability. The monitoring and observability layer must create a persistent yet flexible view of all microservices and APIs. To ensure apps are reliable, DevOps teams need to understand how that the apps act when deployed and scaled.
There are various parameters on which you can inspect application performance based on the Cluster Out approach; Using Kubernetes resource metrics and APIs, you can monitor and observe performance of containers, pods, services, and cluster performance as a whole. Kubernetes does make it easy to leverage Prometheus, a free CNCF project for monitoring and observability. That said, for the best monitoring and observability coverage, you will want tight integration between L4-L7 proxies, Ingress controllers, and your monitoring solution stack. That can entail substantial work with Prometheus, so you may want to explore other options. In particular, while L4 is more addressable with brute force solutions of capacity, L7 is often difficult to troubleshoot. Deploy a solution that makes L7 introspection easy for any team – a crucial part of the Cluster Out foundation.
Once your Kubernetes deployments are stable, predictable, observable, and secure, then developers will see success. If you fail on any of these counts, modern apps will take longer to bring to market – risking revenue, customer satisfaction, and your brand’s reputation.
Stage #2: Securely Manage and Performance-Tune APIs In and Out of the Cluster
We already talked about setting up API-level security – that’s only half the battle. API management also becomes a crucial scaling skill – or a bottleneck if handled poorly. When developers embrace your Kubernetes Cluster Out foundation, the number and type of microservices running on your clusters will grow exponentially. Here is the progression we see in our customers. Once you build the solid foundation (Stage 1), developers will deploy and ship more containers. Most of the time those containers represent a diversity of microservices. Microservices and the containers they live in must communicate “East-West” within the cluster. In Kubernetes (and in containers), all internal communication is via API.
An Ingress controller manages North-South traffic in Kubernetes deployments but does little to manage this new pattern and explosion of East-West traffic. Internal traffic will, in most cases, dwarf the volume of North-South traffic. This means that managing East-West traffic is as complex, if not more complex, than managing North-South traffic. As this is just another flavor of API traffic, one would think API Gateways would be purpose built for this task. In fact, API gateways are necessary but not sufficient for managing the combined flux of East-West and North-South traffic. Because they were initially designed primarily for North-South traffic and not necessarily for the realities of Kubernetes (multiplexed traffic, different network topology), many API gateways struggle to provide what they advertise at scale in Kubernetes. This is why air-tight integration of the API Gateway and other Kubernetes networking components (the Ingress controller, etc) are essential.
Beyond API Gateways, you need to make it easy for your developers to define, publish, and manage the lifecycle of these internal APIs. For this API management (APIM) is needed. Traditional APIM solutions are not designed for the rapidly evolving and quickly scaling world of Kubernetes and East-West traffic driving the bulk of API usage. Because they were designed for a smaller number of APIs with less frequent changes on less dynamic infrastructure, traditional APIMs are too brittle and often too expensive to run effectively in Kubernetes. In other words, they are not designed for Cluster Out patterns. this pattern and are brittle, expensive, or both.
In other words, you need a solution designed to handle the scale and granularity of microservices APIs in a cluster, but with a developer-friendly system that encourages innovation and iteration. To its credit, Kubernetes makes it relatively simple to secure all APIs with HTTPS/TLS by default, checking the first box. Beyond that, APIM remains a largely manual task in out-of-the-box Kubernetes. This is why you will need to set up an APIM platform that eliminates much of the manual work of structuring, documenting, securing and setting rules for APIs. That platform must also be intelligent and move faster than human speed. Otherwise, the API management team and platforms become the bottleneck and microservices applications scale poorly.
These APIM solutions must be low latency and simple to manage, because complicated environments could have thousands of APIs. For example, you don’t want an API gateway to be reliant on databases that may not perform at application speed, thereby slowing down application performance. In addition, because most Modern Apps still have to interact with legacy apps and monoliths, API gateways should be flexible enough to incorporate API management for any environment, and easy to port from one environment to another with minimal toil. API gateways also need to be able to support a wide and growing array of authentication capabilities and communication protocols.
In a nutshell, the more closely your API gateway capabilities mirror and match those of your L7 proxies and observability and monitoring solutions, the easier it is to build on the Cluster Out foundation. APIs are the vascular system of modern technology, and just as the brain and heart manage blood flow to keep us alive, well-managed APIs and the autonomous systems governing them are essential to keeping apps healthy and self-healing.
Stage #3: Make the Cluster Resilient
The third stage in implementing the Cluster Out pattern is making sure that your foundation is flexible enough to deliver resilience. The overarching design pattern of Modern Apps is creating distributed, loosely coupled, and resilient cloud‑native applications. The Cluster Out foundation must support the key requirements for resilience. This means designing an environment to be cloud agnostic (as much as possible).
To start with, Modern Apps must be able to communicate across multiple Kubernetes clusters running in different availability zones, data centers, and clouds. This could be challenging, for example, if your app is running in two different managed Kubernetes environments in public clouds, each of which is tightly integrated with the security, monitoring, and traffic management tools of that cloud. Ideally, resilience requires the deployment of a unified, holistic management and orchestration layer that makes the environment transparent and non-opinionated to the DevOps, security, API, and development teams.
By enabling environment diversity and cross-environment orchestration, Cluster Out creates higher levels of resilience by distributing the risk and enabling rapid failover. Depending on the app or service needs, this could mean maintaining warm instances in multiple environments with the ability to scale up or down as needed in each of those environments. The key here is to focus on service resilience. Apps running in Kubernetes are typically distributed microservices. Failing over from one cluster at one site to another cluster at an entirely different site should be architected at the service-level, not the aggregate app. This is important for creating and tuning high-availability infrastructure designed to meet specified SLAs. (Note: This is incredibly important for apps that might face unpredictable scaling events, such as media, games, or financial services.) A baseline of resilience and the controls required to deliver it can also create benefits like cost control and performance tuning, along with regional, national, and industry compliance.
Out-of-the-box Kubernetes doesn’t solve the resilience challenge. You need to connect your Kubernetes perimeter – the Ingress controller – automatically to external technologies like L4 load balancers, application delivery controllers, monitoring and observability solutions, and DNS services to route traffic and handle failovers across environments. Along the way, you need to evaluate what level of managed services are acceptable and where to draw the line for managing the underlying infrastructure and optimizing for resilience. This is not an easy task – you might face tradeoffs between clouds that have underlying limitations. For example, the required time for Kubernetes cluster restarts of managed services may vary greatly between clouds.
In reality, large organizations will need to engineer resilience and redundancy that fits within the existing context of their global networking, load balancing and other services. For webscale apps, this often means that Kubernetes and its networking tier sits behind a perimeter tier or load balancers and application delivery controllers. At this global view of your applications, for the ultimate in resilience you need to create a high availability service capability for microservices running in Kubernetes.
This translates into a sensitive failover process that is constantly probing the health of your services to identify signs of degradation or violations of SLAs. Once metrics hit a certain threshold or demonstrate a documented trend line, then services will automatically fail over to another cluster managed by your organization, either locally or somewhere else. The technology that makes this happen are SNI (Server Name Indication) probes, a relatively new capability in Kubernetes. The SNI functionality allows you to gather service health data in a secure fashion and then use that data to inform and configure failover systems in a different cluster – load balancer, ADC, DNS server. This lets you bridge the world inside your cluster to the outside world, and create HA configurations at a global scale. (At NGINX, we built a product to automate the discovery and configuration of this otherwise complex act of failing over microservices from one global load balancer / ADC / DNS to another.)
The bottom line? Designing for resilience – either across clouds, within a cluster, or bridging multiple locations in your organization — effectively future-proofs your Kubernetes-based applications and creates multiple ways to ensure that applications do not fail in catastrophic ways.
Follow the Cluster Out Pattern to Kubernetes Success
At F5, we are privileged to work with some of the most forward-thinking organizations and developers in the technology world. As a partner to those talented architects and builders, we get to experience the future of technology and learn from their experience. We can share those lessons with the world to shorten the learning curve, enabling more organizations to be successful with less struggle and risk.
Cluster Out offers platform teams and DevOps teams a methodology for hardening Kubernetes in production. To be clear, Cluster Out is only as good as the execution and planning that goes into the actual deployment and implementation. In an environment of rapidly changing technology infrastructure, a guiding methodology can clarify decisions and priorities. Kubernetes adoption has a notoriously steep learning curve – but it doesn’t have to be that way. Cluster Out is one proven path to achieve Kubernetes success with less risk of hurting yourself and your organization. Or, as I like to say, Cluster Out lets you run with scissors and build on the cutting edge while still keeping your developers, security, and DevOps teams safe.
I’d love to hear your thoughts and feedback on Cluster Out and any suggestions on how we can do it better.
–
Rob Whiteley serves as Vice President and General Manager of the NGINX Product Group at F5. He has led marketing, product, and analyst teams for companies like Hedvig, Riverbed, and Forrester. Rob uses his experience working with enterprise IT and DevOps customers to deliver thought leadership and drive demand for modern IT infrastructure solutions.
Guest post by Rob Whiteley, Vice President and General Manager of the NGINX Product Group at F5
Source CNCF
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!