
Developers and ML engineers face a variety of challenges when it comes to operationalizing Spark ML workloads. One set of challenges may come in the form of infrastructure concerns, for example, how to provision infrastructure clusters in advance, how to ensure that there are enough resources to run different kinds of tasks like data preparation, model training, and model evaluation in a reasonable time. Another set of challenges could come from task orchestration and data handling, for example, how to ensure that the most up-to-date features are available when a model training task is run.
In order to solve those challenges, you can use Vertex AI Pipelines to automate ML workflows in conjunction with Dataproc for running serverless Spark workloads. For example, this article shows you how to train and deploy a Spark ML model to achieve near real-time predictions, without provisioning any infrastructure in advance. In particular, It proves how to launch and orchestrate Dataproc jobs from Vertex AI Pipelines by using custom Python components.
From our partners:
Today we are excited to announce the official release of new Dataproc Serverless components for Vertex AI Pipelines that further simplify MLOps for Spark, Spark SQL, PySpark and Spark jobs.
The following components are now available:
- DataprocPySparkBatchOp: PySpark batch workloads
- DataprocSparkBatchOp: Spark batch workloads
- DataprocSparkSqlBatchOp: Spark SQL batch workloads
- DataprocSparkRBatchOp: SparkR batch workloads
With those components, you have native KFP operators to easily orchestrate Spark-based ML pipelines with Vertex AI Pipelines and Dataproc Serverless. You just need to build their preprocessing, training and postprocessing steps and compile the KFP pipeline. Then, thanks to Vertex AI Pipeline and Dataproc Serverless, you will run ML workflow in a reliable, scalable and reproducible way without requiring to provision and manage the infrastructure.
To learn more about how to use these components, you can find a getting started tutorial below
In addition to that, below you have an end-to-end example of using PySpark and DataprocPySparkBatchOp component.
Training Loan Eligibility’s Model using Pyspark and Dataproc serverless in a Vertex AI Pipeline
In this section, we will show you how to build a Spark ML pipeline using Spark MLlib and DataprocPySparkBatchOp component to determine the customer eligibility for a loan from a banking company. In particular, the pipeline covers a Spark MLlib pipeline, from data preprocessing to hyperparameter tuning of a random forest classifier which predicts the probability of a customer being eligible for a loan.
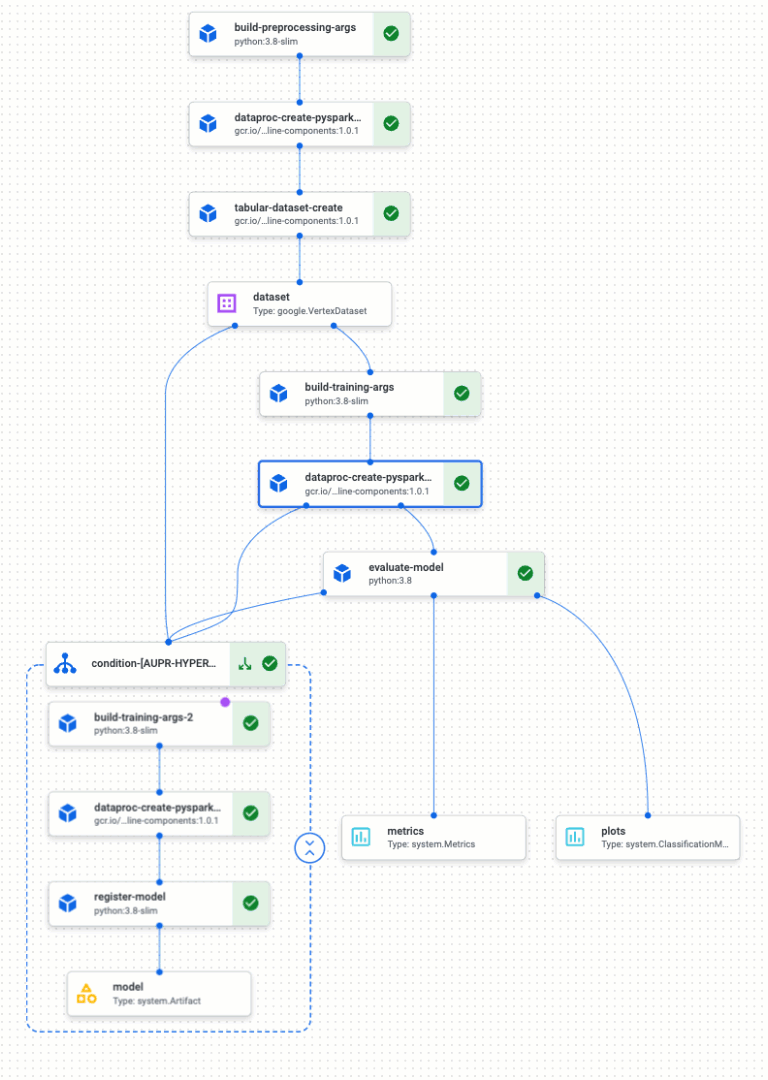
Below you have the pipeline view:
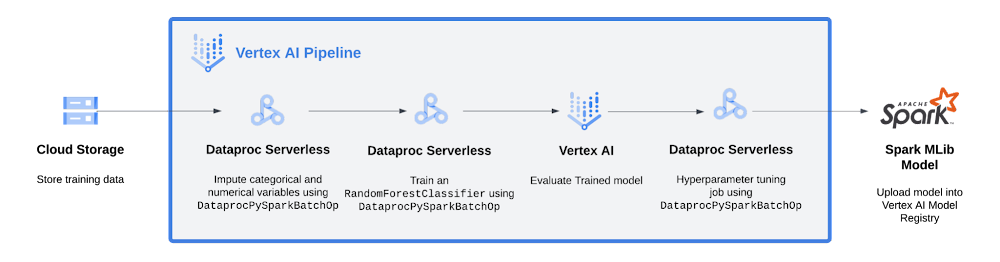
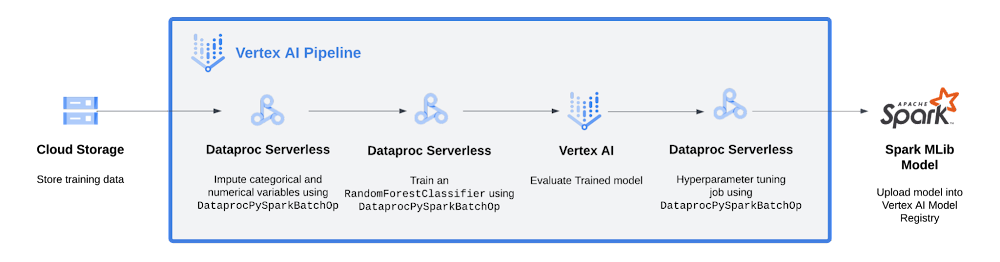
As shown in the diagram, the pipeline:
- Stores data in a Cloud storage
- Imputes categorical and numerical variables with
DataprocPySparkBatchOp - Trains an
RandomForestClassifierwithDataprocPySparkBatchOp - Runs a custom component to evaluate and represents model metrics in Vertex AI Pipelines UI
If the model respects the performance condition (area under the precision-recall curve, auPR for short, is higher that a minimum value of 0.5), then
- Hypertune the RandomForestClassifier with
DataprocPySparkBatchOp - Register the model in the Vertex AI Model Registry
To simplify, let’s consider the training step in order to show how DataprocPySparkBatchOp works.
Train PySpark MLlib model using DataprocPySparkBatchOp component
In the example, we train a Random Forest Classifier using PySpark and Spark MLlib as a pipeline step. To use the DataprocPySparkBatchOp component to execute the training in Dataproc Serverless, you first need to create the training script.
Below you have the one you will find in the GitHub repo:
def main(logger, args):"""Main functionArgs:logger: loggerargs: argsReturns:None"""train_path = args.train_pathmodel_path = args.model_pathmetrics_path = args.metrics_pathtry:logger.info('initializing pipeline training.')logger.info('start spark session.')spark = (SparkSession.builder.master("local[*]").appName("spark go live").getOrCreate())logger.info(f'spark version: {spark.sparkContext.version}')logger.info('start building pipeline.')preprocessing_stages = build_preprocessing_components()feature_engineering_stages = build_feature_engineering_components()model_training_stage = build_training_model_component()pipeline = build_pipeline(preprocessing_stages, feature_engineering_stages, model_training_stage)logger.info(f'load train data from {train_path}.')raw_data = (spark.read.format('csv').option("header", "true").schema(DATA_SCHEMA).load(train_path))logger.info('fit model pipeline.')train, test = raw_data.randomSplit(RANDOM_QUOTAS, seed=RANDOM_SEED)pipeline_model = pipeline.fit(train)predictions = pipeline_model.transform(test)metrics = get_metrics(predictions, TARGET, 'test')for m, v in metrics.items():print(f'{m}: {v}')logger.info(f'load model pipeline in {model_path}.')pipeline.write().overwrite().save(model_path)if model_path.startswith('gs://'):pipeline.write().overwrite().save(model_path)else:path(model_path).mkdir(parents=True, exist_ok=True)pipeline.write().overwrite().save(model_path)logger.info(f'upload metrics under {metrics_path}.')if metrics_path.startswith('gs://'):bucket = urlparse(model_path).netlocmetrics_file_path = urlparse(metrics_path).path.strip('/')write_metrics(bucket, metrics, metrics_file_path)else:metrics_version_path = path(metrics_path).parents[0]metrics_version_path.mkdir(parents=True, exist_ok=True)with open(metrics_path, 'w') as json_file:json.dump(metrics, json_file)json_file.close()except RuntimeError as main_error:logger.error(main_error)else:logger.info('model pipeline training successfully completed!')return 0
For the full code, please see this notebook.
Once the Spark session has been initialized, the script builds the Spark ML pipeline, loads preprocessed data, generates train and test samples, trains the model and saves artifacts and metrics to a Cloud Storage bucket.
Before using the PySpark script, it needs to be uploaded to a Cloud Storage bucket:
!gsutil cp $SRC/model_training.py $BUCKET_URI/src/model_training.py
For the full code, please see this notebook.
Once the script has been uploaded to Cloud Storage, you can use the DataprocPySparkBatchOp to define your training component. The value of the main_python_file_uri argument should be the location of the PySpark script within Cloud Storage.
Here you have what we define
model_traning_op = DataprocPySparkBatchOp(project=project_id,location=location,container_image=custom_container_image,batch_id=training_batch_id,main_python_file_uri=training_main_python_file_uri,args=build_training_args_op.output,).after(build_training_args_op)
For the full code, please see this notebook.
DataprocPySparkBatchOp requires you to specify values for the following parameters:
project, the Project to run the Dataproc batch workloadbatch_id, a unique ID to use for the batch jobmain_python_file_uri, the HCFS URI of the main Python file to use as the Spark driver
The DataprocPySparkBatchOp component accepts other optional parameters that might be necessary for your workload. To learn more about the component, check out the documentation.
Finally, you integrate this component with other tasks in a pipeline definition by using the dsl.pipeline decorator. You then compile the pipeline definition and run it using the Vertex AI SDK.
While running, the pipeline would submit the training workload to Dataproc Serverless service when the model_traning_op step is executed. You can see the batch workload details in the Cloud Console after the job successfully runs.
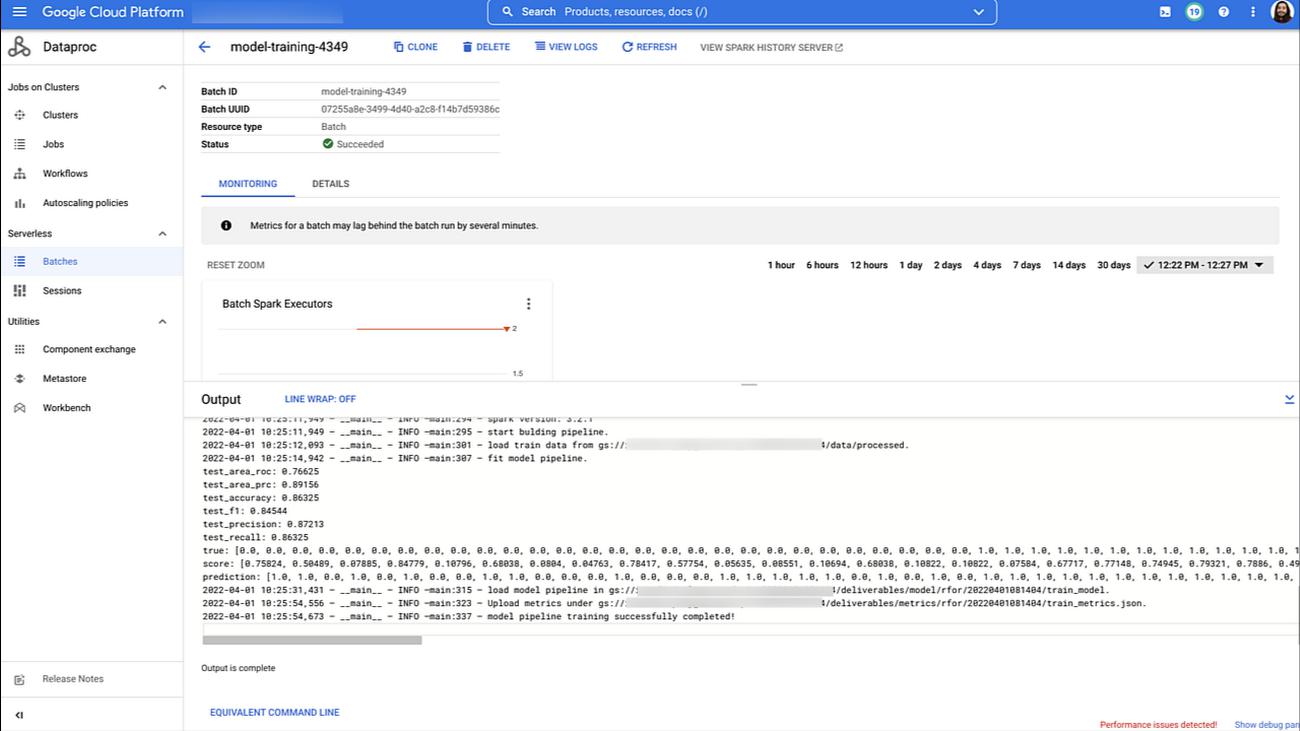
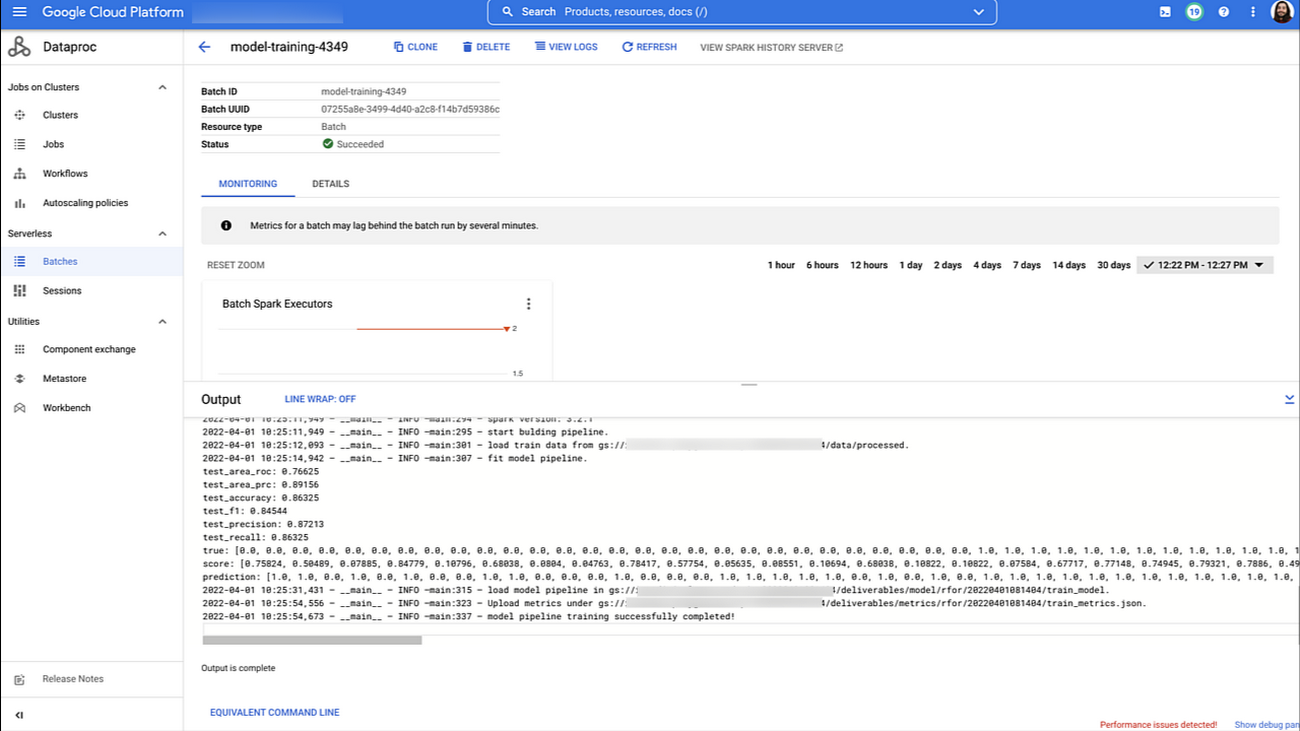
At this point, you can see how it’s simple to integrate Spark jobs into your machine learning workflow by using the Dataproc Serverless components for Vertex AI Pipelines. Dataproc Serverless takes care of managing all the infrastructure, and the training workload consumes only the resources it requires for the time it is running.
You can integrate other tasks into your pipeline using a similar approach. The code below is an example pipeline definition that executes a complete machine learning workflow, including data preprocessing and dataset creation, model training, model evaluation, hyperparameter tuning, and uploading the model to Vertex AI Model Registry. The pipeline uses DataprocPySparkBatchOp to execute PySpark workloads on Dataproc Serverless, and other components that are part of the Google Cloud Pipeline Components SDK.
@dsl.pipeline(name="dataproc-pyspark-preprocessing",description="")def pipeline(preprocessing_batch_id: str = PREPROCESSING_BATCH_ID,preprocessing_main_python_file_uri: str = PREPROCESSING_PYTHON_FILE_URI,train_data_path: str = FEATURES_TRAIN_URI,preprocessed_data_path: str = PROCESSED_DATA_URI,dataset_name: str = DATASET_NAME,dataset_uri: str = GCS_PREPROCESSED_URI,training_batch_id: str = TRAINING_BATCH_ID,training_main_python_file_uri: str = TRAINING_PYTHON_FILE_URI,train_path: str = PROCESSED_DATA_URI,model_path: str = MODEL_URI,metrics_path: str = METRICS_URI,threshold:float = AUPR_THRESHOLD,hpt_batch_id: str = HPT_TRAINING_BATCH_ID,hpt_main_python_file_uri: str = HPT_PYTHON_FILE_URI,hpt_model_path: str = HPT_MODEL_URI,hpt_metrics_path: str = HPT_METRICS_URI,custom_container_image: str = RUNTIME_CONTAINER_IMAGE,model_name: str = MODEL_NAME,project_id: str = PROJECT_ID,location: str = REGION,):from google_cloud_pipeline_components.experimental.dataproc import DataprocPySparkBatchOp#build preprocessed data argsbuild_preprocessing_args_op = build_preprocessing_args(train_data_path=train_data_path,processed_data_path=preprocessed_data_path)# preprocess datadata_preprocessing_op = DataprocPySparkBatchOp(project=project_id,location=location,container_image=custom_container_image,batch_id=preprocessing_batch_id,main_python_file_uri=preprocessing_main_python_file_uri,args=build_preprocessing_args_op.output).after(build_preprocessing_args_op)# create datasetcreate_dataset_op = vertex_ai_components.TabularDatasetCreateOp(display_name=dataset_name,gcs_source=dataset_uri,project=project_id,location=location,).after(data_preprocessing_op)# build training data argsbuild_training_args_op = build_training_args(dataset_uri = create_dataset_op.output,train_path=train_path,model_path=model_path,metrics_path=metrics_path,).after(create_dataset_op)# training modelmodel_training_op = DataprocPySparkBatchOp(project=project_id,location=location,container_image=custom_container_image,batch_id=training_batch_id,main_python_file_uri=training_main_python_file_uri,args=build_training_args_op.output,).after(build_training_args_op)evaluate_model_op = evaluate_model(metrics_uri=metrics_path).after(model_traning_op)# evaluate conditionwith dsl.Condition(evaluate_model_op.outputs['threshold_metric'] >= threshold, name=AUPR_HYPERTUNE_CONDITION):build_hpt_args_op = build_training_args(dataset_uri = create_dataset_op.output,train_path=train_path,model_path=hpt_model_path,metrics_path=hpt_metrics_path,).after(evaluate_model_op)# hypertuning modelhyperparameter_tuning_op = DataprocPySparkBatchOp(project=project_id,location=location,container_image=custom_container_image,batch_id=hpt_batch_id,main_python_file_uri=hpt_main_python_file_uri,args=build_hpt_args_op.output,).after(model_traning_op)# upload modelregister_model(artifact_uri=hpt_model_path).after(hyperparameter_tuning_op)
For the full code, please see this notebook
Vertex AI Pipelines allows you to visualize your machine learning workflow as it executes. The following image shows a completed end-to-end execution using the pipeline definition above.
Conclusion
In this blogpost, we announced new Dataproc components now available for Vertex AI Pipelines. We also provided an end-to-end example of how to use the DataprocPySparkBatchOp to preprocess data, train and hypertune a PySpark MLlib model for loan eligibility.
What’s Next
Do you want to know more about Dataproc serverless, Vertex AI Pipelines and how to deploy Spark models on Vertex AI? Check out the following resources:
- Documentation
- Code Labs
- Github samples
- Video Series: AI Simplified: Vertex AI
- Quick Lab: Build and Deploy Machine Learning Solutions on Vertex AI
Special thanks to Abhishek Kashyap, Henry Tappen, Mikhail Chrestkha, Karthik Ramachadran, Yang Pan, Karl Weinmeister, Andrew Ferlitsch for their support and contributions to this blogpost.
By: Ivan Nardini (Customer Engineer) and Win Woo (Cloud Solutions Architect)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!



