
Earlier last year, Cloud TPU VMs on Google Cloud were introduced to make it easier to use the TPU hardware by providing direct access to TPU host machines. Today, we are excited to announce the general availability (GA) of TPU VMs.
With Cloud TPU VMs you can work interactively on the same hosts where the physical TPU hardware is attached. Our rapidly growing TPU user community has enthusiastically adopted this access mechanism, because it not only makes it possible to have a better debugging experience, but it also enables certain training setups such as Distributed Reinforcement Learning which were not feasible with TPU Node (networks accessed) architecture.
From our partners:
What’s new for the GA release?
Cloud TPUs are now optimized for large-scale ranking and recommendation workloads. We are also thrilled to share that Snap, an early adopter of this new capability, achieved about ~4.65x perf/TCO improvement to their business-critical ad ranking workload. Here are a few highlights from Snap’s blog post on Training Large Scale Recommendation Models:
> TPUs can offer much faster training speed and significantly lower training costs for recommendation system models than the CPUs;
> TensorFlow for cloud TPU provides a powerful API to handle large embedding tables and fast lookups;
> On TPU v3-32 slice, Snap was able to get a ~3x better throughput (-67.3% throughput on A100) with 52.1% lower cost compared to an equivalent A100 configuration (~4.65x perf/TCO)
Ranking and recommendation
With the TPU VMs GA release, we are introducing the new TPU Embedding API, which can accelerate ML Based ranking and recommendation workloads.
Many businesses today are built around ranking and recommendation use-cases, such as audio/video recommendations, product recommendations (apps, e-commerce), and ad ranking. These businesses rely on ranking and recommendation algorithms to serve their users and drive their business goals. In the last few years, the approaches to these algorithms have evolved from being purely statistical to deep neural network-based. These modern DNN-based algorithms offer greater scalability and accuracy, but they can come at a cost. They tend to use large amounts of data and can be difficult and expensive to train and deploy with traditional ML infrastructure.
Embedding acceleration with Cloud TPU can solve this problem at a lower cost. Embedding APIs can efficiently handle large amounts of data, such as embedding tables, by automatically sharding across hundreds of Cloud TPU chips in a pod, all connected to one another via the custom-built interconnect.
To help you get started, we are releasing the TF2 ranking and recommendation APIs, as part of the Tensorflow Recommenders library. We have also open sourced DLRM and DCN v2 ranking models in the TF2 model garden and the detailed tutorials are available here.
Semi-supervised learning with Cloud TPUs
We recently released a technical whitepaper as a joint project between Google Cloud Customer Engineering teams and one of our Global Insurance customers, MunichRE. It highlights how just the Cloud TPU (V3-32) alone enabled them to reduce model training time by 92%, and achieve ~18.75x perf/TCO (in comparison to the A100 GPU) for semi-supervised image classification/segmentation problems. Since Semi-Supervised Learning(SSL) methods achieve significant performance improvements from ingesting large amounts of inexpensive unlabelled data, Cloud TPUs are the perfect complement to keep model training time and costs from becoming infeasible which extracting maximum performance using SSL methods.
Framework support
TPU VM GA Release supports the three major frameworks (TensorFlow, PyTorch and JAX) now offered through three optimized environments for ease of setup with the respective framework. GA release has been validated with TensorFlow v2-tf-stable, PyTorch/XLA v1.11 and JAX [0.3.6].
TPU VMs Specific Features
TPU VMs offer several additional capabilities over TPU Node architecture thanks to the local execution setup, i.e. TPU hardware connected to the same host that users execute the training workload(s).
Local execution of input pipeline
Input data pipeline executes directly on the TPU hosts. This functionality allows saving precious computing resources earlier used in the form of instance groups for PyTorch/JAX distributed training. In the case of Tensorflow, the distributed training setup required only one user VM and data pipeline executed directly on TPU hosts.
The following study summarizes the cost comparison for Transformer (FairSeq; PyTorch/XLA) training executed for 10 epochs on TPU VM vs TPU Node architecture (Network attached Cloud TPUs):
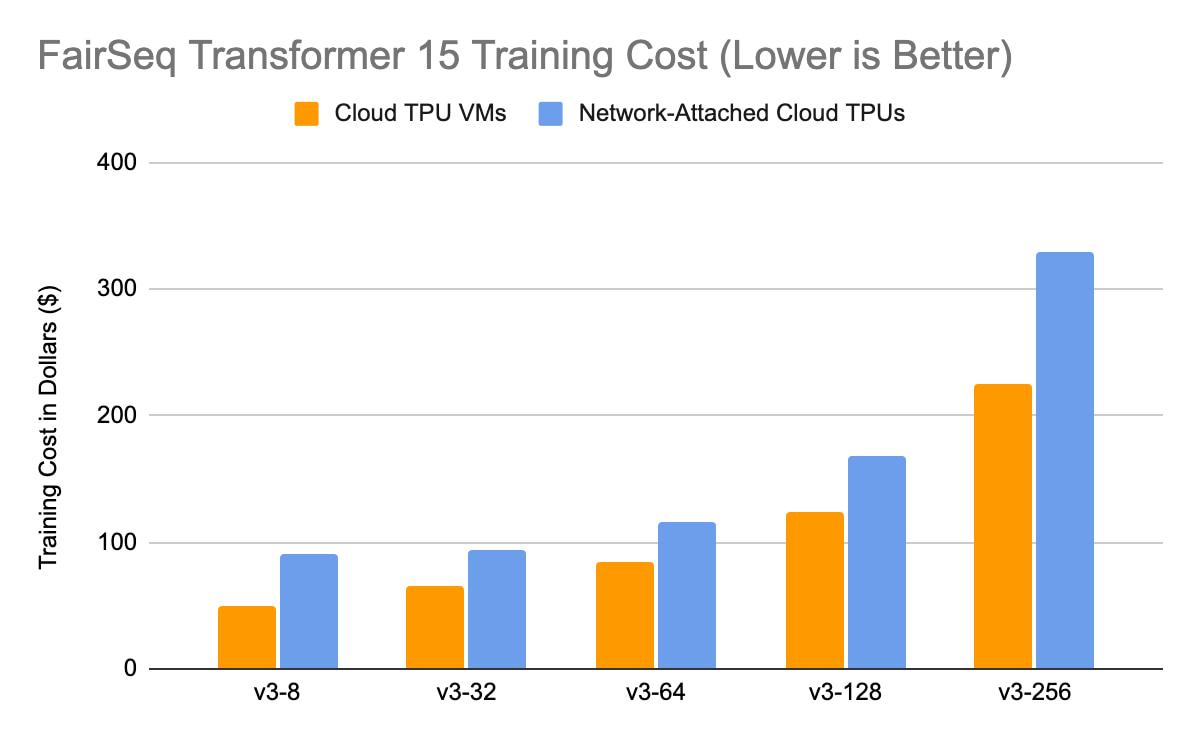
Distributed Reinforcement Learning with TPU VMs
Local execution on the host with the accelerator, also enables use cases such as Distributed Reinforcement Learning. Canonical works in this domain such as seed-RL, IMPALA and Podracer have been developed using Cloud TPUs.
“…, we argue that the compute requirements of large scale reinforcement learning systems are particularly well suited for making use of Cloud TPUs , and specifically TPU Pods: special configurations in a Google data center that feature multiple TPU devices interconnected by low latency communication channels. “—Podracer, DeepMind
Custom Ops Support for TensorFlow
With direct execution on TPU VM, users can now build their own custom ops such as TensorFlow Text. With this feature, the users are no longer bound to TensorFlow runtime release versions.
What are our customers saying?
“Over the last couple of years, Kakao Brain has developed numerous groundbreaking AI services and models, including minDALL-E, KoGPT and, most recently, RQ-Transformer. We’ve been using TPU VM architecture since its early launch on Google Cloud, and have experienced significant performance improvements compared to the original TPU node set up. We are very excited about the new features added in the Generally Available version of TPU VM, such as Embeddings API, and plan to continue using TPUs to solve some of the globe’s biggest ‘unthinkable questions’ with solutions enabled by its lifestyle-transforming AI technologies”—Kim Il-doo, CEO of Kakao Brain
Additional Customers’ testimonials are available here.
How to get started?
To start using TPU VM, you can follow one of our quick starts or tutorials. If you are new to TPUs you can explore our concepts deep-dives and system architecture. We strive to make Cloud TPUs – Google’s advanced AI infrastructure – universally useful and accessible.
By: Vaibhav Singh (Outbound Product Manager, Cloud TPU) and Max Sapoznikov (Product Manager, Cloud TPU)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!




