
Dataflow has provided a number of capabilities to improve utilization and efficiency by automatically provisioning and scaling resources for your job. The following are some of the examples:
- Horizontal Autoscaling that automatically scales the number of workers.
- Streaming Engine, which decouples storage from the workers. This also gives workers access to unbounded storage and more responsive Horizontal Autoscaling.
- Dynamic work rebalancing that splits work across available workers based on work progress.
Building on this solid and differentiated foundation, we recently launched Dataflow Prime, a new next generation serverless, no-ops, autotuning platform for your data processing needs on Google Cloud. Dataflow Prime introduces a new industry-first resource optimization technology, Vertical Autoscaling, which automatically scales worker memory in order to remove the need to do manual tuning of worker configuration. With Vertical Autoscaling, Dataflow Prime automatically determines the right worker configuration for your job.
From our partners:
Current user challenges
With Dataflow, you write your data processing logic using the Apache Beam SDK or Dataflow Templates and let Dataflow handle the optimization, execution and scalability of your pipeline. While in many cases your pipeline executes well, for some cases you have to manually select the right resources like memory for best performance and cost. For many users, this is a time consuming trial and error process and a single worker configuration is unlikely to be optimal for the pipeline. In addition, there was the risk of static configurations becoming outdated when data processing requirements changed.
We have designed Vertical Autoscaling to solve these challenges and allow you to focus on your application and business logic.
How does Vertical Autoscaling work?
Vertical Autoscaling observes out of memory (OOM) events and memory usage of your streaming pipeline over time and triggers memory scaling based on this. This makes your pipeline resilient to out of memory errors without any manual intervention.
With Vertical Autoscaling, if there is high memory utilization, all workers in your job are replaced with workers with larger memory capacity. In the following illustration we see that workers 1, 2, and 3 have high memory utilization and a capacity of 4GB. After Vertical Autoscaling, all workers have a memory capacity of 5 GB, which gives them sufficient memory headroom.
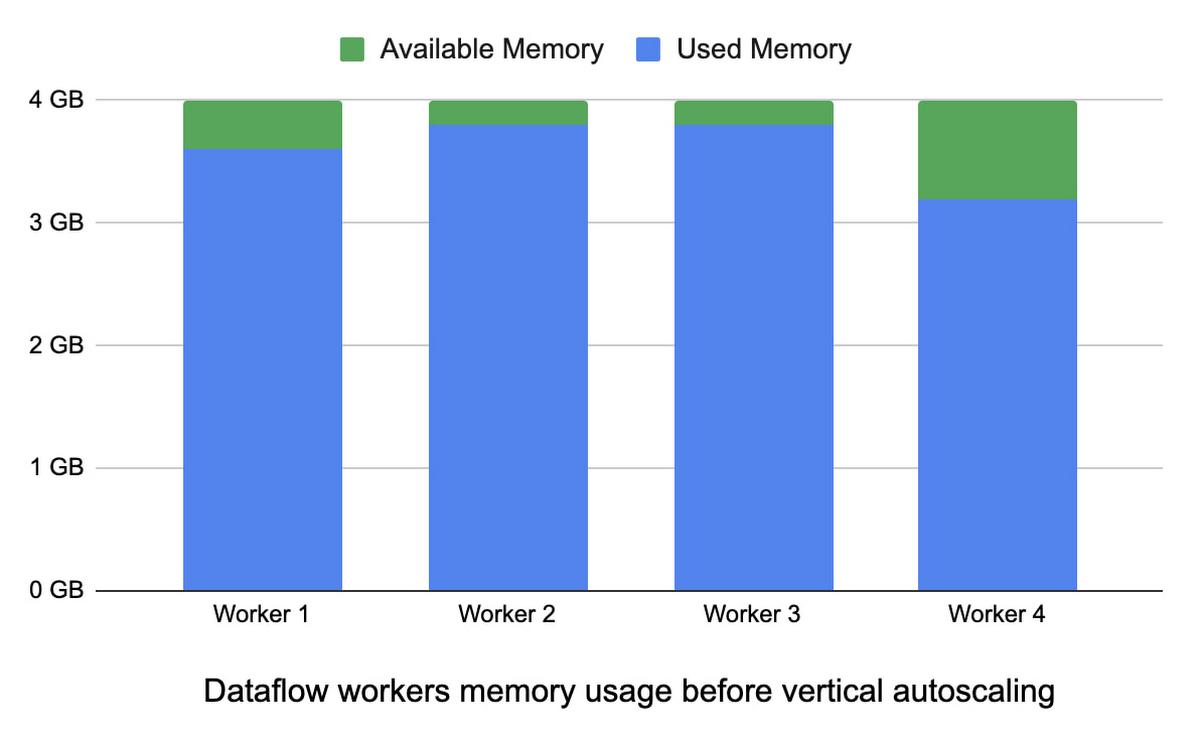

This process is iterative, and it can take up to a few minutes to replace the workers.
Similarly, if there is low memory usage, Vertical Autoscaling downscales the workers to lower memory capacity, thus improving utilization and saving cost. It relies on historical usage data per pipeline to know when it is safe to scale down, prioritizing pipeline stability. You may observe a long period of time (12 hours or more) where no downscaling occurs after a spike in memory utilization. Vertical Autoscaling takes a conservative approach to downscaling in order to keep pipelines processing with minimal disruption.
Things to know about Vertical Autoscaling
How does Vertical Autoscaling impact my job?
- As the workers are replaced, you may observe a temporary drop in throughput, but impact to a running pipeline (i.e. backlog, watermark, throughput metrics) will not be significantly different from a Horizontal Autoscaling event.
- Horizontal Autoscaling is disabled during and up to 10 minutes after Vertical Autoscaling.
- As with horizontal scaling, some backlog may accumulate during the scaling process, if this backlog cannot be cleared in a timely fashion, horizontal scaling may occur to clear that backlog.
Does Vertical Autoscaling remove all OOMs?
- It is important to note that Vertical Autoscaling is designed to react to OOMs and high memory usage, but cannot necessarily prevent OOMs, especially if there is a fast spike in memory usage on a worker which results in an OOM.
- When OOMs occur, Vertical Autoscaling automatically detects them and resize worker memory to address issues. As a consequence, you will see a few OOM errors in the worker logs but these can be ignored if those are followed by upscale events.
- It is also important to note that some OOMs may be happen as a result of downscale events where Dataflow reduced the amount of memory because of underutilization. In such cases, Dataflow will automatically upsize if it detects OOMs. Again, it is safe to ignore these OOM messages if they are followed by upscale events.
- If the OOM messages are not followed by an upscale event, you may have hit the memory scaling limit. In this case you may need to optimize your pipeline’s memory usage or use resource hints.
- If you see OOM messages continuously and have not observed a job message indicating you have hit the memory scaling limit, please contact the support team. Note that if OOMs occur very rarely (e.g. once every few hours per pipeline), Vertical Autoscaling may choose to not scale up the workers to avoid introducing additional disruption.
How to enable Vertical Autoscaling ?
Vertical Autoscaling is only available for Dataflow Prime jobs. See the instructions to launch Dataflow Prime jobs and how to enable Vertical Autoscaling.
You don’t have to make any code changes to run your existing Apache Beam pipeline on Dataflow Prime. Additionally, you don’t have to specify the worker type when launching a Dataflow Prime job. However if you want to control the initial worker’s resource configuration you can use resource hints.
You can confirm if Vertical Autoscaling is running on your pipeline by looking for the following job log:
- Vertical Autoscaling is enabled. This pipeline is receiving recommendations for resources allocated per worker.
How to monitor Vertical Autoscaling ?
Whenever Vertical Autoscaling updates workers with more or less memory, the following job logs are generated in Cloud Logging:
- Vertical Autoscaling is enabled. This pipeline is receiving recommendations for resources allocated per worker.
- Vertical Autoscaling update triggered to change per worker memory limit for pool from X GiB to Y GiB.
You can read more about these logs in this section.
Additionally you can visually monitor Vertical Autoscaling by looking at worker capacity under the ‘Max worker memory utilization’ chart in Dataflow metrics UI.
Following is a chart for a Dataflow worker that Vertically Autoscaled. We see three Vertical Autoscaling events for this job. Whenever the memory used was close to memory capacity, Vertical Autoscaling triggered and scaled up the worker memory capacity.

Summary
- Try Vertical Autoscaling for your streaming jobs on Dataflow Prime for improved resource optimization and cost savings.
- There is no code change required to run your existing Apache Beam pipeline on Dataflow Prime.
- There is no additional cost associated with using Vertical Autoscaling. Dataflow Prime jobs continue to be billed based on the resources it consumes.
By: Zeeshan Khan (Product Manager) and Zach Zimmerman (Software Engineer)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!






