
Businesses safely and securely bring us their data for enrichment and use the insights gained to deliver better customer experiences and generate more valuable business outcomes. Our fully interoperable and neutral infrastructure delivers end-to-end addressability for the world’s top brands, agencies, and publishers. Our platforms are designed to handle the variability and surge of the workload and guarantee service-level agreements (SLAs) to businesses.
From our partners:
We process petabytes of batch and streaming data daily. We ingest, process (join and enhance), and distribute this data. We receive and distribute data from thousands of partners and customers on a daily basis. We maintain the world’s largest and most accurate identity graph and work with more than 50 leading demand-side and supply-side platforms.
Our decision to migrate to Google Cloud and Dataproc
As an early adopter of Apache Hadoop, we had a single on-prem production managed Hadoop cluster that was used to store all of LiveRamp’s persistent data (HDFS) and run the Hadoop jobs that make up our data pipeline (YARN). The cluster consisted of around 2500 physical machines with a total of 30PB or raw storage, ~90,000 vcores, and ~300TB of memory. Engineering teams managed and ran multiple MapReduce jobs on these clusters.
The sheer volume of applications that LiveRamp ran on this cluster caused frequent resource contention issues, not to mention potentially widespread outages if an application was tuned improperly. Our business was scaling and we were running into constraints related to data center space and power in our on-premises environment. These constraints restricted our ability to meet our business objectives so a strategic decision was made to leverage elastic environments and migrate to the cloud. The decision required financial analysis and a detailed understanding of the available options, from do-it-yourself and vendor-managed distributions to leveraging cloud-managed services.
LiveRamp’s target architecture
We ultimately chose Google Cloud and Dataproc, a managed service for Hadoop, Spark, and other big data frameworks. During the migration we made a few fundamental changes to our Hadoop infrastructure:
- Instead of 1 large persistent cluster managed by a central team, we have decentralized the cluster ownership to individual teams. This gave the teams flexibility to recreate, perform upgrades or change configurations as they see fit. This also gives us better cost attribution, less blast radius for errors, and less chance that – a rogue job from one team will impact the rest of the workloads.
- Persistent data is no longer stored in HDFS on the clusters, it is in Google Cloud Storage, which, conveniently, served as a drop in replacement, as GCS is compatible with all the same APIs as HDFS. This means we can delete all the virtual machines that are part of the cluster without losing any data.
- Introduced autoscaling clusters to control compute cost, and to dramatically decrease request latency. On premise you’re paying for the machines so you might as well use them. Cloud compute is elastic so you want to burst when there is demand and scale down when you can.
For example, one of our teams runs about 100,000 daily Spark jobs on 12 Dataproc clusters that each independently scale up to 1000 VMs. This gives that team a current peak capacity of about 256,000 cores. Because the team is bound to its own GCP Project inside of a GCP Organization, the cost attributed to that team is now very easy to report. The team uses architecture represented below to distribute the jobs across the clusters. This architecture allows them to bin similar workloads together so that they can be optimized together. Below is the logical architecture of the above workload:
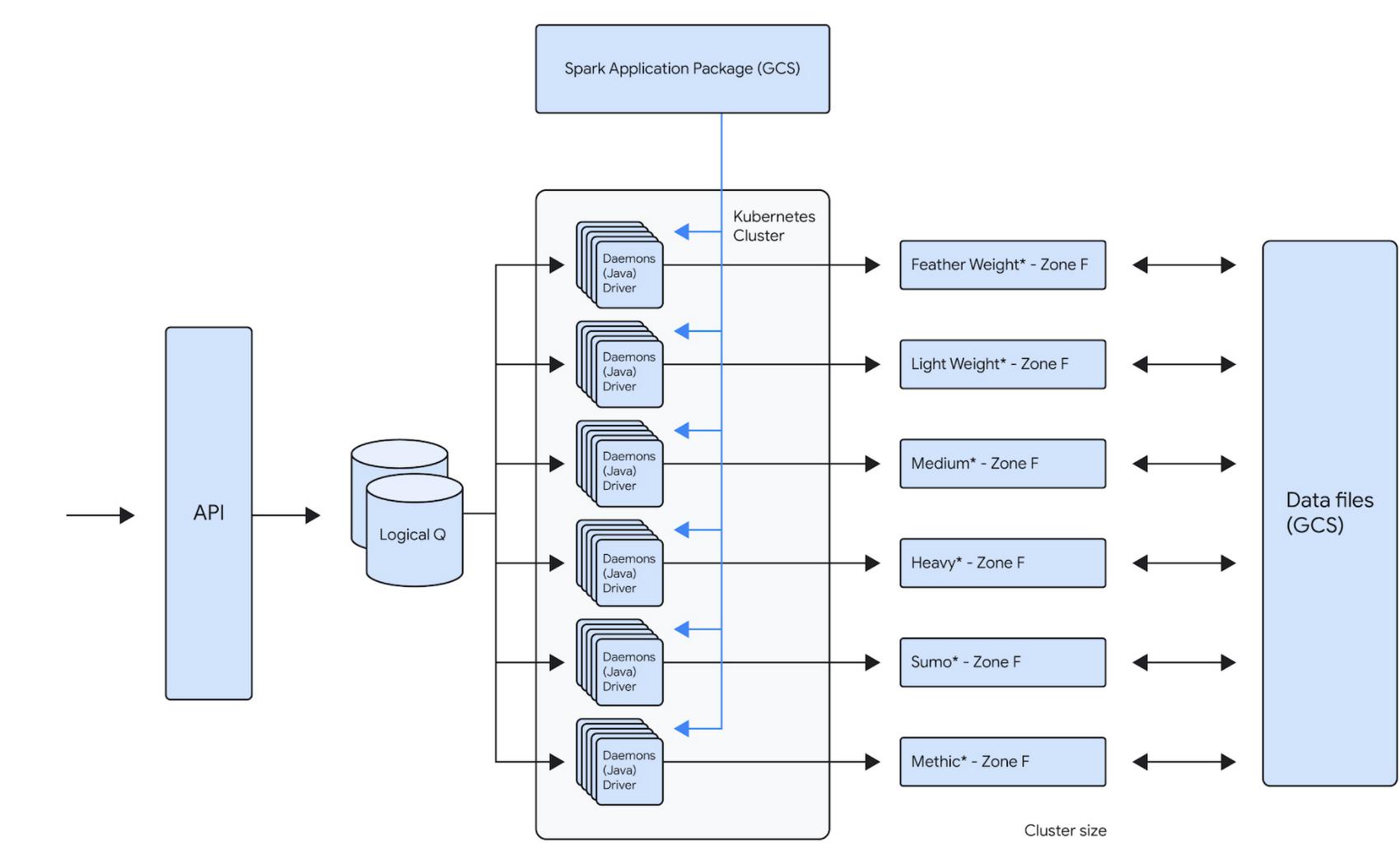
There will be a blog post in future that will talk about this workload in detail.
Our approach
Overall migration and post migration stabilization/optimization of the largest of our workloads took us about several years to complete. We broadly broke down the migration into multiple phases.
Initial Proof-Of-Concept
When analyzing solutions for cloud-hosted big data services, any product had to meet our clear acceptance criteria:
1. Cost: Dataproc is not particularly expensive compared to similar alternatives, but our discount with the existing managed Hadoop partner made it expensive. We have initially accepted that the cost would remain the same. We did see cost benefits post migration, after several rounds of optimizations.
2. Features: Some key features (compared to current state) that we were looking for are built-in autoscaler, ease of creating/updating/deleting clusters, managed big data technologies etc.
3. Integration with GCP: As we had already decided to move other LiveRamp-owned services to GCP, a big data platform with robust integration with GCP was a must. Basically, we’d like to be able to leverage GCP features without a lot of effort on our end (custom vms, preemptible vms, etc).
4. Performance: Cluster creation, deletion, scale up, and scale down should be fast. This will allow teams to iterate and react quickly. These are some rough estimates of how fast the cluster operations should be:
- Cluster creation: <15 minutes
- Cluster Deletion: <15 minutes
- Adding 50 nodes: <20 minutes
- Removing 200 nodes: <10 minutes
5. Reliability: Bug free and low downtime software that has concrete SLAs on clusters and a strong commitment to the correct functioning of all of its features.
An initial prototype to better understand Dataproc and Google Cloud helped us prove that target technologies and architecture will give us reliability and cost improvements. This also fed into our decisions around target architecture. This was then reviewed by the Google team before we embarked on the migration journey.
Overall migration
Terraform module
Our ultimate goal is to create self-service tooling that allows our data engineers to deploy infrastructure as easily and safely as possible. After defining some best practices around cluster creation and configuration, the central team’s first step was to build a terraform module that can be used by all the teams to create their own clusters. This module will create a dataproc cluster along with all supporting buckets, pods and datadog monitors:
- A dataproc cluster autoscaling policy that can be customized
- A dataproc cluster with LiveRamp defaults preconfigured
- Sidecar applications for recording job metrics from the job history server and for monitoring the cluster health
- Pre configured datadog cluster health monitors for alerting
This Terraform module is also composed of multiple supporting modules underneath. This allows users to call the supporting modules directly in your project terraform as well if such a need arises. The module can be used to create a cluster by just setting the parameters like project id, path to application source (Spark or Map/Reduce), subnet, VM instance type, auto scaling policy etc.
Workload migration
Based on our analysis of Dataproc, discussions with GCP team and the POC, we used following criteria:
- We prioritized applications that can use preemptibles to achieve cost parity to our existing workloads
- We prioritized some of our smaller workloads initially to build momentum within the organization. For example, we left the single workload that accounted for ~40% of our overall batch volume to the end, after we had gained enough experience as an organization.
- We combined the migration to Spark along with the migration to Dataproc. This has initially resulted in some extra dev work but helped reduce the effort for testing and other activities.
Our initial approach was to lift and shift from existing managed providers and Map/Reduce to Dataproc and Spark. We then later focused on optimizing the workloads for cost and reliability.
What’s working well
Cost Attribution
As is true with any business, it’s important to know where your cost centers are. Moving from a single cluster, made opaque by the number of teams loading work onto it, to GCP’s Organization/Project structure has made cost reporting very simple. The tool breaks down cost by project, but also allows us to attribute cost to a single cluster via tagging. As we sometimes deploy a single application to a cluster, this helps us to make strategic decisions on cost optimizations at an application level very easily.
Flexibility
The programmatic nature of deploying Hadoop clusters in a cloud like GCP dramatically reduces the time and effort involved in making infrastructure changes. LiveRamp’s use of a self-service Terraform module means that a data engineering team can very quickly iterate on cluster configurations. This allows a team to create a cluster that is best for their application while also adhering to our security and health monitoring standards. We also get all the benefits of infrastructure as code: highly complicated infrastructure state is version controlled and can be easily recreated and modified in a safe way.
Support
When our teams face issues with services that run on Dataproc, the GCP team is always quick to respond. They work very closely with LiveRamp to develop new features for our needs. They proactively provide LiveRamp with preview access to new features that help LiveRamp to stay ahead of the curve in the Data Industry.
Cost Savings
We have achieved around 30% cost savings in certain clusters by achieving the right balance between on-demand and PVMs. The cost savings were a result of our engineers building efficient A/B testing frameworks that helped us run the clusters/jobs in several configurations to arrive at the most reliable, maintainable and cost efficient configuration. Also, one of the applications is now 10x + faster.
Five lessons learned
Migration was a successful exercise that took about six months to complete, across all our teams and applications. While many aspects went really well, we also learned a few things along the way that we hope will help you when planning your own migration journey.
1. Benchmark, benchmark, benchmark
It’s always a good idea to benchmark the current platform against the future platform to compare costs and performance. On-premises environments have a fixed capacity, while cloud platforms can scale to meet workload needs. Therefore, it’s essential to ensure that the current behavior of the key workload is clearly understood before the migration.
2. Focus on one thing at a time
We initially focused on reliability while remaining cost-neutral during the migration process, and then focused on cost optimization post-migration. Google teams were very helpful and instrumental in identifying cost optimization opportunities.
3. Be aware of alpha and beta products
Although there usually aren’t any guarantees of a final feature set when it comes to pre-released products, you can still get a sense of their stability and create a partnership if you have a specific use case. In our specific use case, Enhanced Flexibility Mode was in alpha stage in April 2019, beta in August 2020, and released in July 2021. Therefore, it was helpful to check in on the product offering and understand its level of stability so we could carry out risk analysis and decide when we felt comfortable adopting it.
4. Think about quotas
Our Dataproc clusters could support much higher node counts than was possible with our previous vendor. This meant we often had to increase IP space and change quotas, especially as we tried out new VM and disk configurations.
5. Preemptable and committed use discounts (CUDs)
CUDs make compute less expensive while preemptables make compute significantly less expensive. However, preemptibles don’t count against your CUD purchases, so make sure you understand the impact on your CUD utilization when you start to migrate to preemptables.
We hope these lessons will help you in your Data Cloud journey.
By: Mithun Bondugula (Sr Engineering Manager, LiveRamp)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!






