Having lots of images residing in your container registry can become a noticeable issue while dealing with CI/CD pipelines for modern cloud-native applications delivered to Kubernetes. If you don’t want to have an overfilled registry (and to pay for this uselessly occupied space), you need to understand which images won’t be used anymore.
What are the criteria to find them and why the registries simply can’t be aware of them? Here is our journey on understanding and solving this problem in a universal way. While the practical part of our solution is revealed in the context of a specific Open Source tool (werf), the same approach can be applied to your own case and tooling.
From our partners:
Introduction
With time, the number of images in the container registry can grow substantially, taking up more and more space and costing you a fortune. In order to regulate, limit, or sustain acceptable grows rates in the registry space, you most likely can:
- use a fixed number of tags for images;
- clean up images somehow.
The first method works only for small teams. If the permanent tags such as latest, main, test, boris, and so on, meet the requirements of the developers, the registry will not grow in size, and you can forget about cleaning it for a long time. This is because all outdated images will be rewritten eventually, and you do not have to cleanup anything manually (the regular garbage collector will take care of any remnants).
Still, this approach severely limits the development process and is rarely used in CI/CD of modern applications. Automation has become an integral part of the development process. It allows you to test, deploy, and deliver exciting new features to users much faster. For example, a CI pipeline is automatically created in all our projects after each commit. As part of a CI pipeline, we build and test an image, deploy it to various Kubernetes environments (tiers) for debugging and additional testing. If everything is fine, then these changes reach the end user. And it is no longer a rocket science — after all, if you are reading this article, you probably do this as well.
Since debugging and implementing new functionality are carried out simultaneously, and there can be several releases per day, the development process involves a large number of commits that lead to a high number of images in the registry. Consequently, we need to find a way to cleanup unused (no longer relevant) images from the registry.
But how do we know if the image is relevant?
Criteria of the relevance of an image
In most cases, the criteria of the relevance are the following:
1. The first (the most obvious and the most important) type of images we need is those currently in use in Kubernetes. Removing these images can lead to production downtime (for example, these images may be needed to create new replicas) or wipe out all of the debugging efforts of the team in some environment. (This is why we have actually created this Prometheus exporter to monitor missing images in Kubernetes clusters).
2. The second (less obvious but still critical and operation-related) type is images required to perform a rollback in case of severe issues with the current version. For example, in the case of Helm, these are images that are used in saved versions of the release. (As a side note, Helm keeps 256 revisions by default; it is a large number, and you most likely do not need all these versions anyway). After all, we keep all these different versions in our development process because we want to use them for rollback, among other things.
3. Another type is all about developers’ demands: we need all images that are somehow related to their ongoing activities. For example, if we think about PRs it makes sense to keep an image linked to the last commit as well as an image linked to the previous one. This way, the developer can quickly roll back changes and analyze them.
4. The last type includes images that match specific versions of an application, i.e. represent a final product: v1.0.0, 20.04.01, sierra, and so on.
NB: The criteria above were devised based on our experience in collaborating with dozens of developer teams from a variety of companies. However, these criteria may vary depending on the peculiarities of the development process and the infrastructure used (e.g., Kubernetes isn’t used).
Existing registries and how they meet these criteria
Popular container registry solutions have their built-in policies for cleaning up images. They allow you to set conditions when the tag should be removed from the registry. However, these rules are usually limited to specifying names, creation time, and the number of tags*.
* Depending on the specific implementation of the container registry. We analyzed the following solutions: Azure CR, Docker Hub, ECR, GCR, GitHub Packages, GitLab Container Registry, Harbor Registry, JFrog Artifactory, Quay.io (as of September 2020).
This set of parameters is sufficient to select images matching the fourth criterion, namely, those that are linked to specific versions of an application. However, you have to make compromises in order to somehow meet three remaining criteria — in a more strict or relaxed manner, depending on your expectations and financial capacities.
For example, you can modify workflows within development teams to match the third, developers-related, type of images: to introduce tailored naming of images, maintain specific allow lists, or arrange internal agreements between team members. But you’ll have to automate it in the end. And if the available solutions are not flexible enough, you will have to devise your own!
A similar situation takes place for the other two criteria (#1 and #2): they cannot be met without obtaining the data from the external system (Kubernetes in our case) where applications are being deployed.
Git workflow illustration
Imagine here is your full Git workflow:
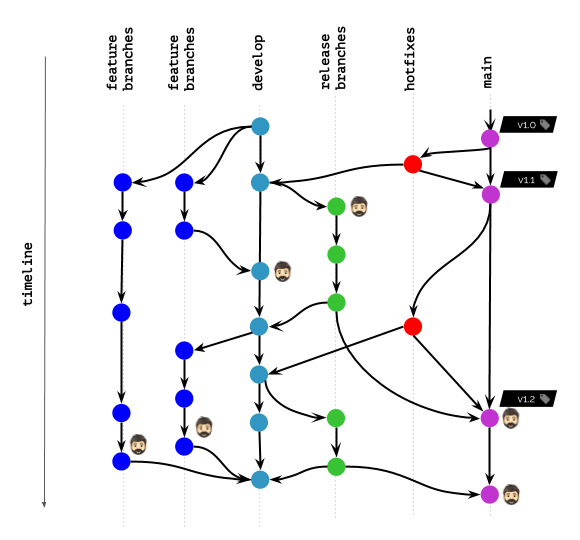
In a picture above, we’ve used a man’s head icon to mark all images that are currently deployed in Kubernetes for any kind of users (end users, testers, managers, etc.) or are in use by developers (for debugging & other reasons).
What will happen if your cleanup policies allow you to keep images by specific tags’ names only?

Well, it’s definitely an undesired case.
But what will happen if your policies allow you to keep images by specific time frame / last N commits only?
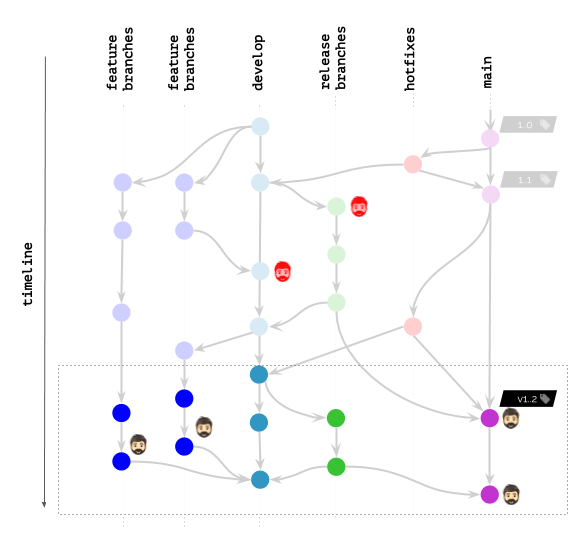
This looks much better. However, it is far from being perfect! For example, there still are some developers who need other images available (or even deployed to K8s) for debugging purposes.
To summarize the current market situation: existing container registry solutions do not offer sufficient flexibility when it comes to cleaning up images. The main reason for this is that they are unable to interact with the outside world. As a result, teams needing such flexibility are forced to implement the image deletion “from outside,” using workarounds with Docker Registry API (or an API of the specific registry implementation).
That is why we tried to find a universal solution that would automate the process of image cleanup for all teams and all kinds of container registries…
Our way to universal image cleanup
But why do we need it at all? The thing is that we are not a specific team of developers, but the business that supports a great diversity of such teams, helping them to solve CI/CD issues comprehensively and practically. And the werf Open Source tool is a prominent driver of this process. werf’s remarkable feature is that it monitors CD processes throughout all stages: from build to deploy.
Pushing images to the registry* (immediately after they are built) is one of the obvious functions of such a tool. Since all images have to be stored, here comes a natural responsibility to clean them up somehow. That’s why we come up with our approach to this problem that meets all four criteria listed above.
* Registry users face the same problems even though the registries themselves can be of different kinds (Docker Registry, GitLab Container Registry, Harbor, etc.). In our case, the universal solution is not tied up to the specific registry implementation since it runs outside of the registry, and its behavior is identical in all implementations.
While we use werf in our example, we hope that other teams with similar difficulties will find our approach helpful and informative.
So, we moved to an external implementation of our cleanup mechanism instead of what was built in container registries. And our first step towards it was using Docker Registry API to reimplement the same basic policies based on the number of tags and their creation date (discussed above). They were extended with a special allow list based on images deployed in Kubernetes. To make it, we merely cycled through all deployed resources using Kubernetes API and got a list of associated images. When we have this list, we’ll never clean these images from our registry.
This rather trivial solution solved the most critical issue (criterion 1). Still, it was only the beginning of our journey to the improved cleanup mechanism. The next — and much more intriguing — step was our decision to link images being published to the Git history.
Tagging schemes
At first, we chose an approach in which the final image contains all the information required for cleaning and introduced tagging schemes. When publishing an image, the user picked a preferred tagging option (git-branch, git-commit, or git-tag) and used the corresponding value. In CI systems these values were assigned automatically based on environment variables. Basically, the final image was linked to a specific Git object (branch/commit/tag) and stored the data required for cleanup in labels.
This approach resulted in a set of policies that allowed us to use Git as a single source of truth:
- When deleting Git branch/tag, the associated images in the registry were deleted automatically.
- We could control the number of images linked to Git tags/commits by changing the number of tags in the preferred tagging scheme and by setting the maximum number of days since the associated commit was created.
Overall, this implementation suited our needs, but soon we were faced with a new challenge. Using Git-based tagging schemes brought us several shortcomings — just enough to reconsider this approach. (The detailed description of these pitfalls is beyond the scope of this article; you can learn more about them here). Therefore, switching to a more efficient tagging strategy, content-based tagging, led us to change the way we clean container images.
New algorithm
What was the technical reason for that? When the content-based tagging strategy is used, each tag can be linked to multiple commits in Git. Thus, you can’t rely on the commit alone anymore when you choose images during your cleanup process.
In our new cleanup algorithm, we have decided to abandon tagging schemes altogether and base the process on meta-images. Each meta-image contains:
- the commit within which the image has been published (that said, it does not matter whether the image was added, changed, or remained the same in the container registry);
- our internal identifier that corresponds to the image built.
In other words, we linked published tags to commits in Git.
Final configuration and general algorithm
The user can now use various policies for selecting relevant images when configuring the cleanup. Each policy is defined by:
- a set of references, i.e., Git tags or Git branches that are used to find all needed images;
- the limit of the relevant images for each reference from the set.
Here is what the default policy configuration looks now:
cleanup:
keepPolicies:
- references:
tag: /.*/
limit:
last: 10
- references:
branch: /.*/
limit:
last: 10
in: 168h
operator: And
imagesPerReference:
last: 2
in: 168h
operator: And
- references:
branch: /^(main|staging|production)$/
imagesPerReference:
last: 10
The above configuration defines three policies that correspond to the following rules:
- Keep images for the 10 latest Git tags (by their creation date).
- Keep no more than two images published over the last week for no more than 10 branches active in the last week.
- Keep 10 images for
main,staging, andproductionbranches.
The final algorithm includes the following steps:
- Getting manifests from the container registry.
- Excluding images used in Kubernetes (we have already pre-selected them by cycling through deployed resources via Kubernetes API).
- Scanning the Git history and excluding images based on the specified policies.
- Deleting the remaining images.
Coming back to our illustration, here is what we can do with werf now:
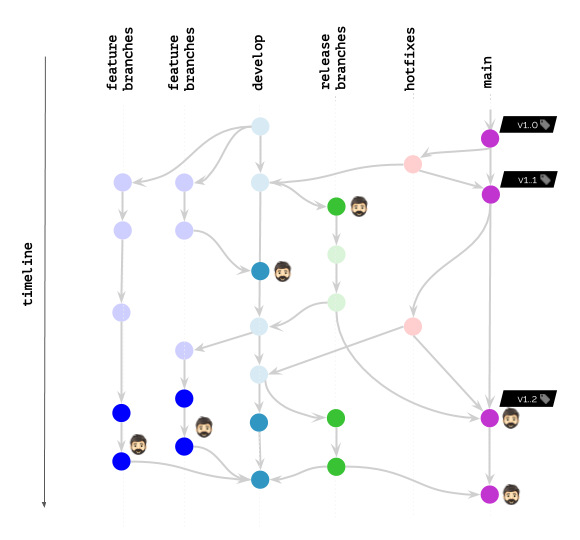
You can use more or less (depending on the preferred method of tagging images) similar approach to advanced image cleanup in other systems/using other tools even if you do not use werf. Just keep in mind the potential problems and try to find the best possible means in your stack to solve these problems smoothly.
We hope our lessons learned will help you take a fresh look at your particular case, leading to new ideas and insights.
Conclusion
- Sooner or later, most teams face the problem of their container registry getting enormously big and unmanageable (in a truly proper way).
- When looking for a solution, you first have to define the criteria for the image relevance.
- The capabilities of common container registries are limited with elementary cleanup algorithms that do not take into account the “outside world,” such as images used in Kubernetes as well as peculiarities of the team’s workflows.
- The flexible and efficient algorithm must be aware of CI/CD processes and should not limit itself to the Docker images data.
If you have any thoughts or questions on the problem discussed in this article, feel free to reach our developers via Twitter. To learn more about werf as a CI/CD tool, please check out its website.
By Alexey Igrychev
Source https://www.cncf.io/blog/2020/10/15/overcoming-the-challenges-of-cleaning-up-container-images/
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!