
Managing pipelines code
For any software system, developers need to be able to experiment and iterate on their code, while maintaining the stability of the production system. Using DevOps best practices, systems should be rigorously tested before being deployed, and deployments automated as much as possible. ML pipelines are no exception.
From our partners:
The typical process of executing an ML pipeline in Vertex AI looks like the following:
- Write your pipeline code in Python, using either the Kubeflow Pipelines or TFX DSL (domain-specific language)
- Compile your pipeline definition to JSON format using the KFP or TFX library
- Submit your compiled pipeline definition to the Vertex AI API to be executed immediately
How can we effectively package up these steps into a reliable production system, while giving ML practitioners the capabilities they need to experiment and iterate on their pipeline development?
Step 1: Writing pipeline code
As with any software system, you will want to use a version control system (such as git) to manage your source code. There are a couple of other aspects you may like to consider:
Code reuse
Kubeflow Pipelines are inherently modular, and you can use this to your advantage by reusing these components to accelerate the development of your ML pipelines. Be sure to check out all the existing components in the Google Cloud library and KFP library.
If you create custom KFP components, be sure to share them with your organization, perhaps by moving them to another repository where they can be versioned and referenced easily. Or, even better, contribute them to the open source community! Both the Google Cloud libraries and the Kubeflow Pipelines project welcome contributions of new or improved pipeline components.
Testing
As for any production system, you should set up automated testing to give you confidence in your system, particularly when you come to make changes later. Run unit tests for your custom components using a CI pipeline whenever you open a Pull Request (PR). Running an end-to-end test of your ML pipeline can be very time-consuming, so we don’t recommend that you set these tests to run every time you open a PR (or push a subsequent commit to an open PR). Instead, require manual approval to run these to run on an open PR, or alternatively run them only when you merge your code to be deployed into a dedicated test environment.
Step 2: Compiling your pipeline
As you would with other software systems, use a CI/CD pipeline (in Google Cloud Build, for example) to compile your ML pipelines, using the KFP or TFX library as appropriate. Once you have compiled your ML pipelines, you should publish those compiled pipelines into your environment (test/production). Since the Vertex AI SDK allows you to reference compiled pipelines that are stored in Google Cloud Storage (GCS), this is a great place to publish your compiled pipelines at the end of your CD pipeline. Alternatively, publish your compiled pipeline to Artifact Registry as a Vertex AI Pipeline template.
It’s also worth compiling your ML pipelines as part of your Pull Request checks (CI) – they are quick to compile so it’s an easy way to check for any syntax errors in your pipelines.
Step 3: Submit your compiled pipeline to the Vertex AI API
To submit your ML pipeline to be executed by Vertex, you will need to use the Google Cloud Vertex AI SDK (Python). As we want to execute ML pipelines that have been compiled as part of our CI/CD, you will need to separate your Python ML pipeline and compilation code from your “triggering” code that uses the Vertex AI SDK.
You may like your “triggering” code to be run on a fixed schedule (e.g. if you want to retrain your ML model every week), or perhaps instead in response to certain events (e.g. on the arrival of new data into BigQuery). Both Cloud Build and Cloud Functions will let you do this, with benefits to both approaches. You may like to use Cloud Build if you are already using Cloud Build for your CI/CD pipelines, however you will need to build a container yourself containing your “triggering” code. Using a Cloud Function, you can just deploy the code itself and GCP will take care of packaging it into a Cloud Function.
Both can be triggered using a fixed schedule (Cloud Scheduler + Pub/Sub), or triggered from a Pub/Sub event. Cloud Build can provide additional flexibility for event-based triggers, as you can interpret the Pub/Sub events using variable substitution in your Cloud Build triggers, rather than needing to interpret the Pub/Sub events in your Python code. In this way you can set up different Cloud Build triggers to kick off your ML pipeline in response to different events using the same Python code.
If you just want to schedule your Vertex AI pipelines, you can also use Datatonic’s open-source Terraform module to create Cloud Scheduler jobs that don’t require the use of a Cloud Function or other “triggering” code.
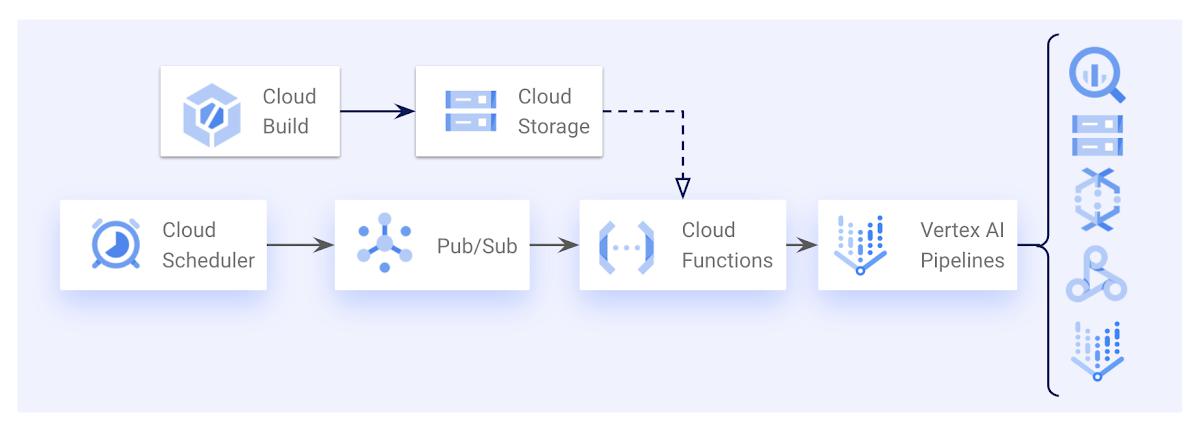
An example architecture for triggering Vertex AI Pipelines on a schedule using Cloud Scheduler, Pub/Sub, and a Cloud Function.
Introducing Vertex AI Quickstart Templates
In partnership with Google’s Vertex AI product team, Datatonic has developed an open-source template for taking your AI use cases to production with Vertex AI Pipelines. It incorporates:
- Example ML pipelines for training and batch scoring using XGBoost and Tensorflow frameworks (more frameworks to follow!)
- CI/CD pipelines (using Google Cloud Build) for running unit tests of KFP components, end-to-end pipeline tests, compiling and publishing ML pipelines into your environment
- Pipeline triggering code that can be easily deployed as a Google Cloud Function
- Example code for an Infrastructure-as-Code deployment using Terraform
- Make scripts to help accelerate the development cycle
The template can act as the starting point for your codebase to take a new ML use case from POC to production. Learn how Vodafone is using the templates to help slash the time from POC to production from 5 months to 4 weeks for their hundreds of Data Scientists across 13+ countries. To get started, check out the repository on GitHub and follow the instructions in the README.
If you’re new to Vertex AI and would like to learn more about it, check out the following resources to get started:
- Vertex AI overview
- Vertex AI Pipelines documentation
- Intro to Vertex AI Pipelines codelab
- Vertex AI Pipelines & ML Metadata codelab
Finally, we’d love your feedback. For feedback on Vertex AI, check out the Vertex AI support page. For feedback on the pipeline templates, please file an issue in the GitHub repository. And if you’ve got comments on this blog post, feel free to reach us.
Special thanks to Sara Robinson for sharing this great opportunity.
By: Ivan Nardini (Customer Engineer) and Jonny Browning (Principal MLOps Engineer at Datatonic)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







